Clear Sky Science · pt
ModernBERT é mais eficiente que o BERT convencional para classificação de achados em tomografias de tórax em laudos radiológicos japoneses
Por que a leitura mais rápida de laudos médicos importa
Cada dia, hospitais geram milhares de laudos radiológicos que descrevem o que os médicos observam em exames. Converter essas anotações em texto livre para informação estruturada pode ajudar em pesquisa, controle de qualidade e até em futuros sistemas de IA que apoiem o diagnóstico. Mas os computadores precisam “entender” a linguagem primeiro, o que é particularmente difícil na escrita médica japonesa, com sua mistura de termos especializados, abreviações e expressões em inglês. Este estudo pergunta se um modelo de linguagem mais novo, chamado ModernBERT, consegue ler laudos de tomografia torácica em japonês de forma mais eficiente do que os modelos BERT mais antigos e amplamente usados, sem perder acurácia.
Como os computadores aprendem a ler laudos de exames
Para comparar os modelos de forma justa, os pesquisadores se concentraram em uma tarefa concreta: decidir, para cada laudo de tomografia torácica, quais dos 18 achados possíveis estão presentes, tais como nódulos pulmonares, enfisema ou líquido ao redor dos pulmões. Eles usaram um grande conjunto de dados público chamado CT‑RATE‑JPN, que contém mais de 22.000 laudos de tomografia torácica traduzidos para o japonês, cada um rotulado por especialistas. A maioria dos laudos foi usada para treinar e ajustar três modelos: um BERT padrão, um JMedRoBERTa voltado para medicina e o ModernBERT. Um conjunto separado de 150 laudos testou quão bem cada modelo podia atribuir a combinação correta de achados.
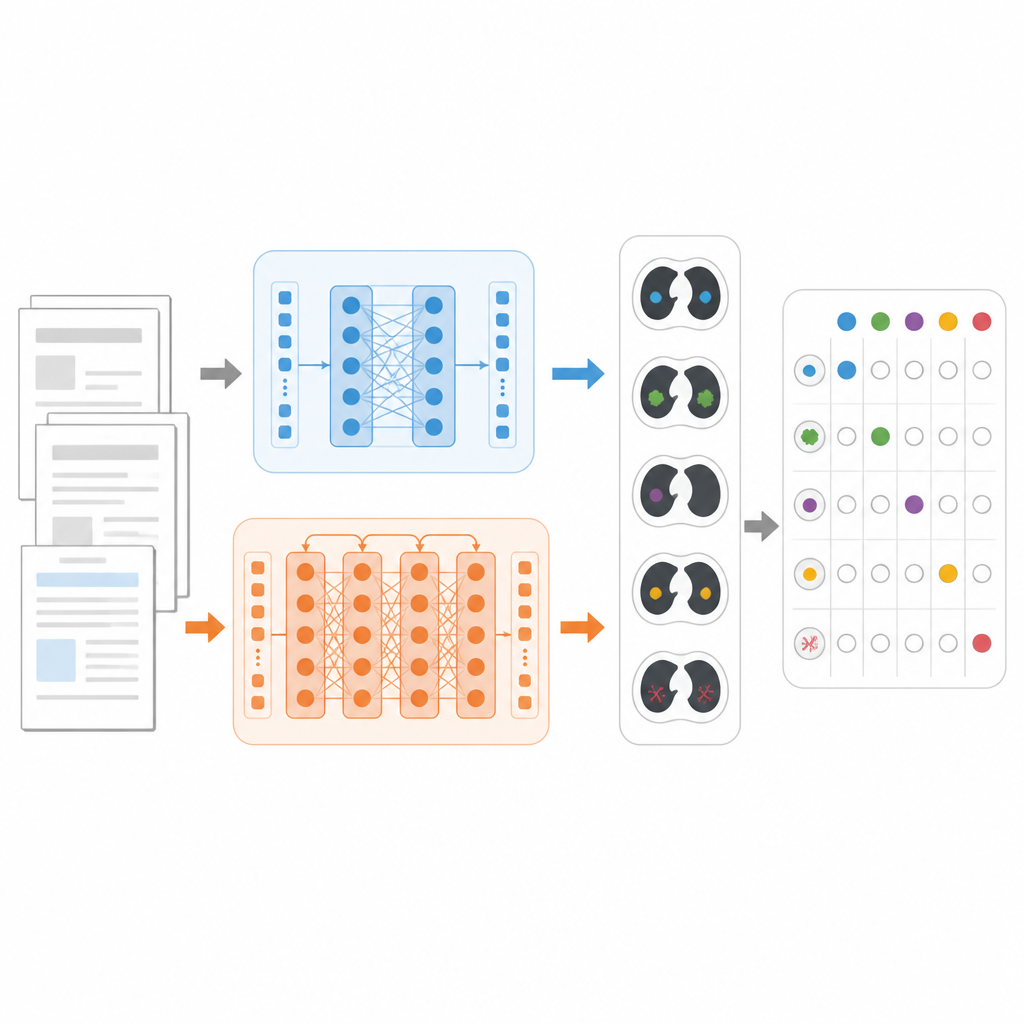
Construindo um teste mais desafiador do mundo real
Como laudos traduzidos podem ser mais uniformes do que a redação clínica cotidiana, a equipe também construiu um novo conjunto de dados externo chamado RR‑Findings. Esses 243 laudos em japonês vêm de casos reais de câncer de pulmão escritos por nove radiologistas certificados. Cada laudo foi rotulado com os mesmos 18 achados usando um cuidadoso processo de revisão em duas etapas por médicos experientes. Ao contrário do conjunto traduzido, esses laudos incluem estilos variados, paráfrases e abreviações que refletem como os radiologistas realmente escrevem na prática, tornando o RR‑Findings um teste mais robusto de como os modelos lidam com diferenças da linguagem natural.
Ganho de velocidade por fragmentos de “palavra” mais curtos
Uma diferença chave entre os modelos está em como eles dividem o texto em pedaços, ou tokens, antes do processamento. O ModernBERT usa um vocabulário muito mais rico que lida com termos japoneses e frases em inglês misturadas de forma mais eficiente, então precisa de menos tokens para representar o mesmo laudo. No conjunto de teste interno, o ModernBERT reduziu a contagem média de tokens em cerca de um quarto em comparação com o BERT. Menos tokens significaram computação mais rápida: o ModernBERT processou cerca de uma vez e dois terços mais laudos por segundo tanto durante o treinamento quanto nos testes, e completou o treinamento total em muito menos tempo que os outros modelos. Importante: essa eficiência não veio à custa da tarefa interna — os três modelos alcançaram acurácia semelhante, com o ModernBERT ligeiramente à frente na medida estrita de “todas as etiquetas corretas”.
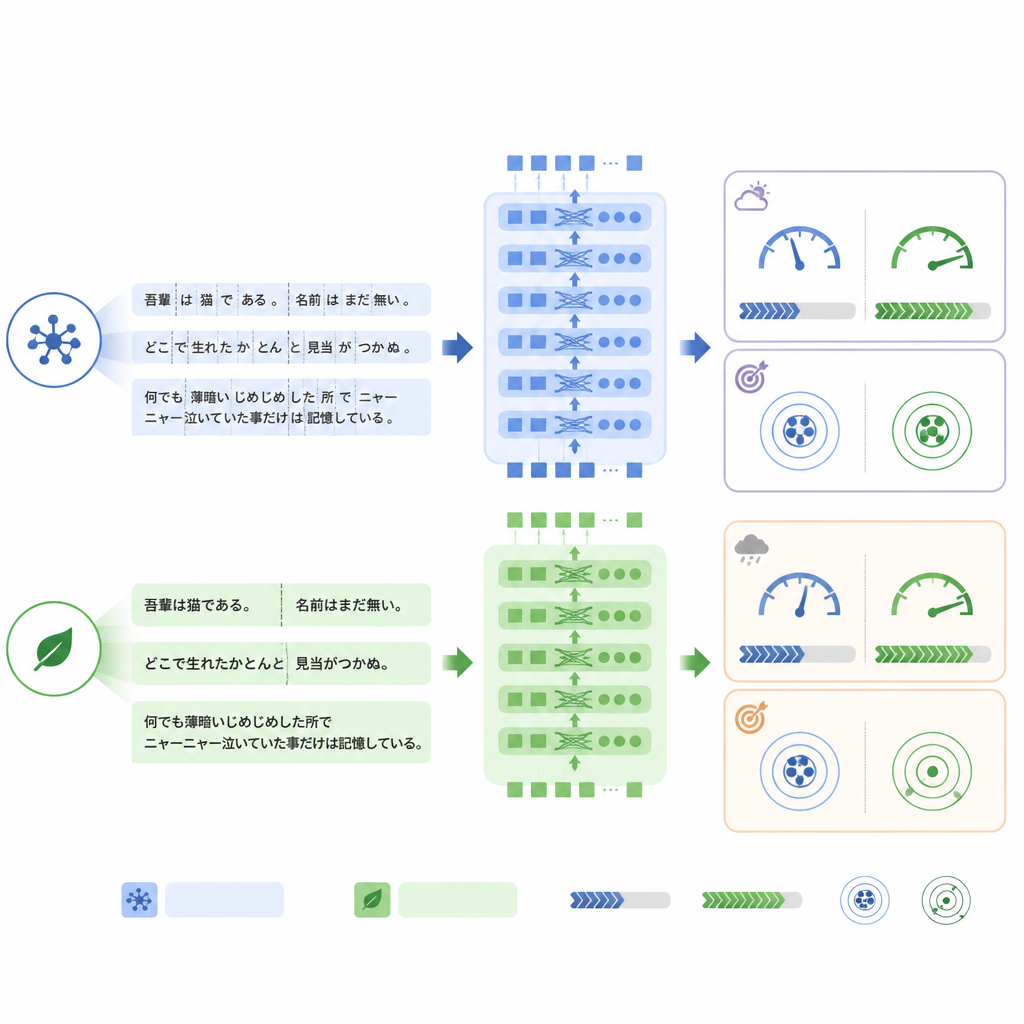
Quando o estilo de linguagem muda, a estabilidade importa
O quadro mudou quando os modelos foram testados no conjunto de dados real RR‑Findings. Aqui, o BERT padrão obteve a melhor acurácia de correspondência exata, enquanto o ModernBERT mostrou a maior queda em comparação com seu desempenho nos laudos traduzidos. Análises detalhadas sugeriram que o ModernBERT teve mais dificuldade quando os radiologistas usaram redações diferentes das vistas durante o treinamento — por exemplo, chamando cicatriz por “alteração inflamatória crônica” em vez de usar um termo direto, ou recorrendo a abreviações como GGN para certos nódulos. Ainda assim, sua ordenação de quais achados eram mais ou menos prováveis permaneceu razoavelmente boa, o que sugere que seus limiares de confiança, em vez da habilidade básica de distinguir padrões, foram particularmente sensíveis a essa mudança no estilo de linguagem.
O que isso significa para ferramentas de IA em hospitais
Para hospitais que desejam ferramentas de IA locais e privadas para vasculhar laudos radiológicos, o ModernBERT oferece vantagens claras em velocidade e custo computacional, especialmente para textos mais longos. Em dados bem alinhados, ele pode igualar ou superar ligeiramente a acurácia de modelos mais antigos enquanto usa menos recursos. Entretanto, este estudo também mostra que eficiência sozinha não é suficiente: os modelos precisam ser treinados e calibrados em uma ampla gama de linguagem clínica natural para lidar com a realidade desordenada da prática diária. Os autores concluem que o ModernBERT é uma opção forte e eficiente para textos radiológicos japoneses, mas trabalhos futuros devem incluir dados de treinamento mais diversos e ajustes mais inteligentes para que modelos rápidos permaneçam confiáveis mesmo quando estilos de escrita e populações de pacientes mudarem.
Citação: Yamagishi, Y., Kikuchi, T., Hanaoka, S. et al. ModernBERT is more efficient than conventional BERT for chest CT findings classification in Japanese radiology reports. Sci Rep 16, 15956 (2026). https://doi.org/10.1038/s41598-026-44292-z
Palavras-chave: laudos radiológicos, IA médica japonesa, BERT, ModernBERT, achados em tomografia de tórax