Clear Sky Science · he
ModernBERT יעיל יותר מ‑BERT הקונבנציונלי למיון ממצאי CT חזה בדוחות רדיולוגיים יפניים
מדוע קריאת דוחות רפואיים מהירה חשובה
בתי חולים מייצרים מדי יום אלפי דוחות רדיולוגיה המתארים את מה שהרופאים רואים בסריקות. המרת ההערות החופשיות הללו למידע מובנה יכולה לסייע למחקר, לבקרת איכות ואף למערכות בינה מלאכותית עתידיות שתומכות באבחון. אך מחשבים צריכים קודם כל "להבין" את השפה, וזה קשה במיוחד בכתיבה רפואית יפנית שמשלבת מונחים تخصصיים, קיצורים וביטויים באנגלית. המחקר הזה שואל האם מודל שפה חדש בשם ModernBERT יכול לקרוא דוחות CT חזה יפניים בצורה יעילה יותר מהמודלים הוותיקים של BERT מבלי לאבד דיוק.
איך מחשבים לומדים לקרוא דוחות סריקה
כדי להשוות בין המודלים באופן הוגן, החוקרים התמקמו במשימה קונקרטית: להחליט, עבור כל דוח CT חזה, אילו מבין 18 הממצאים האפשריים נוכחים, כגון נודולים ריאתיים, אמפיזמה או נוזל סביב הריאות. הם השתמשו במאגר ציבורי גדול בשם CT‑RATE‑JPN, המכיל מעל 22,000 דוחות CT חזה מתורגמים ליפנית, שכל אחד מהם מתוייג על‑ידי מומחים. רוב הדוחות שימשו לאימון ולכיול של שלושה מודלים: BERT סטנדרטי, JMedRoBERTa הממוקד רפואית, ו‑ModernBERT. קבוצה נפרדת של 150 דוחות שימשה לבחינת היכולת של כל מודל להקצות את שילוב הממצאים הנכון.
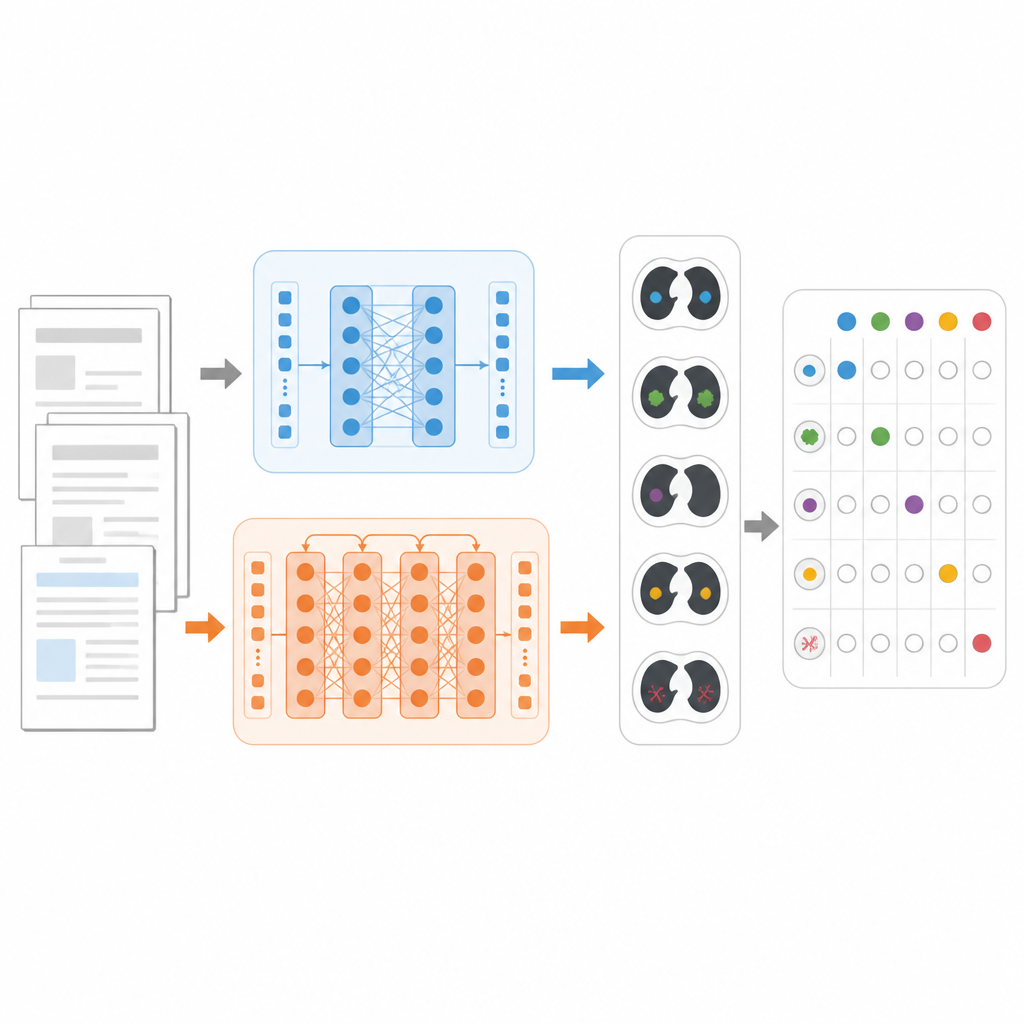
בניית מבחן קשה יותר מהעולם האמיתי
מכיוון שדוחות מתורגמים יכולים להיות אחידים יותר מאשר כתיבה קלינית יומיומית, הצוות גם הקים מאגר חיצוני חדש בשם RR‑Findings. 243 הדוחות היפניים הללו נלקחו ממקרי סרטן ריאה אמיתיים ונכתבו בידי תשעה רדיולוגים בעלי תעודה. כל דוח תוייג עם אותם 18 ממצאים באמצעות תהליך בדיקה דו‑שלבי קפדני בידי רופאים מנוסים. בניגוד למאגר המתורגם, דוחות אלה כוללים סגנונות שונים, פארפרזות וקיצורים המשקפים את אופן הכתיבה האמיתי של רדיולוגים, מה שהופך את RR‑Findings למבחן חזק יותר ליכולתם של המודלים להתמודד עם הבדלים בשפה הטבעית.
רווחי מהירות מהקטנת "חתיכות המילים"
הבדל מרכזי בין המודלים הוא באופן שבו הם מפצלים את הטקסט לחלקים, או טוקנים, לפני עיבוד. ModernBERT משתמש באוצר מילים עשיר יותר שמטפל ביעילות במונחים יפניים ובביטויים מעורבים באנגלית, ולכן נדרש בפחות טוקנים כדי לייצג את אותו דוח. במערך הבדיקה הפנימי ModernBERT קיצץ את ממוצע מספר הטוקנים בכ‑25% בערך בהשוואה ל‑BERT. פחות טוקנים פירש מהירות חישוב גבוהה יותר: ModernBERT עבד בערך פי 1.67 דוחות לשנייה במהלך האימון והבדיקה, והשלים אימון מלא בזמן קצר הרבה יותר מהמודלים האחרים. חשוב לציין שיעילות זו לא נרכשה על חשבון המשימה הפנימית: שלושת המודלים הגיעו לדיוק דומה, כאשר ModernBERT הוביל במעט במדד המחמיר של "כל התוויות נכונות".
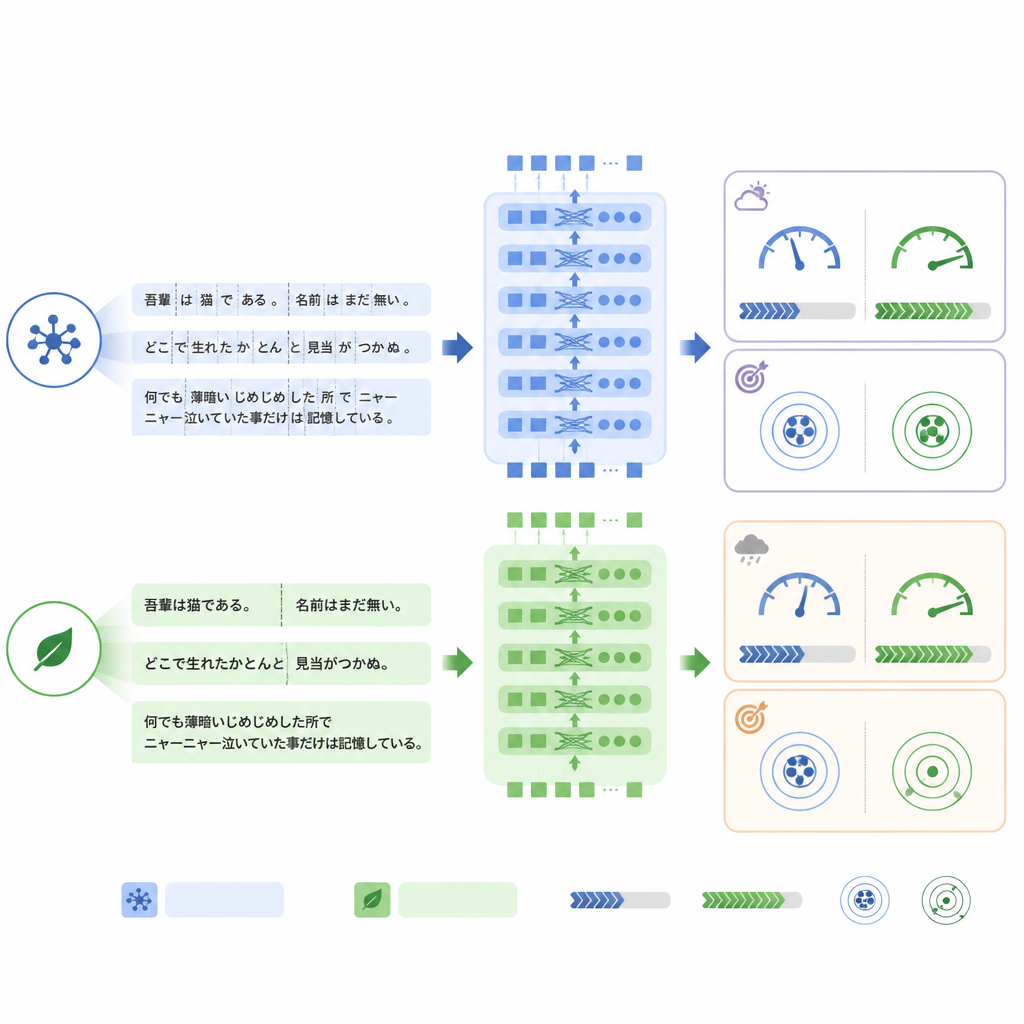
כשסגנון השפה משתנה, יציבות חשובה
התמונה השתנתה כאשר המודלים נבדקו על מאגר RR‑Findings מהעולם האמיתי. כאן BERT הסטנדרטי השיג את הדיוק הטכני הכי טוב, בעוד ModernBERT הראה את הירידה הגדולה ביותר בהשוואה לביצועיו על דוחות מתורגמים. ניתוח מפורט הציע ש‑ModernBERT התקשה יותר כאשר רדיולוגים השתמשו בניסוח שונה מזה שראה במהלך האימון — למשל תיאור צלקת כ"שינוי דלקתי כרוני" במקום מונח ישיר, או שימוש בקיצורים כמו GGN עבור סוגי נודולים. עם זאת, דירוגו של אילו ממצאים סביר יותר או פחות נותר סביר, מה שמעיד כי ספי הביטחון שלו, ולא היכולת הבסיסית לזהות דפוסים, רגישים במיוחד לשינוי בסגנון השפה.
מה זה אומר לכלי בינה מלאכותית בבתי חולים
לבתי חולים שמעוניינים בכלי בינה מלאכותית מקומיים ופרטיים לסרוק דוחות רדיולוגיה, ModernBERT מציע יתרונות ברורים במהירות ובעלות החישוב, במיוחד עבור טקסטים ארוכים. על נתונים המתאימים היטב, הוא יכול להתאים או אפילו לעלות במעט על הדיוק של מודלים ישנים תוך שימוש במשאבים מועטים יותר. עם זאת, המחקר מראה שגם יעילות בלבד אינה מספקת: יש צורך לאמן ולכיול את המודלים על מגוון רחב של שפה קלינית טבעית כדי שיוכלו להתמודד עם המציאות הלא מסודרת של הדיווח היומיומי. המחברים מסכמים ש‑ModernBERT הוא אופציה חזקה ויעילה לטקסט רדיולוגי יפני, אך יש להוסיף נתוני אימון מגוונים וכיולי חוכמה כדי שהמודלים המהירים יישארו אמינים גם כאשר סגנונות הכתיבה ואוכלוסיות המטופלים ישתנו.
ציטוט: Yamagishi, Y., Kikuchi, T., Hanaoka, S. et al. ModernBERT is more efficient than conventional BERT for chest CT findings classification in Japanese radiology reports. Sci Rep 16, 15956 (2026). https://doi.org/10.1038/s41598-026-44292-z
מילות מפתח: דוחות רדיולוגיה, בינה מלאכותית רפואית יפנית, BERT, ModernBERT, ממצאי CT חזה