Clear Sky Science · ru
ModernBERT эффективнее классического BERT для классификации находок на КТ грудной клетки в японских радиологических отчетах
Почему важно быстрее читать медицинские отчеты
Ежедневно в больницах создаются тысячи радиологических отчетов, в которых врачи описывают, что видно на сканах. Преобразование этих текстов в структурированную информацию помогает в исследованиях, контроле качества и в будущих ИИ‑системах, поддерживающих диагностику. Но компьютерам сначала нужно «понять» язык, что особенно трудно для японской медицинской документации с её смесью специализированных терминов, сокращений и англицизмов. В этом исследовании проверяют, может ли новая языковая модель ModernBERT читать японские отчеты по КТ грудной клетки эффективнее, чем старые, широко используемые модели BERT, не теряя в точности.
Как компьютеры учатся читать отчеты по сканированию
Чтобы сравнение моделей было корректным, исследователи сосредоточились на конкретной задаче: для каждого отчета по КТ грудной клетки определить, какие из 18 возможных находок присутствуют, например узелки в легких, эмфизема или жидкость в плевре. Они использовали крупный публичный набор данных CT‑RATE‑JPN, содержащий более 22 000 переведенных на японский язык отчетов по КТ грудной клетки, каждый помеченный экспертами. Большая часть отчетов пошла на обучение и настройку трёх моделей: стандартного BERT, медицински ориентированного JMedRoBERTa и ModernBERT. Отдельный набор из 150 отчетов использовали для проверки того, насколько точно каждая модель может назначить правильную комбинацию находок.
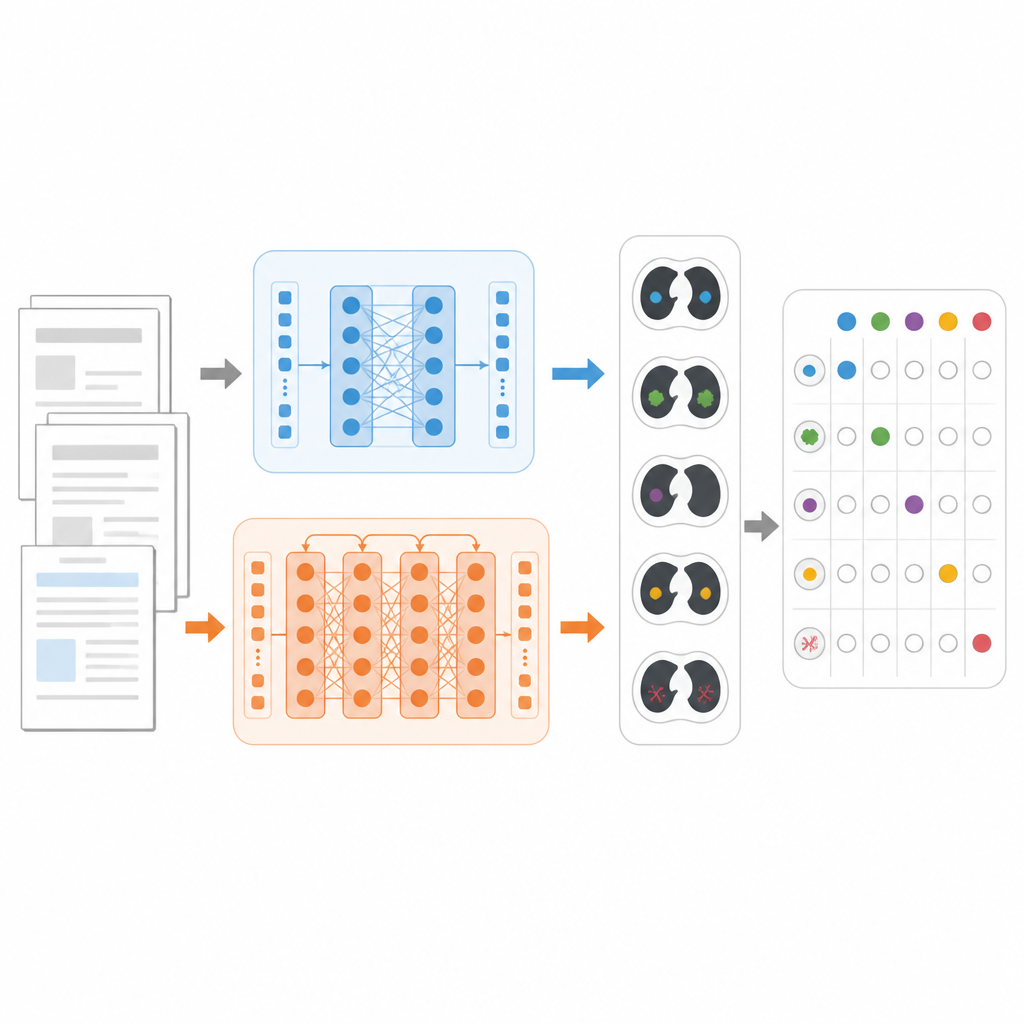
Создание более жёсткого теста из реальной практики
Поскольку переведенные отчеты могут быть более однородны, чем повседневное клиническое письмо, команда также собрала новый внешний набор данных RR‑Findings. В него вошли 243 японских отчета из реальных случаев рака лёгких, подготовленных девятью сертифицированными рентгенологами. Каждый отчет был помечен по тем же 18 находкам с помощью тщательной двухэтапной проверки опытными врачами. В отличие от переведённого набора, эти отчеты включают разнообразные стили, перефразировки и сокращения, характерные для реального письма радиологов, что делает RR‑Findings более строгим испытанием способности моделей справляться с вариативностью естественного языка.
Ускорение за счёт более коротких «слов»
Ключевое отличие между моделями — способ, которым они разбивают текст на фрагменты, или токены, перед обработкой. ModernBERT использует значительно более богатый словарь, который эффективнее обрабатывает японские термины и смешанные английские фразы, поэтому для представления одного и того же отчета ему требуется меньше токенов. В внутреннем тестовом наборе ModernBERT сократил среднее количество токенов примерно на четверть по сравнению с BERT. Меньше токенов означало более быструю обработку: ModernBERT обрабатывал примерно в полтора раза больше отчетов в секунду как при обучении, так и при тестировании, и завершал полное обучение гораздо быстрее других моделей. При этом эта эффективность не сопровождалась ухудшением на внутренней задаче: все три модели достигли сопоставимой точности, а ModernBERT незначительно опередил конкурентов по строгой метрике «все метки верны».
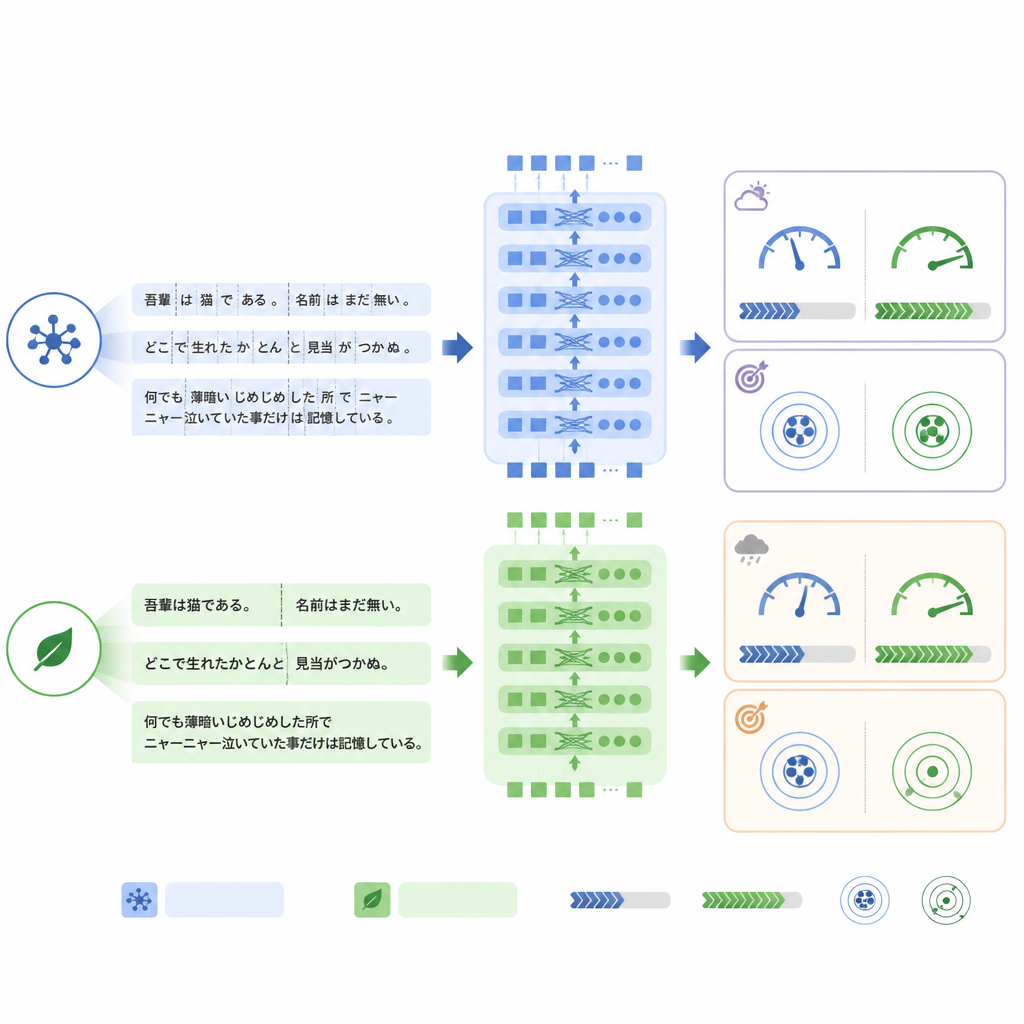
Когда стиль языка меняется, важна стабильность
Картина изменилась при проверке моделей на реальном наборе RR‑Findings. Здесь стандартный BERT показал наилучшую точность точного совпадения, тогда как ModernBERT продемонстрировал наибольшее падение по сравнению с его результатами на переведённых отчетах. Подробный анализ указывает, что ModernBERT испытывал большие трудности, когда рентгенологи использовали формулировки, отличные от тех, что встречались в обучающем наборе — например, называли рубцевание «хроническим воспалительным изменением» вместо прямого термина или использовали сокращения вроде GGN для определённых узелков. Тем не менее ранжирование находок по вероятности сохранилось на приемлемом уровне, что указывает на то, что именно пороговые значения уверенности, а не базовая способность различать паттерны, оказались особенно чувствительны к смене стиля языка.
Что это значит для ИИ‑инструментов в больницах
Для больниц, которые хотят развернуть локальные, приватные ИИ‑инструменты для работы с радиологическими отчетами, ModernBERT даёт явные преимущества по скорости и вычислительным затратам, особенно при работе с более длинными текстами. На данных, схожих с обучающими, он может сопоставимо или слегка лучше показывать точность по сравнению со старыми моделями при меньших ресурсах. Однако исследование также показывает, что одной эффективности недостаточно: модели нужно обучать и калибровать на широком диапазоне естественной клинической речи, чтобы они справлялись с неструктурированной реальностью повседневной отчетности. Авторы заключают, что ModernBERT — сильный и эффективный вариант для японского радиологического текста, но будущая работа должна добавить более разнообразные тренировочные данные и более умную настройку, чтобы быстрые модели оставались надежными даже при изменении стилей письма и популяций пациентов.
Цитирование: Yamagishi, Y., Kikuchi, T., Hanaoka, S. et al. ModernBERT is more efficient than conventional BERT for chest CT findings classification in Japanese radiology reports. Sci Rep 16, 15956 (2026). https://doi.org/10.1038/s41598-026-44292-z
Ключевые слова: радиологические отчеты, японский медицинский ИИ, BERT, ModernBERT, находки на КТ грудной клетки