Clear Sky Science · ar
التجميع الهرمي متعدد الطبقات والانتباه الذاتي لاكتشاف الانهيارات الأرضية باستخدام محولات الرؤية
مراقبة المنحدرات من الفضاء
يمكن أن تضرب الانهيارات الأرضية فجأة وبقليل من التحذير، مدمرة مساكن، ومعيقة طرقاً، ومهددةً للأرواح. يعتمد العلماء حول العالم الآن على الأقمار الصناعية والطائرات بدون طيار لمراقبة المنحدرات غير المستقرة من الأعلى، لكن تحويل ملايين البكسلات إلى تحذيرات موثوقة يشكل تحدياً كبيراً. يعرض هذا المقال نهجاً جديداً في الذكاء الاصطناعي يقرأ صور الاستشعار عن بعد بشكل أكثر كفاءة ودقة، ما يساعد على رسم خرائط للأماكن التي انزلقت فيها الأرض بالفعل وأين لا تزال الخطر كامناً.
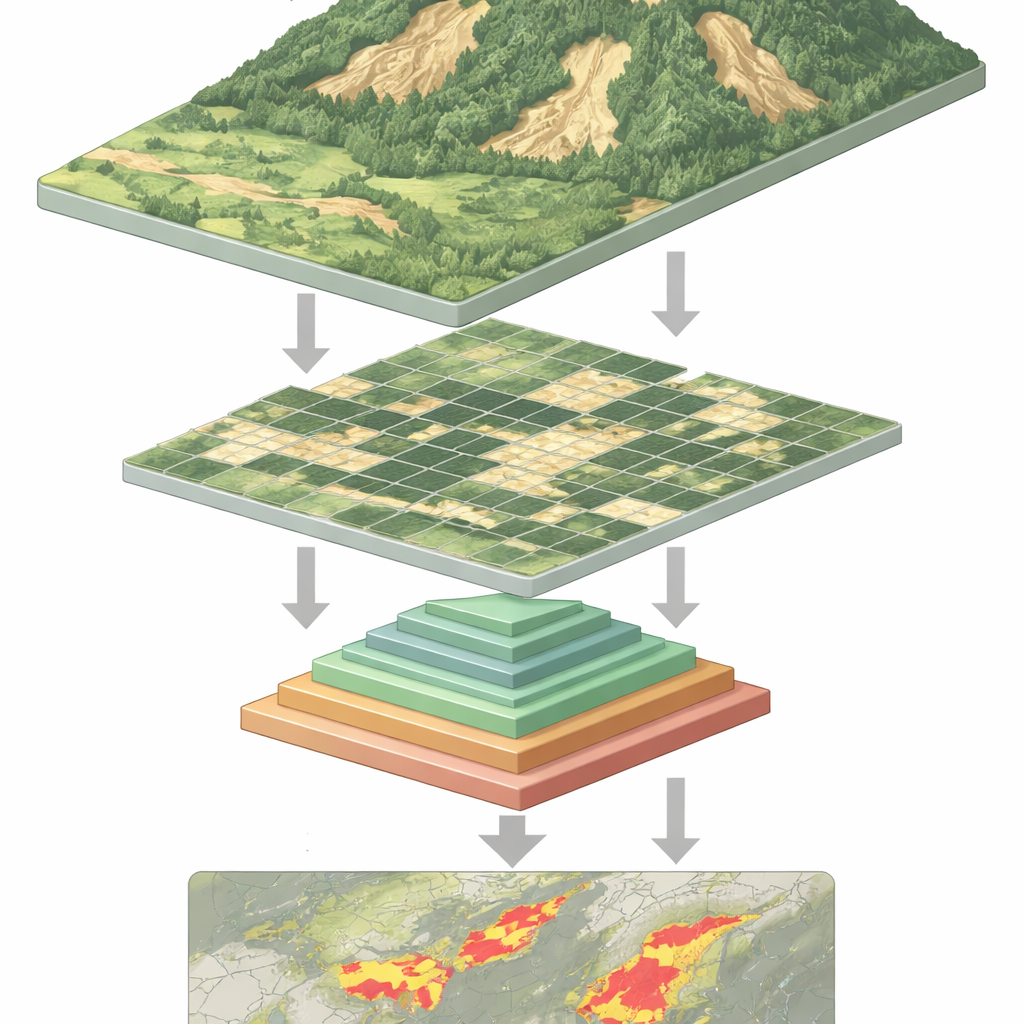
لماذا يصعب رصد الانهيارات الأرضية
من الفضاء، قد تبدو الانهيارات الأرضية الحديثة كندبة شاحبة على تلة خضراء—لكن ليس دائماً. تأتي الانهيارات الأرضية بأحجام وأشكال متنوعة، وقد تكون مخفية جزئياً بأشجار أو ظلال، وغالباً ما تشبه التربة المكشوفة الناتجة عن الزراعة أو البناء. تواجه البرامج التقليدية، وحتى العديد من أنظمة التعلم العميق، صعوبة في التعامل مع هذا التنوع. الشبكات العصبية الالتفافية، والتي كانت العمود الفقري القديم للتعرّف على الصور، جيدة في الالتقاط المحلي للأنماط لكنها قد تفوت الإطار الأوسع للمنحدر. يمكن لنماذج "محولات الرؤية" الأحدث استيعاب هذا السياق الأوسع، لكنها تدفع ثمناً: لتحليل كل بقعة صغيرة في الصورة، يجب عليها معالجة تسلسلات بيانات طويلة جداً، ما يتطلب قدرة حاسوبية كبيرة ويبطئ الأداء.
تعليم الآلات الرؤية على مقاييس متعددة
يتناول البحث عنق الزجاجة هذا عبر البناء على محولات الرؤية مع استعارة فكرة ذكية من أعمال سابقة في معالجة الصور تُسمى التجميع الهرمي. الفكرة الأساسية هي أن المشهد ينبغي فهمه على عدة مقاييس في آن واحد: تفاصيل دقيقة مثل الشقوق أو حقول الحطام، وميزات متوسطة مثل منحدر زلق، وأنماط واسعة مثل انحدار التضاريس والمحيط العام. بدلاً من تصغير الصورة بخطوة تجميع واحدة، يقوم النموذج الجديد بإجراء عمليات تجميع متعددة بمقاييس مختلفة داخل المحول نفسه. تُكدس هذه النُسخ المجمعة مثل طبقات الهرم ثم تُدخَل في آلية الانتباه في النموذج، التي تقرر أي أجزاء من الصورة ينبغي أن تؤثر على بعضها البعض.
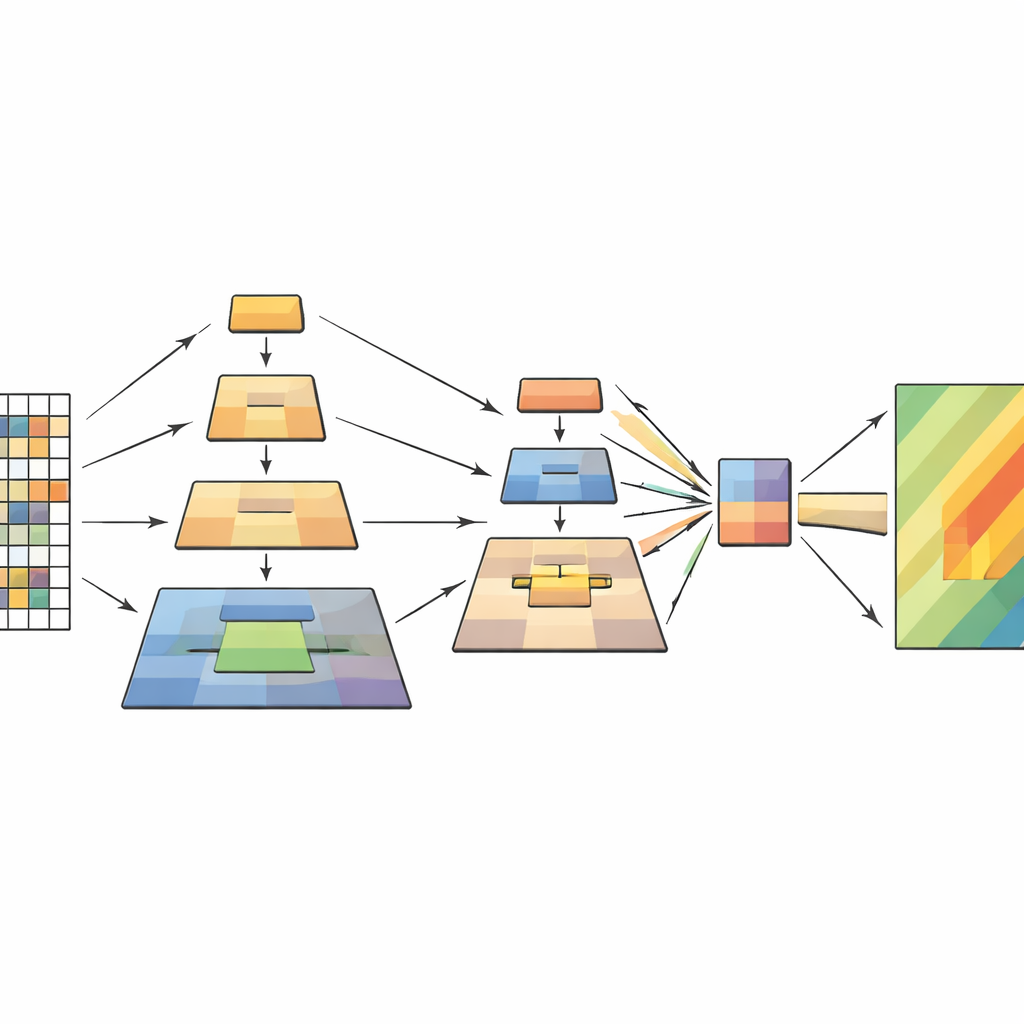
كيف يعمل النموذج الجديد داخلياً
تعالج الشبكة كل صورة استشعار عن بعد في أربع مراحل. أولاً، تقطع الصورة إلى رقع صغيرة وتحولها إلى شبكة من الرموز. مع تدفق البيانات إلى عمق أكبر، تُجمّع الرقع المجاورة وتتناقص دقة تمثيلها المكاني تدريجياً، مكونة هرمية من خرائط السمات. داخل كل مرحلة، ينشئ وحدة التجميع الهرمي متعدد الطبقات عدة رؤى مصغرة لتلك السمات ويجمعها في تسلسل أقصر وأكثر غنى. ثم تستخدم آلية الانتباه الصورة الأصلية كاستعلام—الأجزاء التي تسأل «ما المهم هنا؟»—بينما تُستخدم الرؤى المجمعة كمفاتيح وقيم—السياق المُستخلَص الذي يجيب. تعمل كتل التلافيف الخفيفة الإضافية على الحفاظ على الإحساس بالتركيب ثنائي الأبعاد، مما يساعد النموذج على البقاء حساساً للأشكال والحواف والملمس التي تميز مسارات الانهيارات الأرضية.
اختبار الطريقة
لمعرفة مدى فعالية هذا التصميم، درّبه المؤلفون واختبروه على مجموعة بيانات كبيرة ومفتوحة للانهيارات الأرضية جمعتها الأكاديمية الصينية للعلوم. تتضمن هذه المجموعة أكثر من عشرين ألف صورة مأخوذة من أقمار صناعية وطائرات بدون طيار، وتغطي مناطق وتضاريس وظروف تصوير متعددة. قورن النموذج الجديد بمنافسين أقوياء، من شبكات U-Net وDeepLab الكلاسيكية إلى أنظمة حديثة مبنية على المحولات مثل Swin Transformer ومكتشف انهيارات أرضية خفيف الوزن حديث اسمه BisDeNet. عبر مجموعة من معايير القياس القياسية—الدقة والاستدعاء ودرجة F1 ومؤشر التقاطع على الاتحاد والدقة العامة—تفوق المحول ذو التجميع الهرمي متعدد الطبقات باستمرار، محققاً زيادة في درجة F1 بمقدار 7.3 نقطة مئوية وزيادة في الدقة العامة بمقدار نقطتين مئويتين مقارنة بالبدائل الرائدة.
من الأرقام إلى المشاهد الحقيقية
بعيداً عن الأرقام الخام، فحص الباحثون توقعات النموذج بصرياً. وجدوا أنه يميل إلى التركيز على فواصل المنحدر، والندوب الممدودة، وملامس السطح المختلطة النموذجية لمسارات الانهيارات الأرضية. تحدث الأخطاء بشكل أساسي عندما تكون الصورة نفسها غامضة—مثل ضفاف الأنهار، أو التربة المكشوفة، أو الانزلاقات الصغيرة ذات الحدود الشاحبة—بدلاً من أخطاء منهجية واضحة. تُظهر الاختبارات على عدة مجموعات بيانات إضافية من أماكن مثل نيبال وبيجي وتانغجياشان أن الطريقة تتكيف بشكل معقول مع مناظر طبيعية مختلفة، مما يوحي بأنها تلتقط سمات عامة للانهيارات بدلاً من خصوصيات منطقة واحدة.
ماذا يعني هذا لمنحدرات أكثر أماناً
بعبارة بسيطة، يوضح البحث كيف نجعل نوعاً قوياً من الذكاء الاصطناعي "ينظر" إلى المنحدرات بكفاءة وذكاء أكبر. من خلال السماح للنموذج بتجميع المعلومات على عدة مقاييس داخل آلية الانتباه الأساسية، يقلل العبء الحاسوبي بينما يحافظ على الصورة الكبيرة والتفاصيل الدقيقة اللازمة لتحديد الانهيارات الأرضية. النتيجة هي أداة أسرع وأكثر دقة لتحويل تدفقات الصور الفضائية وصور الطائرات بدون طيار إلى خرائط للأراضي غير المستقرة. يمكن أن تدعم مثل هذه الخرائط تقييم الأضرار بعد الكوارث، والمراقبة طويلة الأمد للمخاطر، ورصد التغيرات، مما يمنح المخططين ومديري الطوارئ رؤية أوضح للأماكن التي تحركت فيها الأرض بالفعل—وأين قد تتحرك لاحقاً.
الاستشهاد: Sreelakshmi, S., Chandra, S.S.V., Ali, D. et al. Multilayer pyramid pooling self-attention for landslide detection using vision transformers. Sci Rep 16, 14011 (2026). https://doi.org/10.1038/s41598-026-44425-4
الكلمات المفتاحية: اكتشاف الانهيارات الأرضية, الاستشعار عن بعد, محولات الرؤية, التجميع الهرمي, التجزئة الدلالية