Clear Sky Science · es
ModernBERT es más eficiente que BERT convencional para la clasificación de hallazgos en TC de tórax en informes radiológicos japoneses
Por qué importa leer más rápido los informes médicos
Cada día, los hospitales generan miles de informes radiológicos que describen lo que los médicos ven en las exploraciones. Convertir estas notas en texto libre a información estructurada puede ayudar en la investigación, el control de calidad e incluso en futuros sistemas de IA que apoyen el diagnóstico. Pero primero los ordenadores deben “entender” el lenguaje, lo cual es especialmente difícil en la redacción médica japonesa por su mezcla de términos especializados, abreviaturas y frases en inglés. Este estudio plantea si un modelo de lenguaje más reciente llamado ModernBERT puede leer informes de TC de tórax en japonés con más eficiencia que los modelos BERT más antiguos y ampliamente usados, sin perder precisión.
Cómo aprenden los ordenadores a leer informes de exploraciones
Para comparar los modelos de forma justa, los investigadores se centraron en una tarea concreta: decidir, para cada informe de TC de tórax, cuáles de 18 posibles hallazgos están presentes, como nódulos pulmonares, enfisema o líquido pleural. Usaron un gran conjunto de datos público llamado CT‑RATE‑JPN, que contiene más de 22 000 informes de TC de tórax traducidos al japonés, cada uno etiquetado por expertos. La mayoría de los informes se usaron para entrenar y ajustar tres modelos: un BERT estándar, un JMedRoBERTa enfocado en medicina y ModernBERT. Un conjunto separado de 150 informes probó qué tan bien podía cada modelo asignar la combinación correcta de hallazgos.
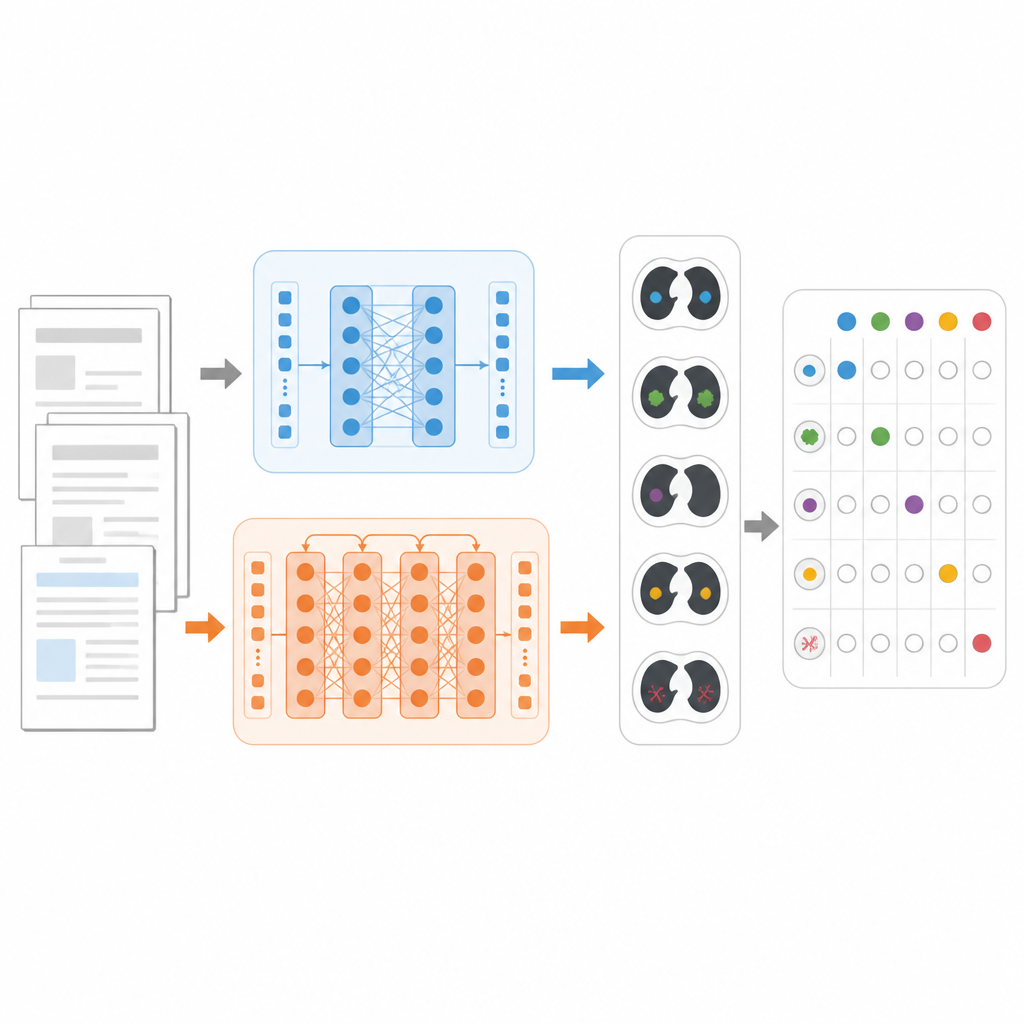
Construyendo una prueba más exigente del mundo real
Dado que los informes traducidos pueden ser más uniformes que la escritura clínica cotidiana, el equipo también creó un nuevo conjunto de datos externo llamado RR‑Findings. Estos 243 informes en japonés provienen de casos reales de cáncer de pulmón redactados por nueve radiólogos certificados. Cada informe fue etiquetado con los mismos 18 hallazgos mediante un cuidado proceso de revisión en dos pasos por médicos experimentados. A diferencia del conjunto traducido, estos informes incluyen estilos variados, paráfrasis y abreviaturas que reflejan cómo escriben realmente los radiólogos en la práctica, lo que convierte a RR‑Findings en una prueba más exigente de la capacidad de los modelos para afrontar las diferencias del lenguaje natural.
Ganancias de velocidad gracias a fragmentos de “palabra” más cortos
Una diferencia clave entre los modelos radica en cómo dividen el texto en piezas, o tokens, antes de procesarlo. ModernBERT usa un vocabulario mucho más rico que maneja términos japoneses y frases mixtas en inglés de forma más eficiente, por lo que necesita menos tokens para representar el mismo informe. En el conjunto de prueba interno, ModernBERT redujo el recuento medio de tokens en aproximadamente una cuarta parte respecto a BERT. Menos tokens significaron un cálculo más rápido: ModernBERT procesó alrededor de una vez y dos tercios más informes por segundo tanto en entrenamiento como en prueba, y completó el entrenamiento completo en mucho menos tiempo que los otros modelos. Importante: esta eficiencia no supuso un coste en la tarea interna: los tres modelos alcanzaron una precisión similar, con ModernBERT ligeramente por delante en la medida estricta de “todas las etiquetas correctas”.
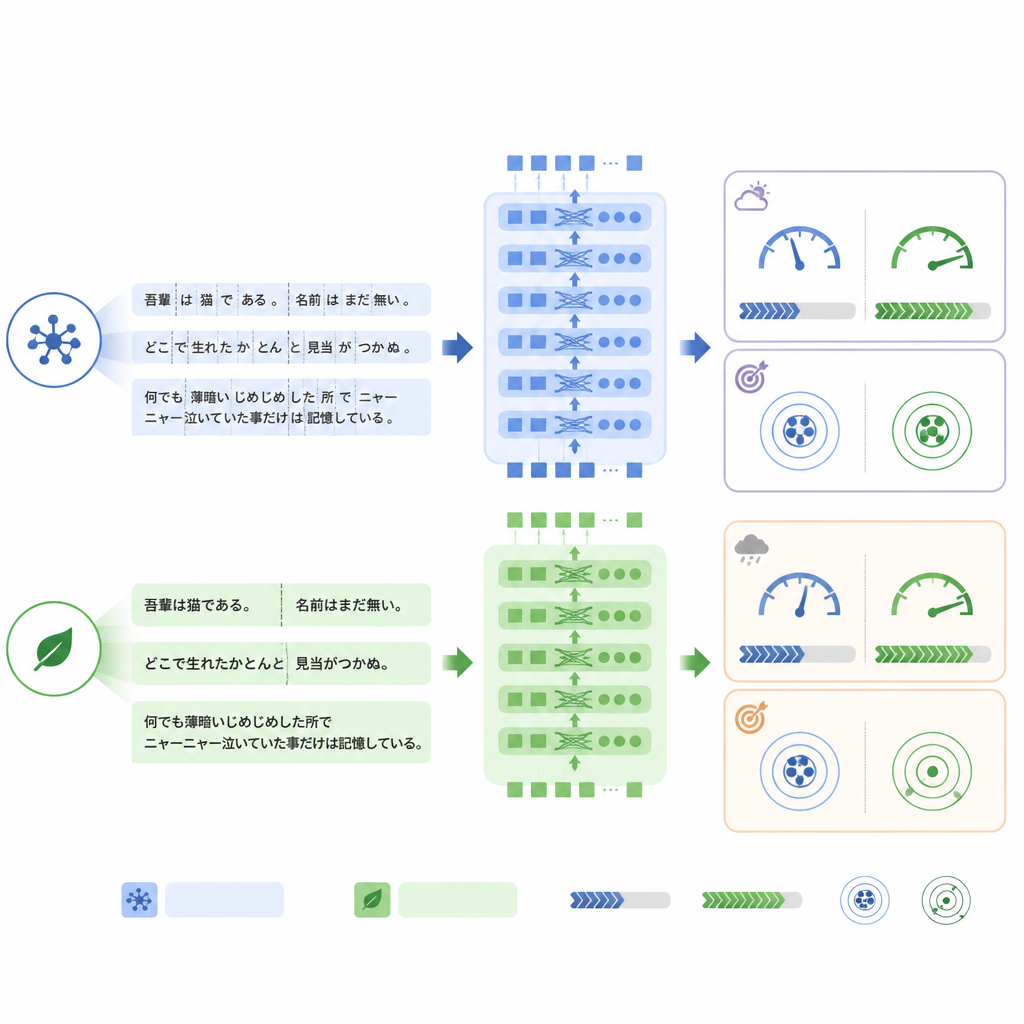
Cuando cambia el estilo del lenguaje, la estabilidad importa
El panorama cambió cuando los modelos se evaluaron en el conjunto RR‑Findings del mundo real. Aquí, BERT estándar logró la mejor precisión de coincidencia exacta, mientras que ModernBERT mostró la mayor caída respecto a su rendimiento en los informes traducidos. El análisis detallado sugirió que ModernBERT tenía más dificultades cuando los radiólogos empleaban formulaciones distintas a las vistas en entrenamiento, por ejemplo al llamar a una cicatriz “cambio inflamatorio crónico” en lugar de un término directo, o al usar abreviaturas como GGN para ciertos nódulos. Aun así, su ordenación de qué hallazgos eran más o menos probables se mantuvo razonablemente buena, lo que sugiere que sus umbrales de confianza, más que su capacidad básica para distinguir patrones, eran particularmente sensibles a este cambio en el estilo del lenguaje.
Qué significa esto para las herramientas de IA en hospitales
Para los hospitales que desean herramientas de IA locales y privadas para cribar informes radiológicos, ModernBERT ofrece ventajas claras en velocidad y coste computacional, especialmente para textos más largos. Con datos bien emparejados, puede igualar o superar ligeramente la precisión de modelos más antiguos mientras usa menos recursos. Sin embargo, este estudio también muestra que la eficiencia por sí sola no basta: los modelos deben entrenarse y calibrarse con una amplia gama de lenguaje clínico natural para manejar la realidad desordenada de la redacción cotidiana. Los autores concluyen que ModernBERT es una opción sólida y eficiente para texto radiológico japonés, pero que trabajos futuros deberían añadir datos de entrenamiento más diversos y ajustes más inteligentes para que los modelos rápidos sigan siendo fiables incluso cuando cambien los estilos de redacción y las poblaciones de pacientes.
Cita: Yamagishi, Y., Kikuchi, T., Hanaoka, S. et al. ModernBERT is more efficient than conventional BERT for chest CT findings classification in Japanese radiology reports. Sci Rep 16, 15956 (2026). https://doi.org/10.1038/s41598-026-44292-z
Palabras clave: informes radiológicos, IA médica japonesa, BERT, ModernBERT, hallazgos en TC de tórax