Clear Sky Science · pl
Wielowarstwowe piramidalne pooling i mechanizm self-attention do wykrywania osuwisk przy użyciu vision transformerów
Obserwowanie zboczy z kosmosu
Osuwiska mogą uderzyć bez ostrzeżenia, niszcząc domy, blokując drogi i zagrażając życiu. Na całym świecie naukowcy coraz częściej polegają na satelitach i dronach, by obserwować niestabilne stoki z góry, jednak przetworzenie milionów pikseli na wiarygodne ostrzeżenia to ogromne wyzwanie. Ten artykuł przedstawia nowe podejście sztucznej inteligencji, które czyta obrazy teledetekcyjne wydajniej i dokładniej, pomagając mapować miejsca, w których grunt już się osunął, oraz te, gdzie nadal czyha niebezpieczeństwo.
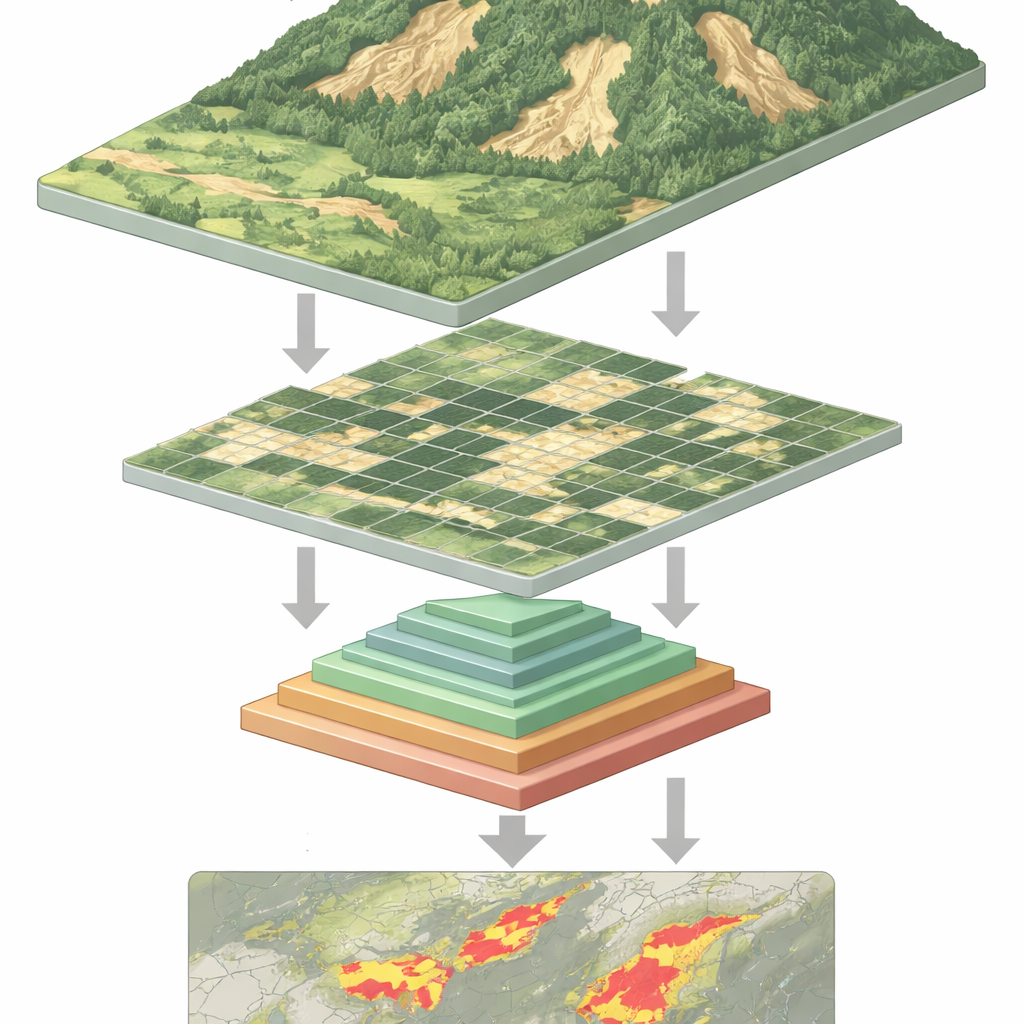
Dlaczego wykrywanie osuwisk jest tak trudne
Z kosmosu świeże osuwisko może wyglądać jak blady ślad na zielonym zboczu — ale nie zawsze. Osuwiska mają różne rozmiary i kształty, mogą być częściowo ukryte pod koronami drzew lub cieniami i często przypominają gołą ziemię po działalności rolniczej lub budowlanej. Tradycyjne programy komputerowe, a nawet wiele systemów głębokiego uczenia, ma problemy z taką różnorodnością. Konwolucyjne sieci neuronowe, wcześniejsze narzędzia rozpoznawania obrazów, dobrze wykrywają lokalne wzorce, lecz mogą nie uchwycić szerszego kontekstu stoku. Nowsze modele „vision transformer” potrafią objąć ten szerszy kontekst, ale płacą za to kosztem: aby analizować każdy drobny fragment obrazu, muszą operować na bardzo długich sekwencjach danych, co wymaga dużej mocy obliczeniowej i spowalnia działanie.
Nauczanie maszyn patrzenia na wielu skalach
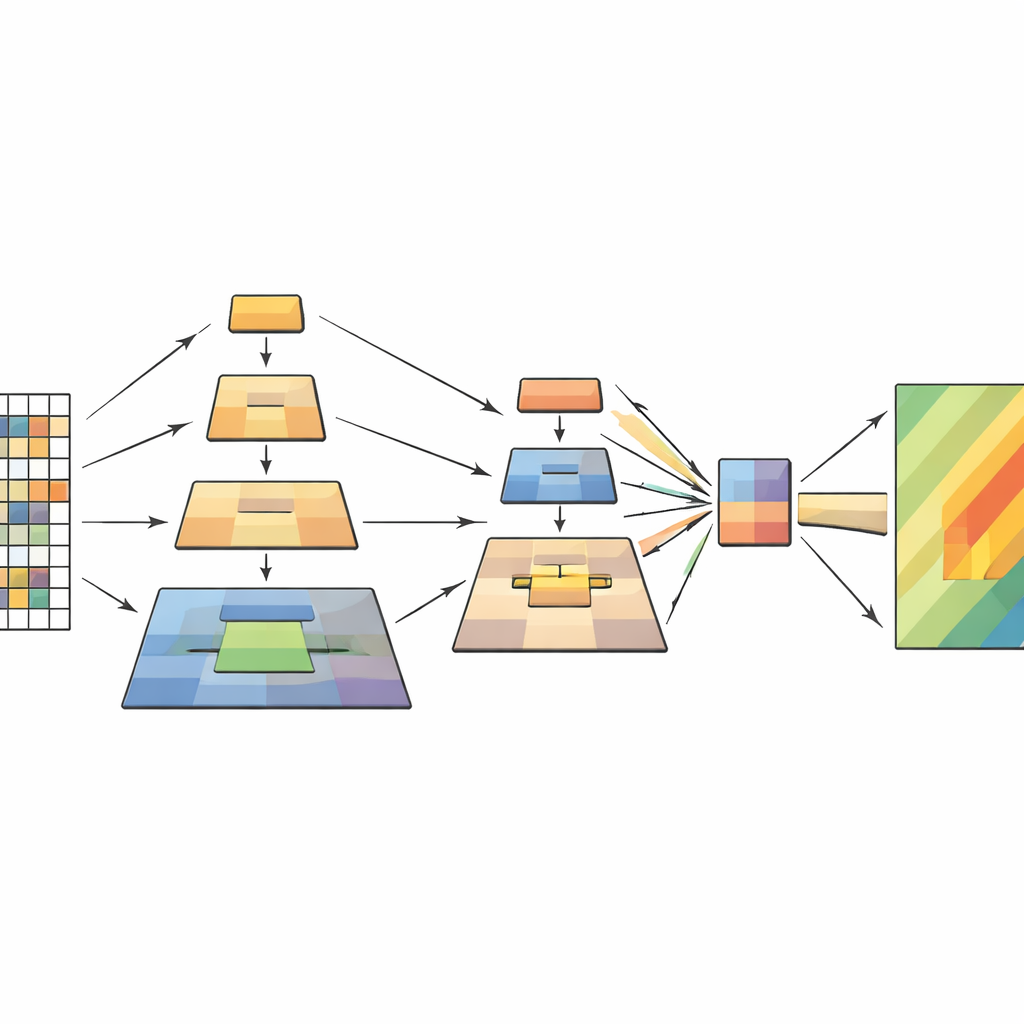
Badanie rozwiązuje to wąskie gardło, bazując na vision transformerach i wykorzystując sprytne rozwiązanie z wcześniejszych prac nad przetwarzaniem obrazów, zwane piramidalnym poolingiem. Kluczowa idea jest taka, że scenę należy rozumieć jednocześnie na kilku skalach: drobne detale jak pęknięcia czy pola rumowiska, średnie cechy jak zsuwające się zbocze oraz szerokie wzory obejmujące ogólny kąt nachylenia i otoczenie. Zamiast zmniejszać obraz pojedynczym krokiem poolingu, nowy model wykonuje kilka operacji poolingu na różnych skalach wewnątrz transformera. Tak uzyskane wersje obrazu układane są jak warstwy piramidy, a następnie przekazywane do mechanizmu attention modelu, który decyduje, które części obrazu powinny nawzajem na siebie wpływać.
Jak nowy model działa w środku
Sieć przetwarza każdy obraz teledetekcyjny w czterech etapach. Najpierw dzieli obraz na małe łatki i zamienia je w siatkę tokenów. W miarę jak dane przepływają głębiej, sąsiadujące łatki są grupowane, a ich rozdzielczość przestrzenna stopniowo maleje, tworząc hierarchię map cech. W ramach każdego etapu moduł wielowarstwowego piramidalnego poolingu tworzy kilka pomniejszonych widoków tych cech i łączy je w krótszą, bogatszą sekwencję. Mechanizm attention używa następnie oryginalnego obrazu jako zapytania — części, które pytają „co tu jest ważne?” — a puli widoków jako kluczy i wartości — skondensowanego kontekstu, który odpowiada. Dodatkowe lekkie bloki konwolucyjne zachowują dwuwymiarowy charakter danych, pomagając modelowi utrzymać czułość na kształty, krawędzie i tekstury charakterystyczne dla osuwisk.
Próba metody w praktyce
Aby ocenić skuteczność projektu, autorzy trenowali i testowali go na dużym, publicznym zbiorze danych o osuwiskach zgromadzonym przez Chińską Akademię Nauk. Kolekcja obejmuje ponad dwadzieścia tysięcy obrazów z satelitów i dronów, obejmujących różne regiony, ukształtowanie terenu i warunki obrazowania. Nowy model porównano z silnymi konkurentami, od klasycznych sieci U-Net i DeepLab po nowoczesne systemy oparte na transformerach, takie jak Swin Transformer, oraz niedawny lekki detektor osuwisk o nazwie BisDeNet. W szeregu standardowych miar — precyzji, czułości (recall), wyniku F1, współczynnika intersection-over-union i ogólnej dokładności — wielowarstwowy piramidalny transformer konsekwentnie wypadał lepiej, zwiększając wynik F1 o 7,3 punktu procentowego i ogólną dokładność o 2 punkty procentowe w porównaniu z najlepszymi alternatywami.
Z liczb do rzeczywistych krajobrazów
Ponad surowymi wynikami, badacze wizualnie przejrzeli przewidywania modelu. Stwierdzili, że model ma tendencję do koncentrowania się na przerwach w nachyleniu, wydłużonych bliznach i zmieszanych teksturach powierzchni typowych dla torów osuwisk. Błędy zdarzają się głównie tam, gdzie sama obrazografia jest niejednoznaczna — na przykład na brzegach rzek, odsłoniętej ziemi czy w przypadku drobnych zsuwów o słabo zarysowanych konturach — a nie z powodu oczywistych systematycznych pomyłek. Testy na kilku dodatkowych zbiorach danych z miejsc takich jak Nepal, Bijie i Tangjiashan pokazują, że metoda dostosowuje się całkiem dobrze do różnych krajobrazów, co sugeruje, że uchwyciła ogólne sygnatury osuwisk, a nie jedynie specyfikę jednego regionu.
Co to oznacza dla bezpieczniejszych stoków
Mówiąc prościej, artykuł pokazuje, jak sprawić, by potężny typ sztucznej inteligencji „patrzył” na zbocza wydajniej i mądrzej. Pozwalając modelowi na pooling informacji na kilku skalach wewnątrz jego podstawowego mechanizmu attention, zmniejsza się obciążenie obliczeniowe, przy jednoczesnym zachowaniu ogólnego obrazu i drobnych detali potrzebnych do wyznaczania osuwisk. Efektem jest szybsze i dokładniejsze narzędzie do przekształcania strumieni obrazów satelitarnych i z dronów w mapy niestabilnego gruntu. Takie mapy mogą wspierać oceny zniszczeń po katastrofach, długoterminowe monitorowanie zagrożeń i wykrywanie zmian, dając planistom i służbom ratunkowym wyraźniejszy obraz tego, gdzie ziemia już się poruszyła — i gdzie może poruszyć się następnym razem.
Cytowanie: Sreelakshmi, S., Chandra, S.S.V., Ali, D. et al. Multilayer pyramid pooling self-attention for landslide detection using vision transformers. Sci Rep 16, 14011 (2026). https://doi.org/10.1038/s41598-026-44425-4
Słowa kluczowe: wykrywanie osuwisk, teledetekcja, vision transformery, piramidalne pooling, segmentacja semantyczna