Clear Sky Science · it
ModernBERT è più efficiente del BERT convenzionale per la classificazione dei reperti della TC toracica nei referti radiologici giapponesi
Perché è importante leggere i referti medici più rapidamente
Ogni giorno gli ospedali generano migliaia di referti radiologici che descrivono ciò che i medici osservano nelle scansioni. Trasformare queste note in linguaggio libero in informazioni strutturate può aiutare nella ricerca, nel controllo di qualità e persino nello sviluppo di futuri sistemi di IA che supportano la diagnosi. Ma prima i computer devono “capire” il linguaggio, cosa particolarmente difficile per la scrittura medica giapponese, che mescola termini specialistici, abbreviazioni e locuzioni in inglese. Questo studio si chiede se un modello linguistico più recente, chiamato ModernBERT, possa leggere i referti di TC toracica giapponesi in modo più efficiente rispetto ai modelli BERT più vecchi e ampiamente usati, senza perdere accuratezza.
Come i computer imparano a leggere i referti di imaging
Per confrontare i modelli in modo equo, i ricercatori si sono concentrati su un compito concreto: decidere, per ciascun referto di TC toracica, quali dei 18 reperti possibili sono presenti, come noduli polmonari, enfisema o versamento pleurico. Hanno usato un ampio dataset pubblico chiamato CT‑RATE‑JPN, che contiene oltre 22.000 referti di TC toracica tradotti in giapponese, ciascuno etichettato da esperti. La maggior parte dei referti è stata utilizzata per addestrare e mettere a punto tre modelli: un BERT standard, un JMedRoBERTa orientato alla medicina e ModernBERT. Un set separato di 150 referti ha testato quanto bene ciascun modello riuscisse ad assegnare la corretta combinazione di reperti.
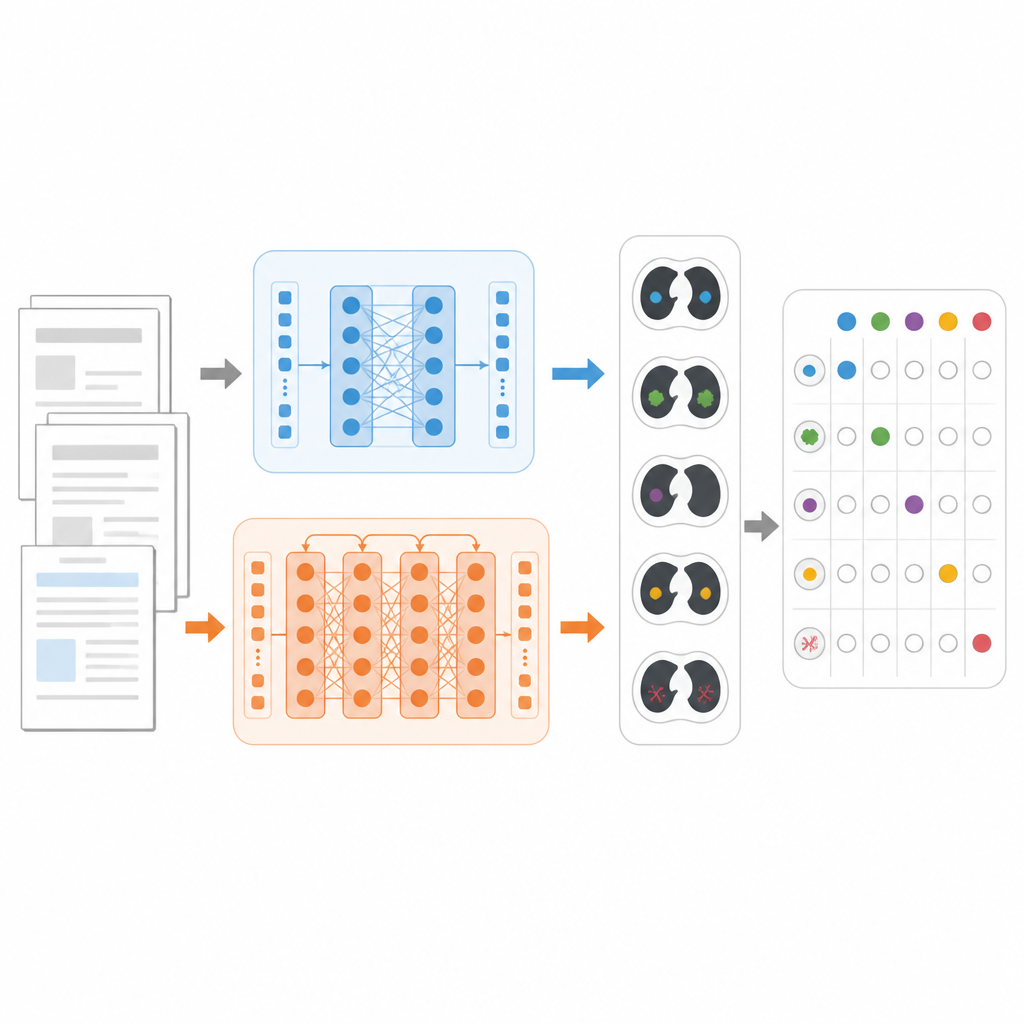
Costruire un test più severo e realistico
Poiché i referti tradotti possono essere più uniformi rispetto alla scrittura clinica quotidiana, il team ha anche costruito un nuovo dataset esterno chiamato RR‑Findings. Questi 243 referti giapponesi provengono da casi reali di cancro polmonare redatti da nove radiologi certificati. Ogni referto è stato etichettato con gli stessi 18 reperti mediante un accurato processo di revisione in due fasi da parte di medici esperti. A differenza del dataset tradotto, questi referti includono stili variabili, parafrasi e abbreviazioni che riflettono il modo in cui i radiologi scrivono nella pratica reale, rendendo RR‑Findings un test più impegnativo per verificare come i modelli affrontano le differenze del linguaggio naturale.
Vantaggi di velocità dalle “parole” più corte
Una differenza chiave tra i modelli riguarda come spezzano il testo in unità, o token, prima di elaborarlo. ModernBERT utilizza un vocabolario molto più ricco che gestisce in modo più efficiente i termini giapponesi e le frasi miste in inglese, quindi necessita di meno token per rappresentare lo stesso referto. Nel test interno, ModernBERT ha ridotto il numero medio di token di circa un quarto rispetto a BERT. Meno token hanno significato calcoli più rapidi: ModernBERT ha elaborato circa una volta e due terzi in più referti al secondo sia durante l’addestramento sia durante il test, e ha completato l’addestramento completo in molto meno tempo rispetto agli altri modelli. È importante notare che questa efficienza non ha comportato una perdita di performance nel compito interno: tutti e tre i modelli hanno raggiunto un’accuratezza simile, con ModernBERT leggermente in vantaggio nella misura più rigorosa di “tutte le etichette corrette”.
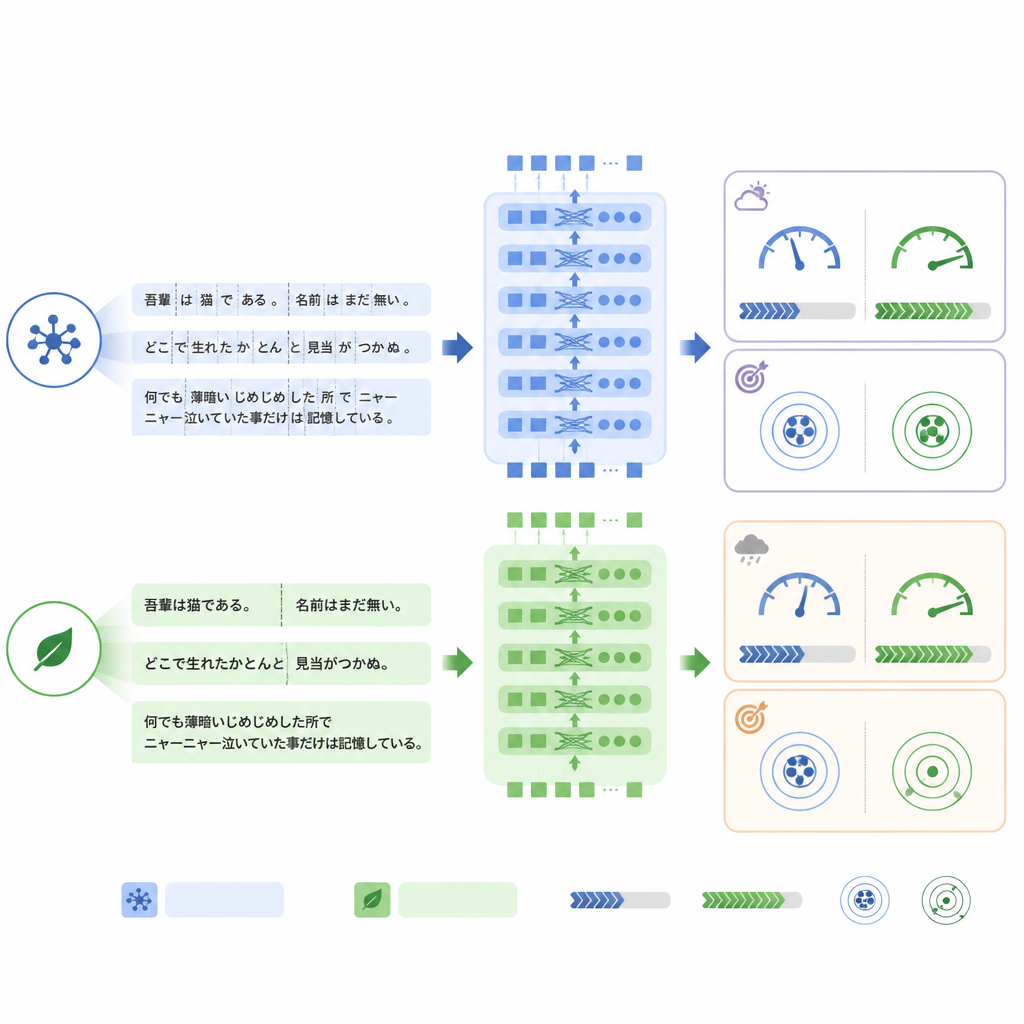
Quando lo stile linguistico cambia, conta la stabilità
Il quadro è cambiato quando i modelli sono stati testati sul dataset reale RR‑Findings. Qui, il BERT standard ha ottenuto la migliore accuratezza ad abbinamento esatto, mentre ModernBERT ha mostrato il calo maggiore rispetto alle sue prestazioni sui referti tradotti. L’analisi dettagliata suggerisce che ModernBERT ha avuto maggiori difficoltà quando i radiologi hanno usato formulazioni diverse da quelle viste durante l’addestramento, per esempio chiamando una cicatrice “modifica infiammatoria cronica” invece di usare un termine diretto, o ricorrendo ad abbreviazioni come GGN per certi noduli. Tuttavia la sua classifica dei reperti più o meno probabili è rimasta ragionevolmente buona, suggerendo che le soglie di confidenza, più che la capacità di base di distinguere i pattern, fossero particolarmente sensibili a questo cambiamento di stile linguistico.
Cosa significa per gli strumenti di IA ospedalieri
Per gli ospedali che desiderano strumenti di IA locali e privati per setacciare i referti radiologici, ModernBERT offre vantaggi chiari in termini di velocità e costi computazionali, specialmente per testi più lunghi. Su dati ben corrispondenti, può eguagliare o superare leggermente l’accuratezza dei modelli più vecchi usando meno risorse. Tuttavia, questo studio mostra anche che l’efficienza da sola non basta: i modelli devono essere addestrati e calibrati su una gamma ampia di linguaggio clinico naturale se devono gestire la realtà disordinata del refertare quotidiano. Gli autori concludono che ModernBERT è un’opzione solida ed efficiente per i testi radiologici giapponesi, ma che lavori futuri dovrebbero includere dati di addestramento più diversificati e una messa a punto più intelligente affinché i modelli veloci restino affidabili anche quando cambiano gli stili di scrittura e le popolazioni dei pazienti.
Citazione: Yamagishi, Y., Kikuchi, T., Hanaoka, S. et al. ModernBERT is more efficient than conventional BERT for chest CT findings classification in Japanese radiology reports. Sci Rep 16, 15956 (2026). https://doi.org/10.1038/s41598-026-44292-z
Parole chiave: referti radiologici, IA medica giapponese, BERT, ModernBERT, reperti TC toracica