Clear Sky Science · de
ModernBERT ist effizienter als herkömmliches BERT bei der Klassifikation von Brust‑CT‑Befunden in japanischen radiologischen Berichten
Warum schnelleres Lesen medizinischer Befunde wichtig ist
Täglich entstehen in Krankenhäusern Tausende radiologischer Berichte, die das Beschriebene auf Scans dokumentieren. Diese Freitext‑Notizen in strukturierte Informationen zu überführen, hilft bei Forschung, Qualitätssicherung und bei zukünftigen KI‑Systemen, die Diagnosen unterstützen. Dazu müssen Computer die Sprache «verstehen» — eine besondere Herausforderung bei japanischer Fachschrift mit ihrem Mix aus Fachbegriffen, Abkürzungen und englischen Phrasen. Diese Studie untersucht, ob ein neueres Sprachmodell namens ModernBERT japanische Brust‑CT‑Berichte effizienter lesen kann als die älteren, weit verbreiteten BERT‑Modelle, ohne an Genauigkeit zu verlieren.
Wie Computer das Lesen von Befunden lernen
Um die Modelle fair zu vergleichen, konzentrierten sich die Forschenden auf eine konkrete Aufgabe: Für jeden Brust‑CT‑Bericht zu entscheiden, welche von 18 möglichen Befunden vorliegen, etwa Lungenknötchen, Emphysem oder Pleuraerguss. Sie nutzten einen großen öffentlichen Datensatz namens CT‑RATE‑JPN mit über 22.000 ins Japanische übersetzten Brust‑CT‑Berichten, die jeweils von Expertinnen und Experten etikettiert wurden. Die meisten Berichte dienten zum Training und zur Feinabstimmung dreier Modelle: ein Standard‑BERT, ein medizinisch fokussiertes JMedRoBERTa und ModernBERT. Ein separater Satz von 150 Berichten testete, wie gut jedes Modell die korrekte Kombination von Befunden zuordnet.
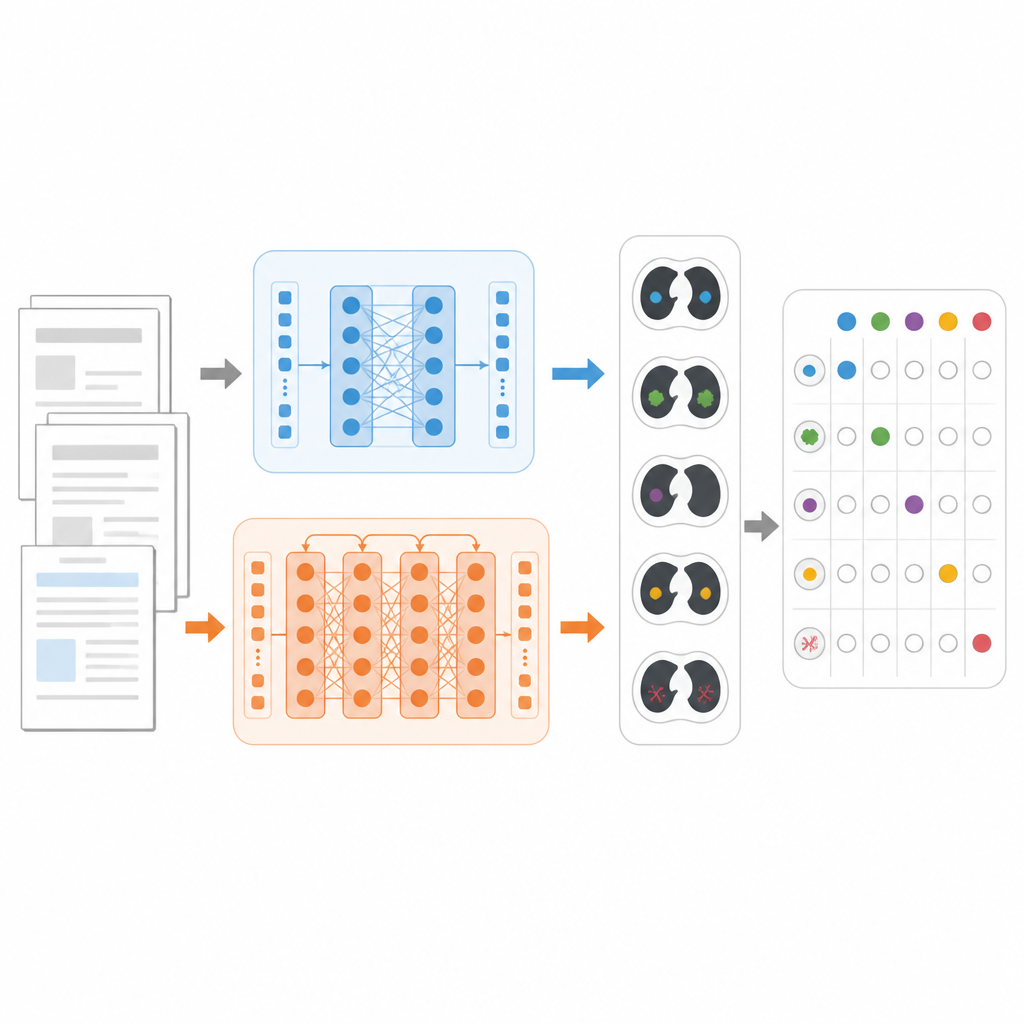
Ein härterer Test aus der Praxis
Weil übersetzte Berichte homogener sein können als die alltägliche klinische Schreibweise, erstellte das Team zudem einen neuen externen Datensatz namens RR‑Findings. Diese 243 japanischen Berichte stammen aus realen Lungenkrebserkrankungen und wurden von neun Fachradiologinnen und ‑radiologen verfasst. Jeder Bericht wurde mit denselben 18 Befunden versehen, wobei ein sorgfältiger zweistufiger Review‑Prozess durch erfahrene Ärztinnen und Ärzte zum Einsatz kam. Im Gegensatz zum übersetzten Datensatz enthalten diese Berichte verschiedene Stile, Umschreibungen und Abkürzungen, wie sie in der tatsächlichen Radiologiepraxis vorkommen, und bilden so einen anspruchsvolleren Test dafür, wie gut Modelle mit natürlichen Sprachunterschieden umgehen können.
Geschwindigkeitsvorteile durch kürzere „Wort“‑Chunks
Ein wesentlicher Unterschied zwischen den Modellen liegt darin, wie sie Text vor der Verarbeitung in Teile oder Tokens zerlegen. ModernBERT verwendet einen deutlich reichhaltigeren Wortschatz, der japanische Begriffe und gemischte englische Phrasen effizienter abbildet, sodass weniger Tokens nötig sind, um denselben Bericht zu repräsentieren. Im internen Testset reduzierte ModernBERT die durchschnittliche Token‑Anzahl um etwa ein Viertel gegenüber BERT. Weniger Tokens bedeuteten schnellere Berechnungen: ModernBERT verarbeitete während Training und Test etwa anderthalb- bis zweifach so viele Berichte pro Sekunde und schloss das vollständige Training in deutlich kürzerer Zeit ab als die anderen Modelle. Wichtig: Diese Effizienz ging in der internen Aufgabe nicht zulasten der Genauigkeit: Alle drei Modelle erreichten eine ähnliche Trefferquote, wobei ModernBERT beim strengen Maß „alle Labels korrekt“ leicht vorne lag.
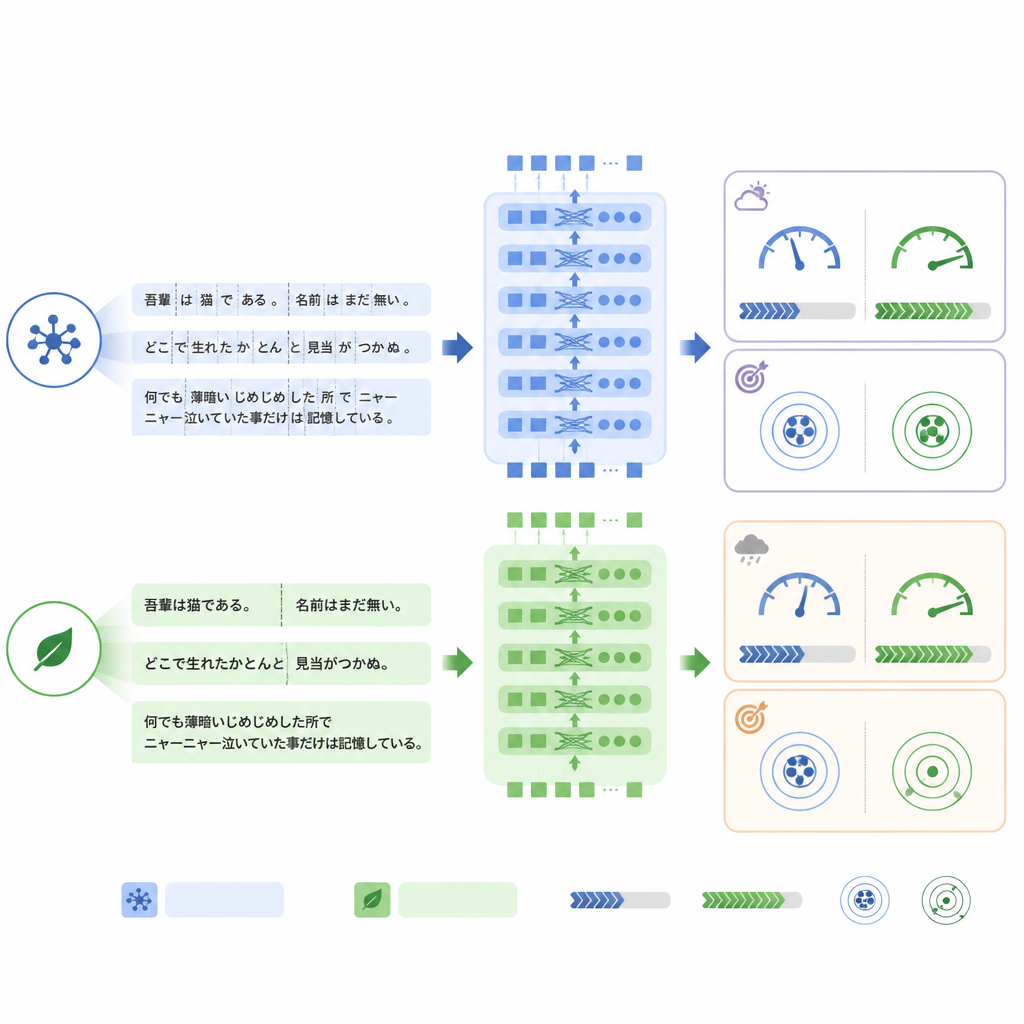
Wenn sich der Sprachstil ändert, ist Stabilität entscheidend
Das Bild änderte sich, als die Modelle am realen RR‑Findings‑Datensatz getestet wurden. Hier erzielte das Standard‑BERT die beste Exact‑Match‑Genauigkeit, während ModernBERT den größten Leistungsabfall gegenüber seiner Performance auf den übersetzten Berichten zeigte. Detaillierte Analysen legen nahe, dass ModernBERT größere Schwierigkeiten hatte, wenn Radiologinnen und Radiologen andere Formulierungen verwendeten als im Training gesehen — etwa wenn Narbenbildung als «chronische entzündliche Veränderung» beschrieben wurde statt eines direkteren Begriffs, oder wenn Abkürzungen wie GGN für bestimmte Knötchen genutzt wurden. Dennoch blieb seine Rangfolge, welche Befunde wahrscheinlicher sind, weitgehend erhalten, was darauf hindeutet, dass eher die Kalibrierung der Vertrauensschwellen als die grundlegende Musterunterscheidungsfähigkeit empfindlich auf den Sprachstilwechsel reagierte.
Was das für KI‑Werkzeuge in Krankenhäusern bedeutet
Für Krankenhäuser, die lokale, private KI‑Werkzeuge zum Durchforsten radiologischer Berichte einsetzen möchten, bietet ModernBERT klare Vorteile hinsichtlich Geschwindigkeit und Rechenkosten, besonders bei längeren Texten. Auf gut angepassten Daten kann es die Genauigkeit älterer Modelle erreichen oder leicht übertreffen und dabei weniger Ressourcen verbrauchen. Die Studie zeigt jedoch auch, dass Effizienz allein nicht ausreicht: Modelle müssen mit einer breiten Palette natürlicher klinischer Sprache trainiert und kalibriert werden, um die unordentliche Realität der Alltagsdokumentation zu bewältigen. Die Autorinnen und Autoren schließen, dass ModernBERT eine leistungsfähige, effiziente Option für japanische radiologische Texte darstellt, zukünftige Arbeit jedoch vielfältigere Trainingsdaten und intelligentere Feinabstimmung erfordern sollte, damit schnelle Modelle auch bei wechselnden Schreibstilen und Patientenpopulationen zuverlässig bleiben.
Zitation: Yamagishi, Y., Kikuchi, T., Hanaoka, S. et al. ModernBERT is more efficient than conventional BERT for chest CT findings classification in Japanese radiology reports. Sci Rep 16, 15956 (2026). https://doi.org/10.1038/s41598-026-44292-z
Schlüsselwörter: radiologische Berichte, japanische medizinische KI, BERT, ModernBERT, Befunde bei Brust‑CT