Clear Sky Science · tr
ModernBERT, Japon radyoloji raporlarındaki göğüs BT bulguları sınıflandırmasında geleneksel BERT’e göre daha verimli
Tıbbi raporların daha hızlı okunmasının önemi
Her gün hastaneler, görüntülerde doktorların gördüklerini anlatan binlerce radyoloji raporu üretir. Bu serbest metin notlarını yapılandırılmış bilgilere dönüştürmek araştırmaya, kalite kontrolüne ve hatta tanıyı destekleyen gelecekteki yapay zeka sistemlerine yardımcı olabilir. Ancak bilgisayarların önce dili “anlaması” gerekir; bu, uzman terimler, kısaltmalar ve İngilizce ifadelerin karışımı nedeniyle Japonca tıbbi yazımında özellikle zordur. Bu çalışma, daha yeni bir dil modeli olan ModernBERT’in, daha eski ve yaygın olarak kullanılan BERT modellerine kıyasla Japonca göğüs BT raporlarını doğruluktan ödün vermeden daha verimli okuyup okuyamadığını sorguluyor.
Bilgisayarlar görüntü raporlarını nasıl öğrenir
Modelleri adil şekilde karşılaştırmak için araştırmacılar somut bir göreve odaklandı: her göğüs BT raporu için akciğer nodülleri, amfizem veya plevral efüzyon gibi 18 olası bulgudan hangilerinin mevcut olduğunu belirlemek. Araştırmacılar, her biri uzmanlar tarafından etiketlenmiş 22.000’den fazla Japonca çevrilmiş göğüs BT raporu içeren CT‑RATE‑JPN adlı büyük bir halka açık veri setini kullandı. Raporların çoğu, standart bir BERT, tıbbi odaklı JMedRoBERTa ve ModernBERT olmak üzere üç modeli eğitmek ve ayarlamak için kullanıldı. Ayrı bir 150 raporluk küme ise her modelin doğru bulgular kombinasyonunu atama performansını test etti.
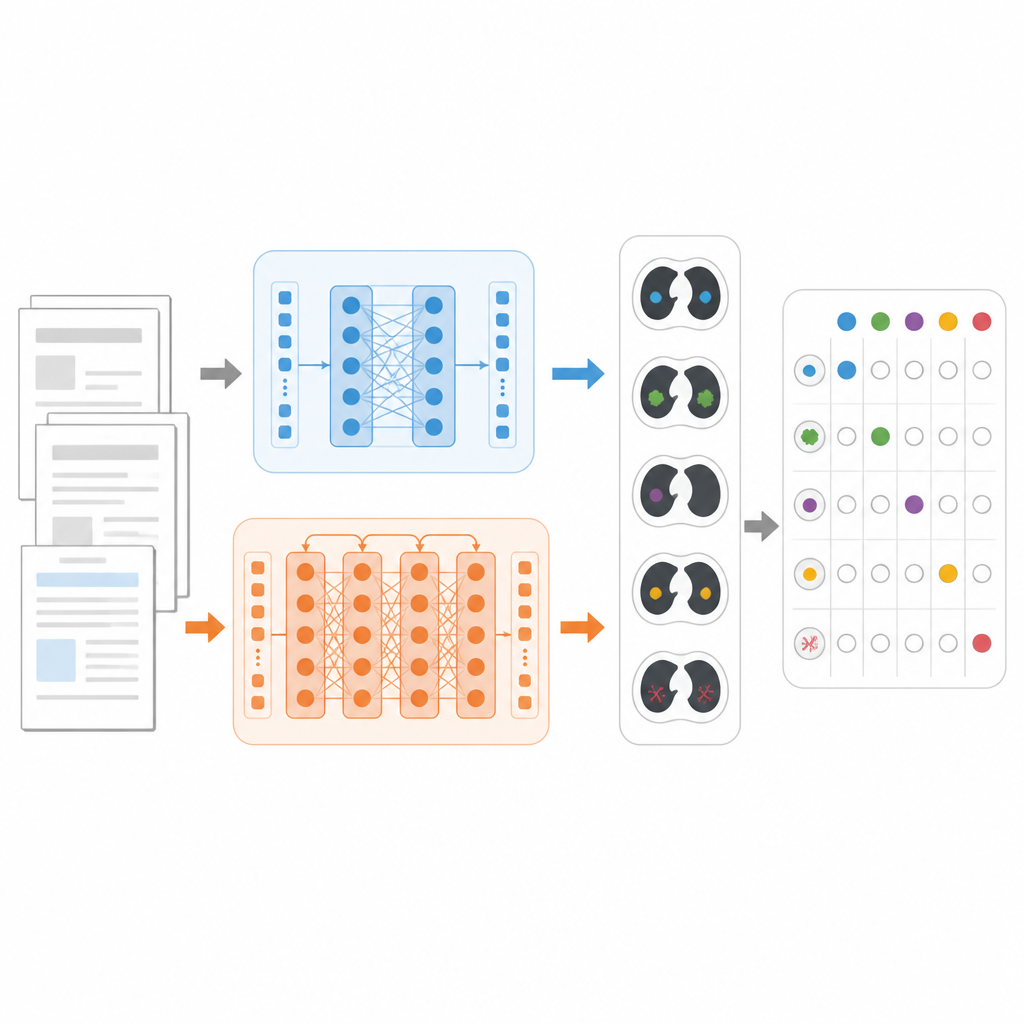
Daha zorlu bir gerçek dünya testi oluşturmak
Çevrilmiş raporlar günlük klinik yazımdan daha homojen olabileceği için ekip ayrıca RR‑Findings adında yeni bir dış veri seti oluşturdu. Bu 243 Japonca rapor, dokuz board sertifikalı radyolog tarafından yazılmış gerçek akciğer kanseri vakalarından geliyor. Her rapor, deneyimli hekimlerin dikkatli iki aşamalı inceleme süreciyle aynı 18 bulgu için etiketlendi. Çevrilmiş veri setinin aksine, bu raporlar radyologların pratikte nasıl yazdığını yansıtan çeşitlenen üslupları, yeniden ifade etmeleri ve kısaltmaları içeriyor; bu da RR‑Findings’i modellerin doğal dil farklılıklarıyla ne kadar başa çıktığını test etmek için daha güçlü kılıyor.
Daha kısa “kelime” parçalarından gelen hız kazanımları
Modeller arasındaki temel farklardan biri, metni işlemden önce parçalara (token’lara) nasıl ayırdıklarında yatıyor. ModernBERT, Japonca terimleri ve karışık İngilizce ifadeleri daha verimli ele alan çok daha zengin bir sözlük kullanıyor; bu nedenle aynı raporu temsil etmek için daha az token gerektiriyor. İç test kümesinde ModernBERT, ortalama token sayısını BERT’e kıyasla yaklaşık dörtte bir azalttı. Daha az token daha hızlı hesaplama demekti: ModernBERT, hem eğitim hem test sırasında saniyede yaklaşık bir buçuk kat daha fazla rapor işledi ve tam eğitimi diğer modellere göre çok daha kısa sürede tamamladı. Önemli olarak, bu verimlilik iç görevde doğruluktan ödün vermedi: üç model de benzer doğruluk düzeylerine ulaştı ve ModernBERT katı “tüm etiketler doğru” ölçütünde biraz önde çıktı.
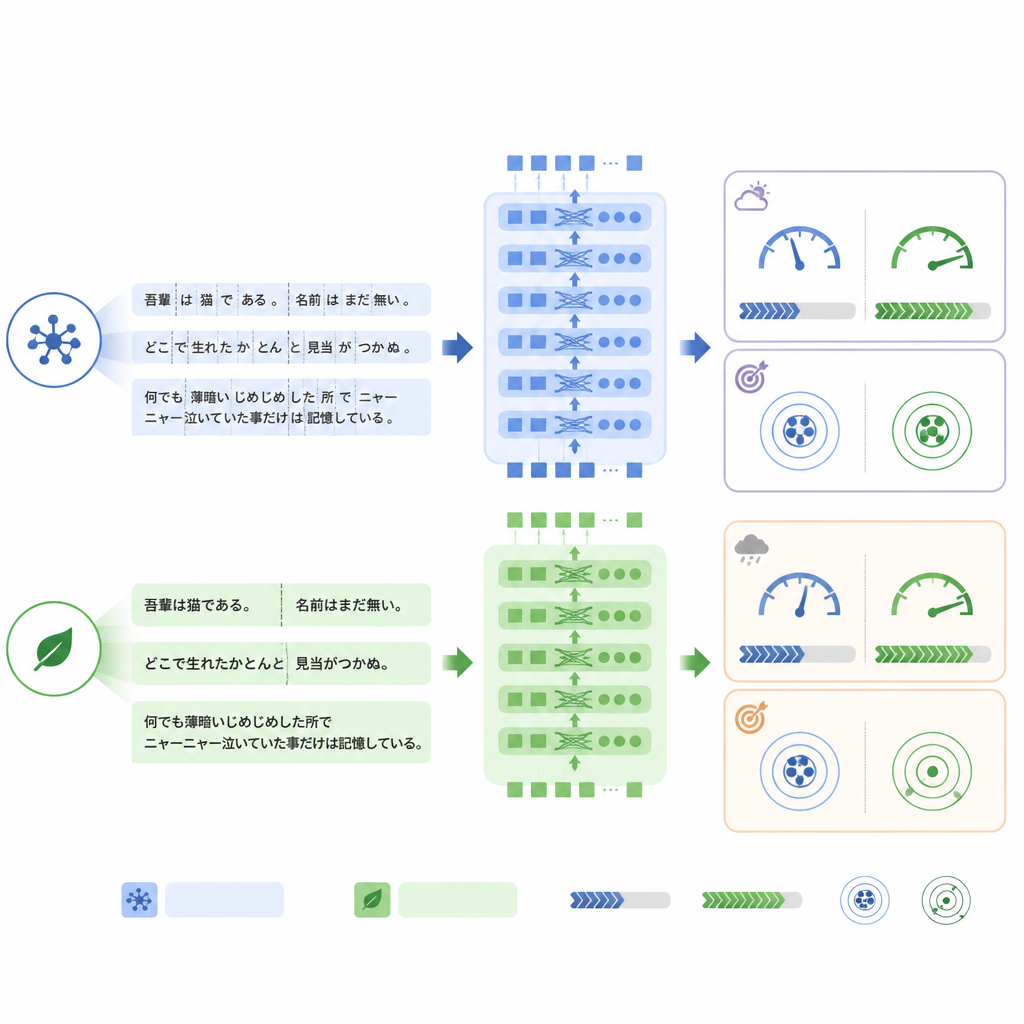
Dil üslubu değiştiğinde kararlılık önem kazanır
Modeller RR‑Findings gerçek dünya veri seti üzerinde test edildiğinde tablo değişti. Burada standart BERT en iyi tam eşleşme doğruluğunu elde etti; ModernBERT ise çevrilmiş raporlardaki performansına kıyasla en büyük düşüşü gösterdi. Ayrıntılı analiz, ModernBERT’in radyologlar eğitimde gördüğünden farklı ifade kullandığında —örneğin skarı doğrudan bir terim yerine “kronik inflamatuar değişiklik” olarak adlandırmak veya belirli nodüller için GGN gibi kısaltmalara başvurmak— daha fazla zorlandığını öne sürdü. Yine de hangi bulguların daha olası olduğu sıralaması makul düzeyde iyiydi; bu, temel ayrım yeteneğinden çok modelin güven eşiklerinin bu dil üslubu değişikliğine özellikle duyarlı olduğunu gösteriyor.
Bu, hastane yapay zekası araçları için ne anlama geliyor
Radyoloji raporlarını yerel ve özel yapay zeka araçlarıyla taramak isteyen hastaneler için ModernBERT özellikle daha uzun metinlerde hız ve hesaplama maliyeti açısından açık avantajlar sunuyor. İyi eşleşen verilerde, daha az kaynak kullanırken eski modellerin doğruluğuna eşit veya biraz üstün performans gösterebilir. Ancak bu çalışma, yalnızca verimliliğin yeterli olmadığını da gösteriyor: modeller, günlük raporlama gerçeğinin karmaşıklığıyla başa çıkmak için geniş bir yelpazede doğal klinik dil üzerinde eğitilmeli ve kalibre edilmelidir. Yazarlar, ModernBERT’in Japon radyoloji metinleri için güçlü ve verimli bir seçenek olduğunu, ancak hızlı modellerin yazım üslupları ve hasta popülasyonları değiştiğinde bile güvenilir kalması için daha çeşitli eğitim verileri ve daha akıllı ayarlamalar gerektiğini sonucuna bağlıyorlar.
Atıf: Yamagishi, Y., Kikuchi, T., Hanaoka, S. et al. ModernBERT is more efficient than conventional BERT for chest CT findings classification in Japanese radiology reports. Sci Rep 16, 15956 (2026). https://doi.org/10.1038/s41598-026-44292-z
Anahtar kelimeler: radyoloji raporları, Japon tıbbi yapay zeka, BERT, ModernBERT, göğüs BT bulguları