Clear Sky Science · fr
Auto-attention à regroupement pyramidal multi-couches pour la détection des glissements de terrain avec des vision transformers
Observer les flancs de collines depuis l'espace
Les glissements de terrain peuvent survenir sans grand préavis, détruire des habitations, bloquer des routes et mettre des vies en danger. Partout dans le monde, les chercheurs s'appuient désormais sur des satellites et des drones pour surveiller les versants instables depuis les airs, mais transformer des millions de pixels en alertes fiables reste un défi majeur. Cet article présente une nouvelle approche d'intelligence artificielle qui analyse les images de télédétection de manière plus efficace et plus précise, aidant à cartographier les zones déjà déstabilisées et celles où le danger subsiste.
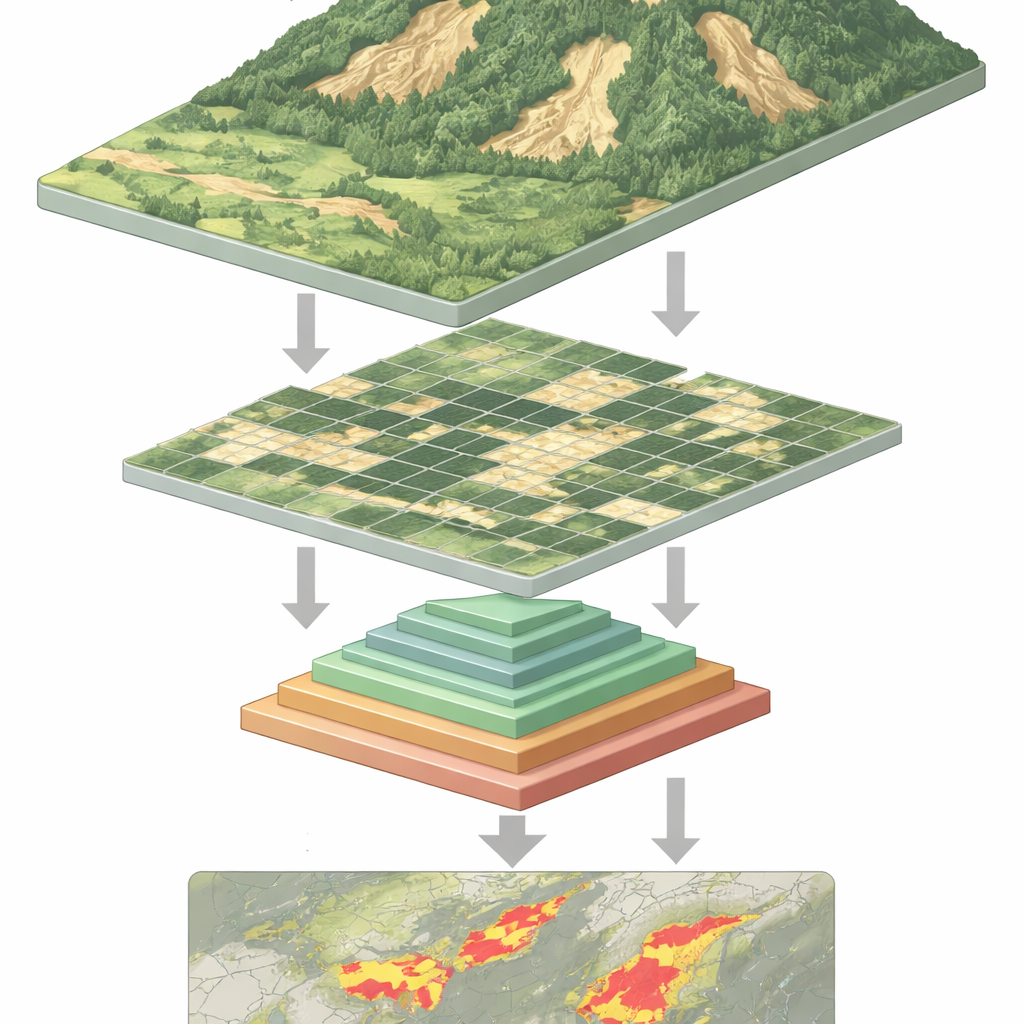
Pourquoi repérer les glissements est si difficile
Vu de l'espace, un glissement récent peut ressembler à une cicatrice pâle sur une colline verte—mais ce n'est pas systématique. Les glissements de terrain prennent de nombreuses tailles et formes, peuvent être partiellement cachés par la végétation ou les ombres, et ressemblent souvent à du sol nu issu de l'agriculture ou de travaux. Les méthodes classiques, et même beaucoup de systèmes d'apprentissage profond, peinent à composer avec cette diversité. Les réseaux convolutionnels, anciens piliers de la reconnaissance d'images, excellent pour détecter des motifs locaux mais peuvent manquer le contexte plus large d'un versant. Les modèles plus récents de type « vision transformer » captent mieux ce contexte étendu, mais au prix d'une lourde charge : pour analyser chaque petite portion d'une image, ils doivent traiter de très longues séquences de données, ce qui exige beaucoup de calculs et ralentit le processus.
Apprendre aux machines à voir à plusieurs échelles
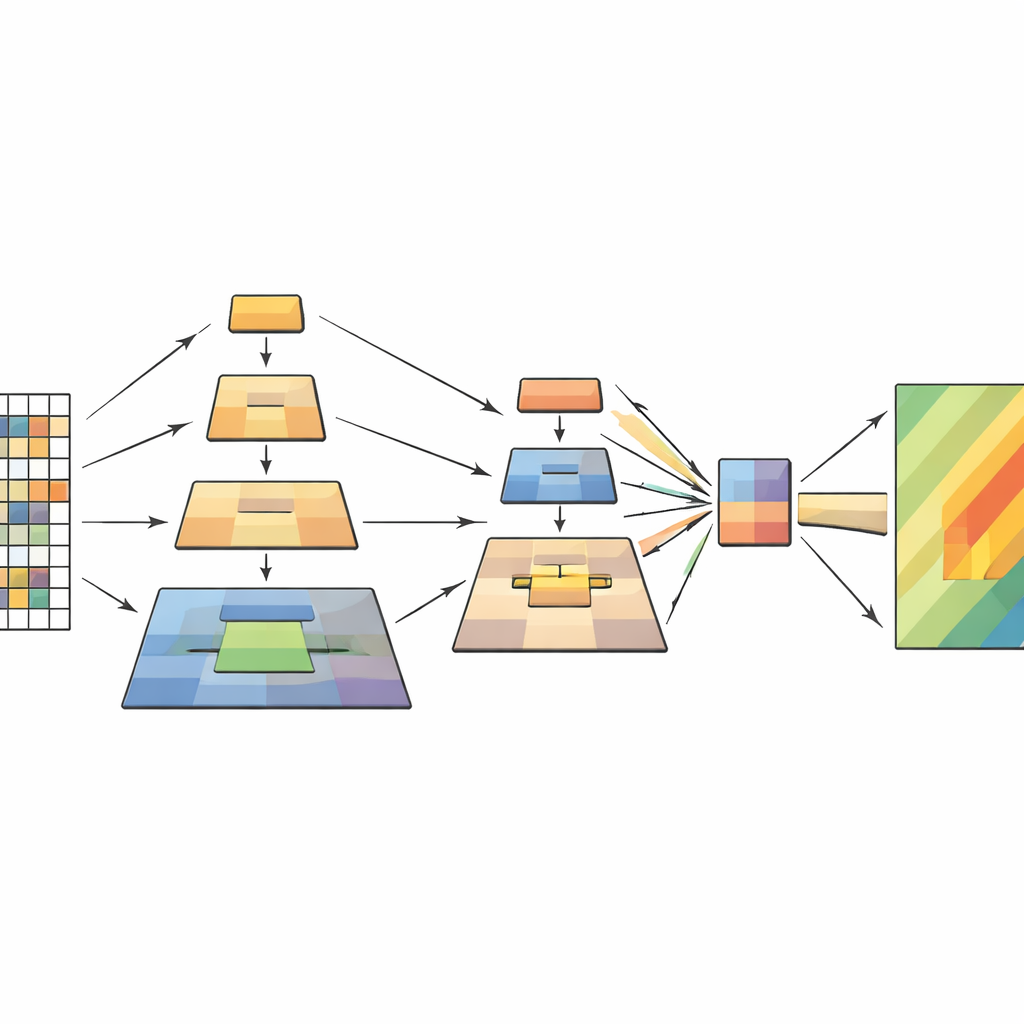
Cette étude s'attaque à ce goulet d'étranglement en s'appuyant sur les vision transformers tout en empruntant une idée astucieuse des travaux antérieurs en traitement d'image, appelée regroupement pyramidal. L'idée clé est qu'une scène doit être comprise à plusieurs échelles simultanément : de minuscules détails comme des fissures ou des champs de débris, des éléments moyens comme un versant en glissement, et des motifs larges comme la pente générale et son environnement. Plutôt que de réduire l'image par une seule opération de pooling, le nouveau modèle effectue plusieurs opérations de regroupement à différentes échelles à l'intérieur même du transformeur. Ces versions agrandies sont empilées comme des couches d'une pyramide puis injectées dans le mécanisme d'attention du modèle, qui décide quelles parties de l'image doivent s'influencer mutuellement.
Comment fonctionne le nouveau modèle en interne
Le réseau traite chaque image de télédétection en quatre étapes. D'abord, il découpe l'image en petites patches et les transforme en une grille de tokens. Au fur et à mesure que les données pénètrent plus profondément, les patches voisins sont regroupés et leur résolution spatiale diminue progressivement, formant une hiérarchie de cartes de caractéristiques. Dans chaque étape, le module de regroupement pyramidal multi-couches crée plusieurs vues sous-échantillonnées de ces caractéristiques et les combine en une séquence plus courte et plus riche. Le mécanisme d'attention utilise ensuite l'image d'origine comme requête—les éléments qui demandent « qu'est-ce qui compte ici ? »—et les vues regroupées comme clés et valeurs—le contexte distillé qui répond. Des blocs convolutionnels légers supplémentaires préservent la structure bidimensionnelle, aidant le modèle à rester sensible aux formes, aux contours et aux textures caractéristiques des glissements de terrain.
Éprouver la méthode
Pour évaluer l'efficacité de cette conception, les auteurs l'ont entraînée et testée sur un large jeu de données public de glissements de terrain assemblé par l'Académie chinoise des sciences. Cette collection comprend plus de vingt mille images issues de satellites et de drones, couvrant de nombreuses régions, terrains et conditions d'imagerie. Le nouveau modèle a été comparé à de solides concurrents, des réseaux classiques U-Net et DeepLab aux systèmes récents basés sur des transformeurs comme Swin Transformer, ainsi qu'à un détecteur de glissements léger récent appelé BisDeNet. Sur un ensemble d'indicateurs standard—précision, rappel, score F1, intersection sur union et exactitude globale—le transformeur à regroupement pyramidal multi-couches est arrivé systématiquement en tête, augmentant le score F1 de 7,3 points de pourcentage et l'exactitude globale de 2 points par rapport aux meilleures alternatives.
Des chiffres aux paysages réels
Au-delà des scores bruts, les chercheurs ont inspecté visuellement les prédictions du modèle. Ils ont constaté qu'il a tendance à se concentrer sur les cassures de pente, les cicatrices allongées et les textures de surface mixtes typiques des trajectoires de glissement. Les erreurs surviennent principalement là où l'imagerie elle-même est ambiguë—comme les berges de rivières, les sols exposés ou les petits glissements aux contours faibles—plutôt qu'en raison d'erreurs systématiques évidentes. Des tests sur plusieurs jeux de données supplémentaires provenant de lieux comme le Népal, Bijie et Tangjiashan montrent que la méthode s'adapte raisonnablement bien à différents paysages, suggérant qu'elle capture des signatures générales des glissements plutôt que des particularités d'une seule région.
Ce que cela signifie pour des pentes plus sûres
En termes simples, l'article montre comment faire « regarder » un puissant type d'IA les versants de manière plus efficace et plus intelligente. En permettant au modèle d'agréger de l'information à plusieurs échelles à l'intérieur de son mécanisme d'attention central, on réduit la charge computationnelle tout en conservant la vue d'ensemble et les détails fins nécessaires pour délimiter les glissements de terrain. Le résultat est un outil plus rapide et plus précis pour transformer des flux d'images satellites et de drones en cartographies des sols instables. De telles cartes peuvent soutenir les évaluations des dommages post-catastrophe, la surveillance des risques à long terme et la détection de changements, offrant aux planificateurs et aux gestionnaires d'urgence une vision plus claire des zones où la terre s'est déjà déplacée—et où elle pourrait encore bouger.
Citation: Sreelakshmi, S., Chandra, S.S.V., Ali, D. et al. Multilayer pyramid pooling self-attention for landslide detection using vision transformers. Sci Rep 16, 14011 (2026). https://doi.org/10.1038/s41598-026-44425-4
Mots-clés: détection des glissements de terrain, télédétection, vision transformers, regroupement pyramidal, segmentation sémantique