Clear Sky Science · en
ModernBERT is more efficient than conventional BERT for chest CT findings classification in Japanese radiology reports
Why faster reading of medical reports matters
Every day, hospitals generate thousands of radiology reports that describe what doctors see on scans. Turning these free‑text notes into structured information can help with research, quality control, and even future AI systems that support diagnosis. But computers need to “understand” the language first, which is particularly hard for Japanese medical writing with its mix of specialized terms, abbreviations, and English phrases. This study asks whether a newer language model called ModernBERT can read Japanese chest CT reports more efficiently than the older, widely used BERT models without losing accuracy.
How computers learn to read scan reports
To compare models fairly, the researchers focused on a concrete task: decide, for each chest CT report, which of 18 possible findings are present, such as lung nodules, emphysema, or fluid around the lungs. They used a large public dataset called CT‑RATE‑JPN, which contains over 22,000 translated chest CT reports in Japanese, each labeled by experts. Most reports were used to train and tune three models: a standard BERT, a medically focused JMedRoBERTa, and ModernBERT. A separate set of 150 reports tested how well each model could assign the correct combination of findings.
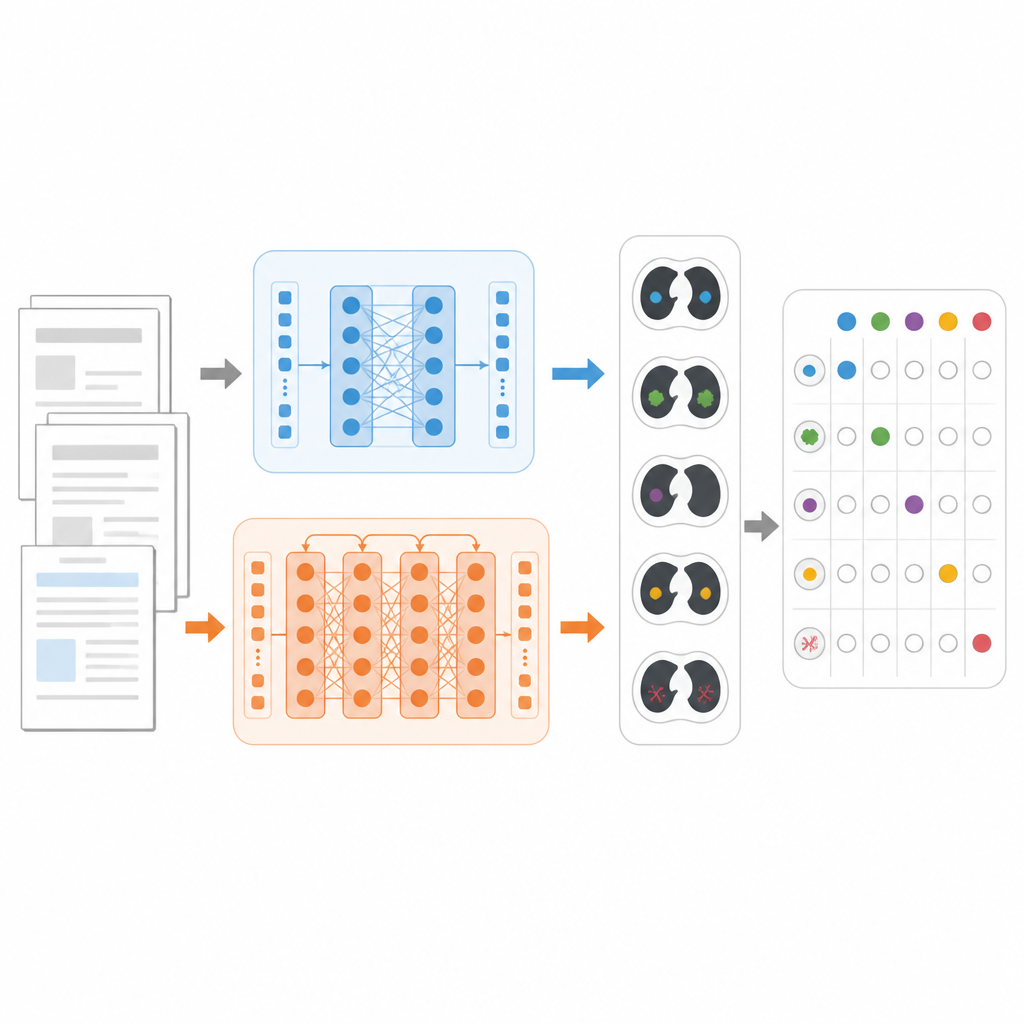
Building a tougher real‑world test
Because translated reports can be more uniform than everyday clinical writing, the team also built a new external dataset called RR‑Findings. These 243 Japanese reports come from real lung cancer cases written by nine board‑certified radiologists. Each report was labeled with the same 18 findings using a careful two‑step review process by experienced doctors. Unlike the translated dataset, these reports include varied styles, paraphrases, and abbreviations that reflect how radiologists actually write in practice, making RR‑Findings a stronger test of how well models cope with natural language differences.
Speed gains from shorter “word” chunks
A key difference between the models lies in how they break text into pieces, or tokens, before processing. ModernBERT uses a much richer vocabulary that handles Japanese terms and mixed English phrases more efficiently, so it needs fewer tokens to represent the same report. In the internal test set, ModernBERT cut the average token count by about a quarter compared with BERT. Fewer tokens meant faster computation: ModernBERT processed about one‑and‑two‑thirds as many reports per second during both training and testing, and finished full training in far less time than the other models. Importantly, this efficiency did not come at a cost on the internal task: all three models reached similar accuracy, with ModernBERT slightly ahead in the strict “all labels correct” measure.
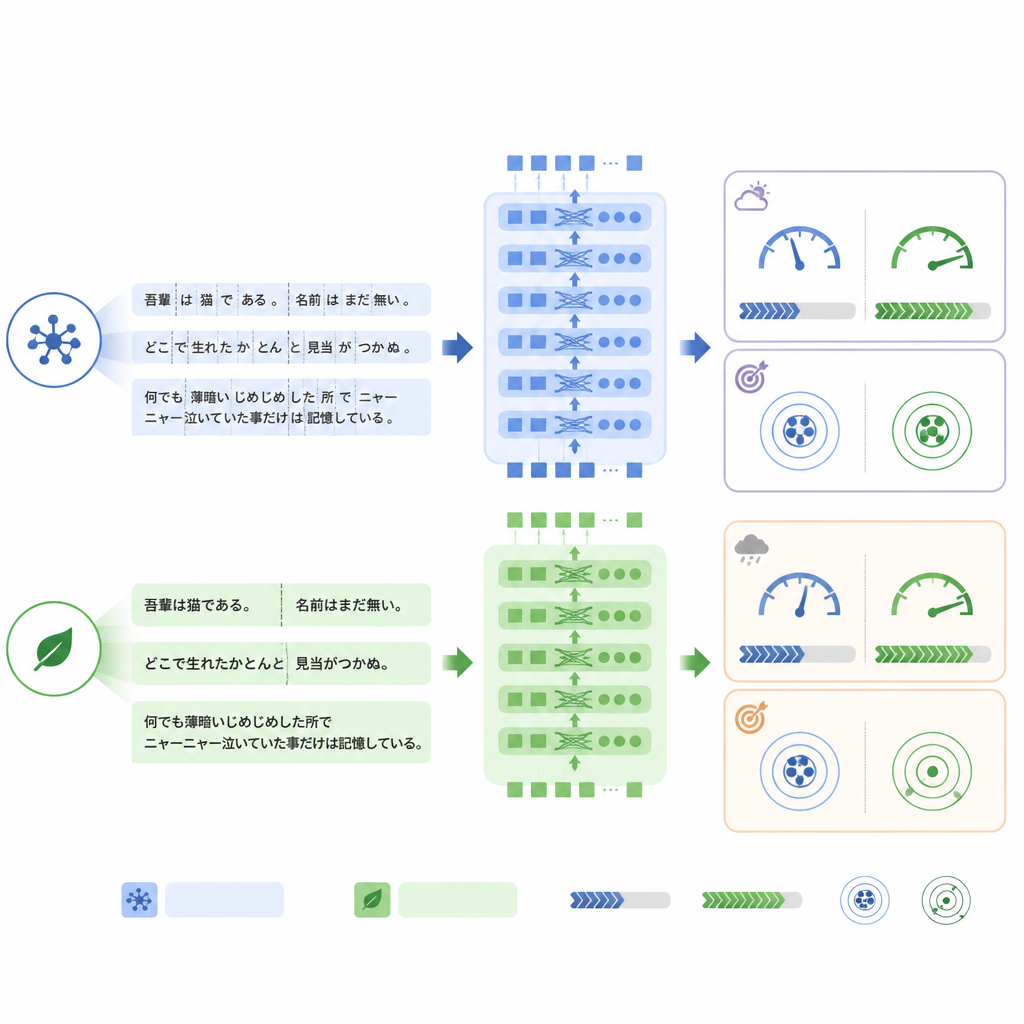
When language style shifts, stability matters
The picture changed when the models were tested on the real‑world RR‑Findings dataset. Here, standard BERT achieved the best exact‑match accuracy, while ModernBERT showed the largest drop compared with its performance on translated reports. Detailed analysis suggested that ModernBERT struggled more when radiologists used different wording than it had seen during training, for example calling scarring “chronic inflammatory change” instead of using a direct term, or relying on abbreviations like GGN for certain nodules. Yet its ranking of which findings were more or less likely remained reasonably good, suggesting that its confidence thresholds, rather than its basic ability to distinguish patterns, were particularly sensitive to this change in language style.
What this means for hospital AI tools
For hospitals that want local, private AI tools to sift through radiology reports, ModernBERT offers clear advantages in speed and computing cost, especially for longer texts. On well‑matched data, it can match or slightly exceed the accuracy of older models while using fewer resources. However, this study also shows that efficiency alone is not enough: models must be trained and calibrated on a wide range of natural clinical language if they are to handle the messy reality of everyday reporting. The authors conclude that ModernBERT is a strong, efficient option for Japanese radiology text, but future work should add more diverse training data and smarter tuning so that fast models remain reliable even when writing styles and patient populations change.
Citation: Yamagishi, Y., Kikuchi, T., Hanaoka, S. et al. ModernBERT is more efficient than conventional BERT for chest CT findings classification in Japanese radiology reports. Sci Rep 16, 15956 (2026). https://doi.org/10.1038/s41598-026-44292-z
Keywords: radiology reports, Japanese medical AI, BERT, ModernBERT, chest CT findings