Clear Sky Science · fr
ModernBERT est plus efficace que BERT conventionnel pour la classification des observations sur les scanners thoraciques dans les comptes rendus radiologiques japonais
Pourquoi une lecture plus rapide des comptes rendus médicaux compte
Chaque jour, les hôpitaux génèrent des milliers de comptes rendus radiologiques décrivant ce que voient les médecins sur les examens. Transformer ces notes en texte libre en informations structurées peut aider la recherche, le contrôle qualité et même de futurs systèmes d’IA d’aide au diagnostic. Mais les ordinateurs doivent d’abord « comprendre » le langage, ce qui est particulièrement difficile pour l’écriture médicale japonaise avec son mélange de termes spécialisés, d’abréviations et d’expressions en anglais. Cette étude s’interroge sur la capacité d’un modèle de langage plus récent, ModernBERT, à lire les comptes rendus de scanner thoracique japonais plus efficacement que les modèles BERT plus anciens et largement utilisés, sans perdre en précision.
Comment les ordinateurs apprennent à lire les comptes rendus d’examen
Pour comparer les modèles de manière équitable, les chercheurs se sont concentrés sur une tâche concrète : décider, pour chaque compte rendu de scanner thoracique, lesquelles des 18 observations possibles sont présentes, comme des nodules pulmonaires, de l’emphysème ou un épanchement pleural. Ils ont utilisé un grand jeu de données public appelé CT‑RATE‑JPN, qui contient plus de 22 000 comptes rendus de scanner thoracique traduits en japonais, chacun étiqueté par des experts. La plupart des comptes rendus ont servi à entraîner et à ajuster trois modèles : un BERT standard, un JMedRoBERTa axé sur le domaine médical et ModernBERT. Un ensemble séparé de 150 comptes rendus a testé la capacité de chaque modèle à attribuer la combinaison correcte d’observations.
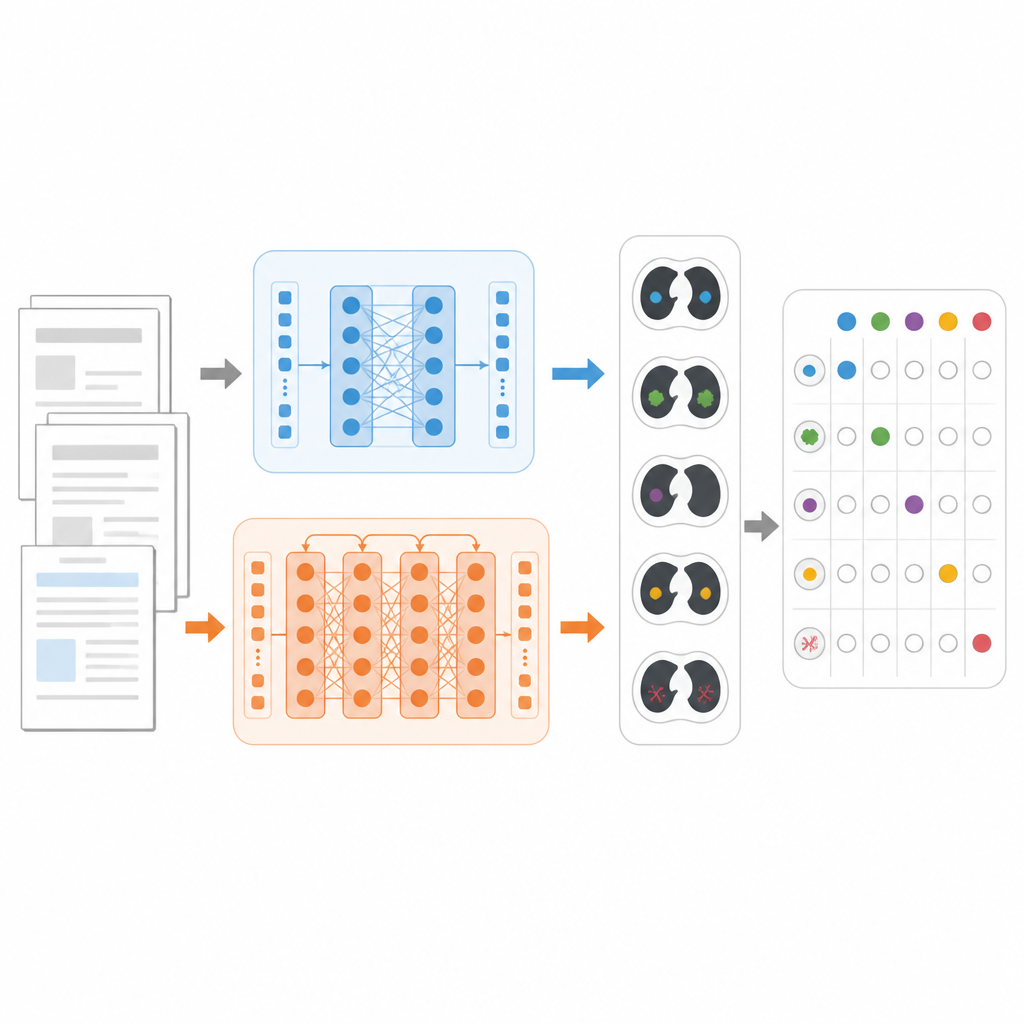
Construire un test du monde réel plus exigeant
Parce que les comptes rendus traduits peuvent être plus uniformes que l’écriture clinique quotidienne, l’équipe a aussi constitué un nouveau jeu de données externe appelé RR‑Findings. Ces 243 comptes rendus japonais proviennent de cas réels de cancer du poumon rédigés par neuf radiologues certifiés. Chaque compte rendu a été étiqueté avec les mêmes 18 observations via un processus d’examen en deux étapes par des médecins expérimentés. Contrairement au jeu traduit, ces comptes rendus incluent des styles variés, des paraphrases et des abréviations qui reflètent la façon réelle d’écrire des radiologues en pratique, faisant de RR‑Findings un test plus exigeant de la capacité des modèles à gérer les différences de langage naturel.
Gains de vitesse grâce à des « mots » plus courts
Une différence clé entre les modèles réside dans la manière dont ils segmentent le texte en morceaux, ou tokens, avant traitement. ModernBERT utilise un vocabulaire beaucoup plus riche qui gère plus efficacement les termes japonais et les expressions anglaises mixtes, de sorte qu’il nécessite moins de tokens pour représenter le même compte rendu. Sur l’ensemble de test interne, ModernBERT a réduit le nombre moyen de tokens d’environ un quart par rapport à BERT. Moins de tokens a signifié un calcul plus rapide : ModernBERT a traité environ une fois et deux tiers plus de comptes rendus par seconde durant l’entraînement et les tests, et a terminé l’apprentissage complet en bien moins de temps que les autres modèles. Fait important, cette efficience n’a pas compromis la performance sur la tâche interne : les trois modèles ont atteint une précision similaire, ModernBERT étant légèrement en tête sur la mesure stricte « toutes les étiquettes correctes ».
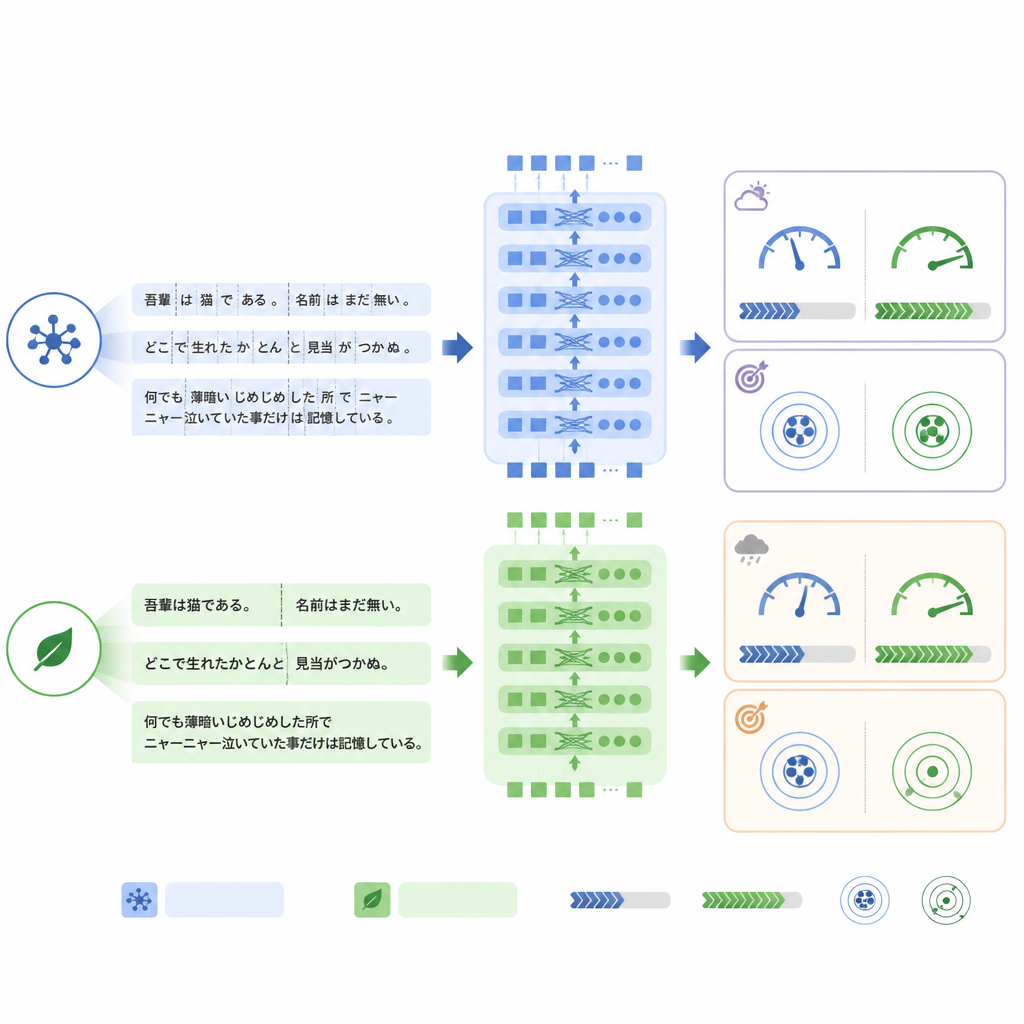
Quand le style de langage change, la stabilité importe
Le constat a changé lorsque les modèles ont été testés sur le jeu de données réel RR‑Findings. Ici, le BERT standard a obtenu la meilleure exactitude en correspondance exacte, tandis que ModernBERT a montré la plus forte baisse par rapport à sa performance sur les comptes rendus traduits. L’analyse détaillée suggère que ModernBERT a eu plus de difficultés lorsque les radiologues utilisaient des formulations différentes de celles vues durant l’entraînement, par exemple en qualifiant des cicatrices de « modification inflammatoire chronique » au lieu d’un terme direct, ou en recourant à des abréviations comme GGN pour certains nodules. Pourtant, son classement des observations selon leur probabilité est resté raisonnablement bon, ce qui suggère que ce sont surtout ses seuils de confiance, plutôt que sa capacité fondamentale à distinguer des schémas, qui ont été sensibles à ce changement de style linguistique.
Ce que cela signifie pour les outils d’IA hospitaliers
Pour les hôpitaux souhaitant des outils d’IA locaux et privés pour passer au crible les comptes rendus radiologiques, ModernBERT offre des avantages nets en rapidité et en coût de calcul, notamment pour des textes plus longs. Sur des données bien appariées, il peut égaler ou légèrement dépasser la précision des modèles plus anciens tout en consommant moins de ressources. Toutefois, cette étude montre aussi que l’efficience seule ne suffit pas : les modèles doivent être entraînés et calibrés sur une large variété de langage clinique naturel s’ils veulent gérer la réalité désordonnée du reporting quotidien. Les auteurs concluent que ModernBERT est une option performante et efficace pour le texte radiologique japonais, mais que des travaux futurs devraient ajouter des données d’entraînement plus diverses et des réglages plus intelligents pour que les modèles rapides restent fiables même quand les styles d’écriture et les populations de patients évoluent.
Citation: Yamagishi, Y., Kikuchi, T., Hanaoka, S. et al. ModernBERT is more efficient than conventional BERT for chest CT findings classification in Japanese radiology reports. Sci Rep 16, 15956 (2026). https://doi.org/10.1038/s41598-026-44292-z
Mots-clés: comptes rendus radiologiques, IA médicale japonaise, BERT, ModernBERT, observations scanner thoracique