Clear Sky Science · pl
ModernBERT jest wydajniejszy niż konwencjonalny BERT w klasyfikacji zmian w RTG klatki piersiowej w japońskich raportach radiologicznych
Dlaczego szybsze czytanie raportów medycznych ma znaczenie
Codziennie szpitale generują tysiące raportów radiologicznych opisujących obserwacje widoczne na skanach. Przekształcenie tych notatek w wolnym tekście w ustrukturyzowane informacje może wspierać badania, kontrolę jakości, a także przyszłe systemy AI wspomagające diagnozę. Komputery muszą jednak najpierw „zrozumieć” język, co jest szczególnie trudne w japońskich tekstach medycznych ze względu na mieszankę terminów specjalistycznych, skrótów i fraz angielskich. W tym badaniu pytano, czy nowszy model językowy o nazwie ModernBERT może czytać japońskie raporty TK klatki piersiowej bardziej wydajnie niż starsze, powszechnie używane modele BERT, nie tracąc przy tym dokładności.
Jak komputery uczą się czytać raporty ze skanów
Aby uczciwie porównać modele, badacze skupili się na konkretnym zadaniu: zdecydować dla każdego raportu TK, które z 18 możliwych zmian występują, na przykład guzki płucne, rozedma czy płyn w jamie opłucnej. Wykorzystali dużą publiczną bazę danych CT‑RATE‑JPN, zawierającą ponad 22 000 przetłumaczonych raportów TK w języku japońskim, z których każdy został opisany przez ekspertów. Większość raportów posłużyła do trenowania i strojenia trzech modeli: standardowego BERTa, medycznie ukierunkowanego JMedRoBERTa oraz ModernBERT. Osobny zestaw 150 raportów służył do testowania, jak dobrze każdy model potrafi przypisać prawidłową kombinację zmian.
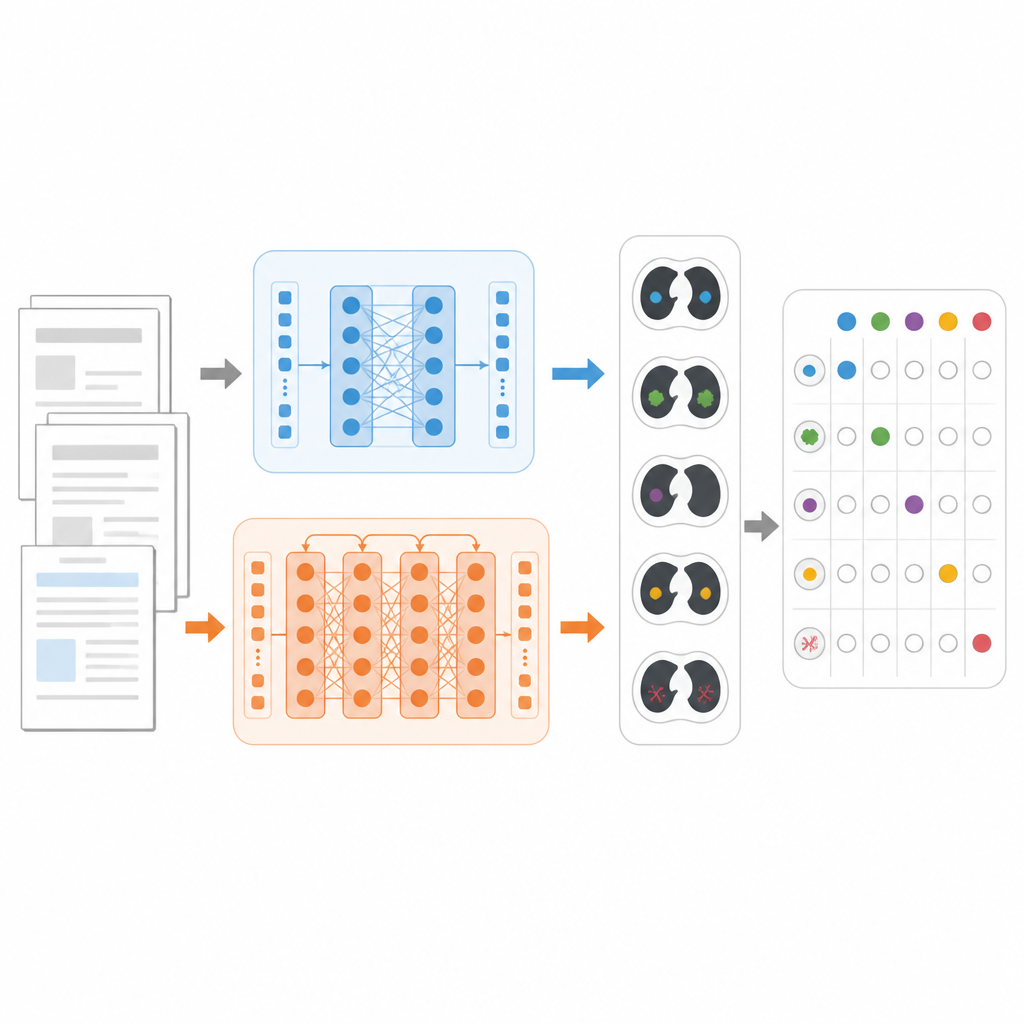
Budowa trudniejszego testu rzeczywistego
Ponieważ raporty tłumaczone mogą być bardziej jednorodne niż codzienne zapisy kliniczne, zespół zbudował także nowy zewnętrzny zbiór danych o nazwie RR‑Findings. Te 243 japońskie raporty pochodzą z rzeczywistych przypadków raka płuca sporządzonych przez dziewięciu certyfikowanych radiologów. Każdy raport został opisany tymi samymi 18 zmianami przy użyciu starannego, dwuetapowego procesu przeglądu przez doświadczonych lekarzy. W przeciwieństwie do przetłumaczonego zestawu, raporty te zawierają zróżnicowane style, parafrazy i skróty, które odzwierciedlają rzeczywisty sposób, w jaki radiolodzy piszą w praktyce, co czyni RR‑Findings mocniejszym testem zdolności modeli do radzenia sobie z naturalnymi różnicami językowymi.
Zyski prędkości dzięki krótszym „słownym” fragmentom
Kluczowa różnica między modelami polega na tym, jak dzielą tekst na fragmenty, czyli tokeny, przed przetwarzaniem. ModernBERT używa znacznie bogatszego słownika, który bardziej efektywnie obsługuje japońskie terminy i mieszane frazy angielskie, dzięki czemu potrzebuje mniej tokenów do reprezentacji tego samego raportu. W wewnętrznym zestawie testowym ModernBERT zmniejszył średnią liczbę tokenów o około jedną czwartą w porównaniu z BERTem. Mniejsza liczba tokenów oznaczała szybsze obliczenia: ModernBERT przetwarzał około półtora raza więcej raportów na sekundę zarówno podczas trenowania, jak i testowania, i zakończył pełne treningi w znacznie krótszym czasie niż pozostałe modele. Co ważne, ta efektywność nie odbyła się kosztem wyników na zadaniu wewnętrznym: wszystkie trzy modele osiągnęły podobną dokładność, z niewielką przewagą ModernBERTa w surowej miarze „wszystkie etykiety poprawne”.
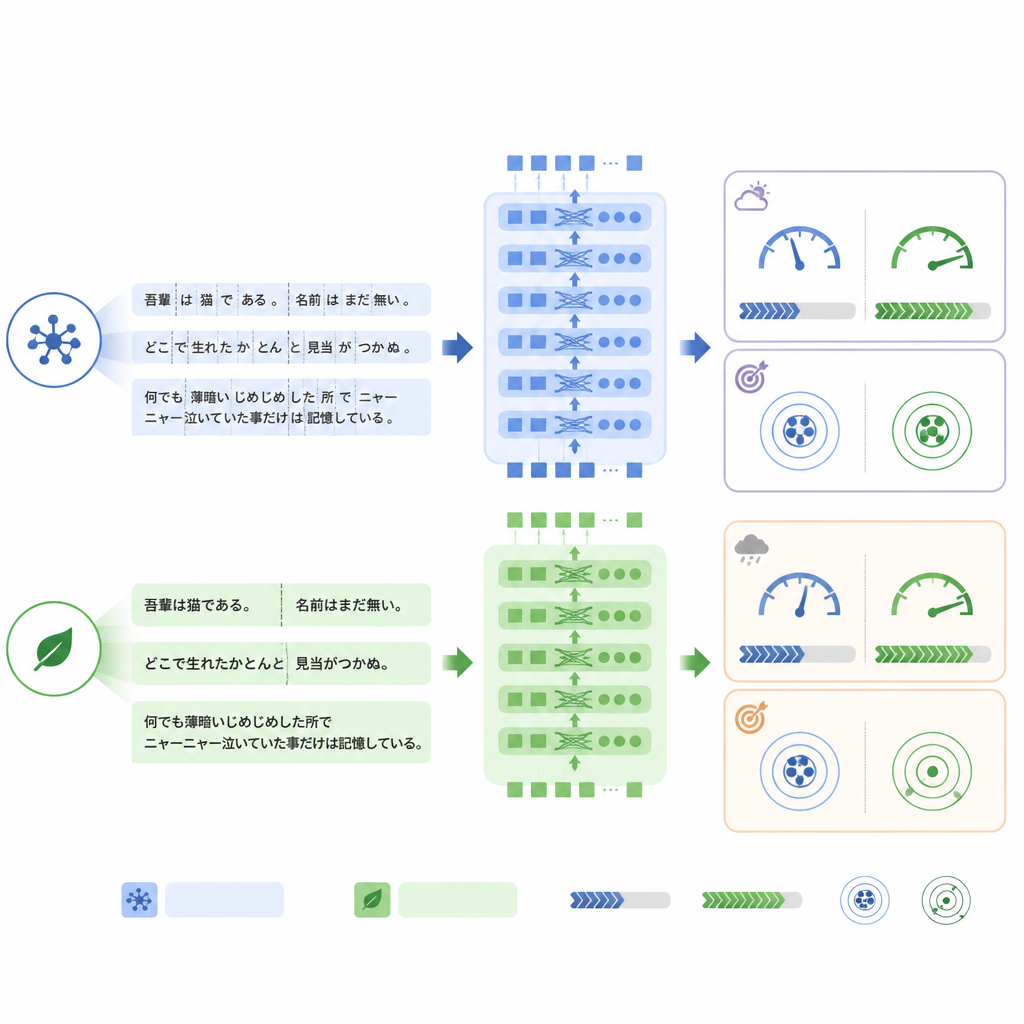
Gdy styl języka się zmienia, stabilność ma znaczenie
Obraz zmienił się, gdy modele przetestowano na rzeczywistym zbiorze RR‑Findings. W tym przypadku standardowy BERT osiągnął najlepszą dokładność dopasowania dokładnego, podczas gdy ModernBERT wykazał największy spadek w porównaniu ze swoją wydajnością na przetłumaczonych raportach. Szczegółowa analiza sugerowała, że ModernBERT miał większe trudności, gdy radiolodzy używali innego słownictwa niż to, które widział podczas treningu — na przykład nazywając bliznowacenie „przewlekłą zmianą zapalną” zamiast użycia bezpośredniego terminu, lub stosując skróty jak GGN dla niektórych guzków. Mimo to jego ranking, które zmiany są bardziej lub mniej prawdopodobne, pozostał stosunkowo dobry, co sugeruje, że to progi ufności, a nie podstawowa zdolność rozróżniania wzorców, były szczególnie wrażliwe na zmianę stylu języka.
Co to oznacza dla narzędzi AI w szpitalach
Dla szpitali, które chcą wdrożyć lokalne, prywatne narzędzia AI do przeszukiwania raportów radiologicznych, ModernBERT oferuje wyraźne korzyści w zakresie szybkości i kosztów obliczeniowych, zwłaszcza dla dłuższych tekstów. Na dobrze dopasowanych danych może dorównać, a nawet nieznacznie przewyższyć dokładność starszych modeli przy użyciu mniejszych zasobów. Jednak badanie pokazuje także, że sama wydajność nie wystarcza: modele muszą być trenowane i kalibrowane na szerokim spektrum naturalnego języka klinicznego, aby radzić sobie z chaosem codziennego raportowania. Autorzy konkludują, że ModernBERT jest silną, wydajną opcją dla japońskich tekstów radiologicznych, lecz przyszłe prace powinny rozszerzyć różnorodność danych treningowych i zastosować inteligentniejsze strojenie, aby szybkie modele pozostały niezawodne nawet przy zmianach stylów pisania i populacji pacjentów.
Cytowanie: Yamagishi, Y., Kikuchi, T., Hanaoka, S. et al. ModernBERT is more efficient than conventional BERT for chest CT findings classification in Japanese radiology reports. Sci Rep 16, 15956 (2026). https://doi.org/10.1038/s41598-026-44292-z
Słowa kluczowe: raporty radiologiczne, japońska medyczna sztuczna inteligencja, BERT, ModernBERT, znaleziska w TK klatki piersiowej