Clear Sky Science · sv
ModernBERT är mer effektivt än konventionell BERT för klassificering av fynd i bröstkorgs‑CT i japanska radiologiska rapporter
Varför snabbare läsning av medicinska rapporter spelar roll
Varje dag genererar sjukhus tusentals radiologirapporter som beskriver vad läkare ser på bilderna. Att omvandla dessa fria textanteckningar till strukturerad information kan hjälpa forskning, kvalitetskontroll och till och med framtida AI‑system som stödjer diagnos. Men datorer måste först "förstå" språket, vilket är särskilt svårt för japansk medicinsk text med sin blandning av fackspråk, förkortningar och engelska fraser. Denna studie undersöker om en nyare språkmodell kallad ModernBERT kan läsa japanska bröstkorgs‑CT‑rapporter mer effektivt än äldre, allmänt använda BERT‑modeller utan att tappa i noggrannhet.
Hur datorer lär sig läsa skanningsrapporter
För att jämföra modeller rättvist fokuserade forskarna på en konkret uppgift: avgöra, för varje bröstkorgs‑CT‑rapport, vilka av 18 möjliga fynd som förekommer, såsom lungnoduli, emfysem eller vätska runt lungorna. De använde en stor offentlig datamängd kallad CT‑RATE‑JPN, som innehåller över 22 000 översatta bröstkorgs‑CT‑rapporter på japanska, var och en märkta av experter. De flesta rapporterna användes för att träna och finjustera tre modeller: en standard‑BERT, en medicinskt inriktad JMedRoBERTa och ModernBERT. En separat uppsättning om 150 rapporter testade hur väl varje modell kunde tilldela rätt kombination av fynd.
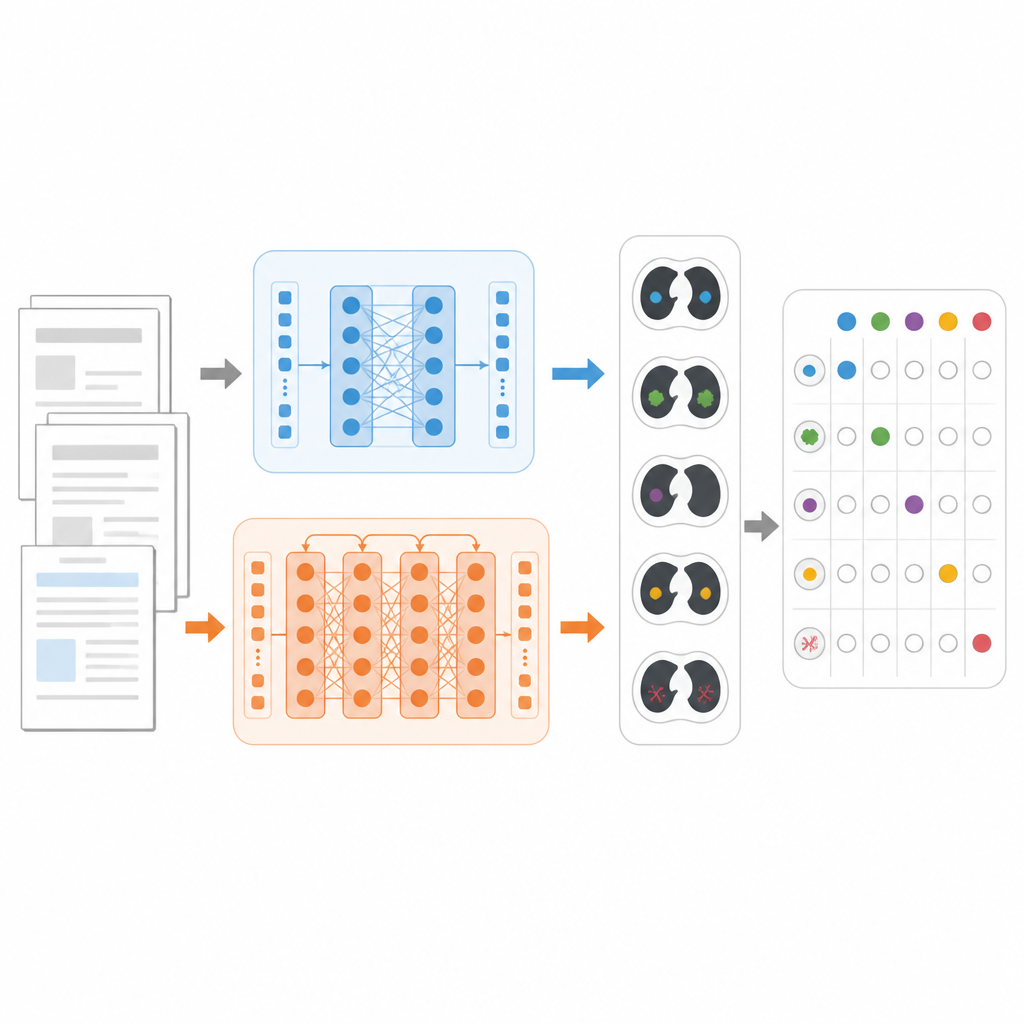
Att bygga ett tuffare verklighetstest
Eftersom översatta rapporter kan vara mer enhetliga än vardagligt kliniskt skrivande byggde teamet också en ny extern datamängd kallad RR‑Findings. Dessa 243 japanska rapporter kommer från verkliga lungcancerfall skrivna av nio styrelsecertifierade radiologer. Varje rapport märktes med samma 18 fynd genom en noggrann tvåstegsgranskning av erfarna läkare. Till skillnad från den översatta datamängden innehåller dessa rapporter varierande stilar, omskrivningar och förkortningar som speglar hur radiologer faktiskt skriver i praktiken, vilket gör RR‑Findings till ett starkare test av hur väl modeller hanterar naturliga språkliga variationer.
Hastighetsvinster från kortare "ord"‑bitar
En nyckelskillnad mellan modellerna ligger i hur de delar upp text i bitar, eller tokens, innan bearbetning. ModernBERT använder ett mycket rikare vokabulär som hanterar japanska termer och blandade engelska fraser mer effektivt, så det behövs färre tokens för att representera samma rapport. I den interna testuppsättningen minskade ModernBERT det genomsnittliga antalet tokens med ungefär en fjärdedel jämfört med BERT. Färre tokens innebar snabbare beräkning: ModernBERT bearbetade cirka en och två‑tredjedelar gånger så många rapporter per sekund under både träning och testning, och avslutade full träning på betydligt kortare tid än de andra modellerna. Viktigt är att denna effektivitet inte kom på bekostnad av den interna uppgiftens prestanda: alla tre modeller nådde liknande noggrannhet, med ModernBERT något före i den strikta "alla etiketter korrekta"‑mätningen.
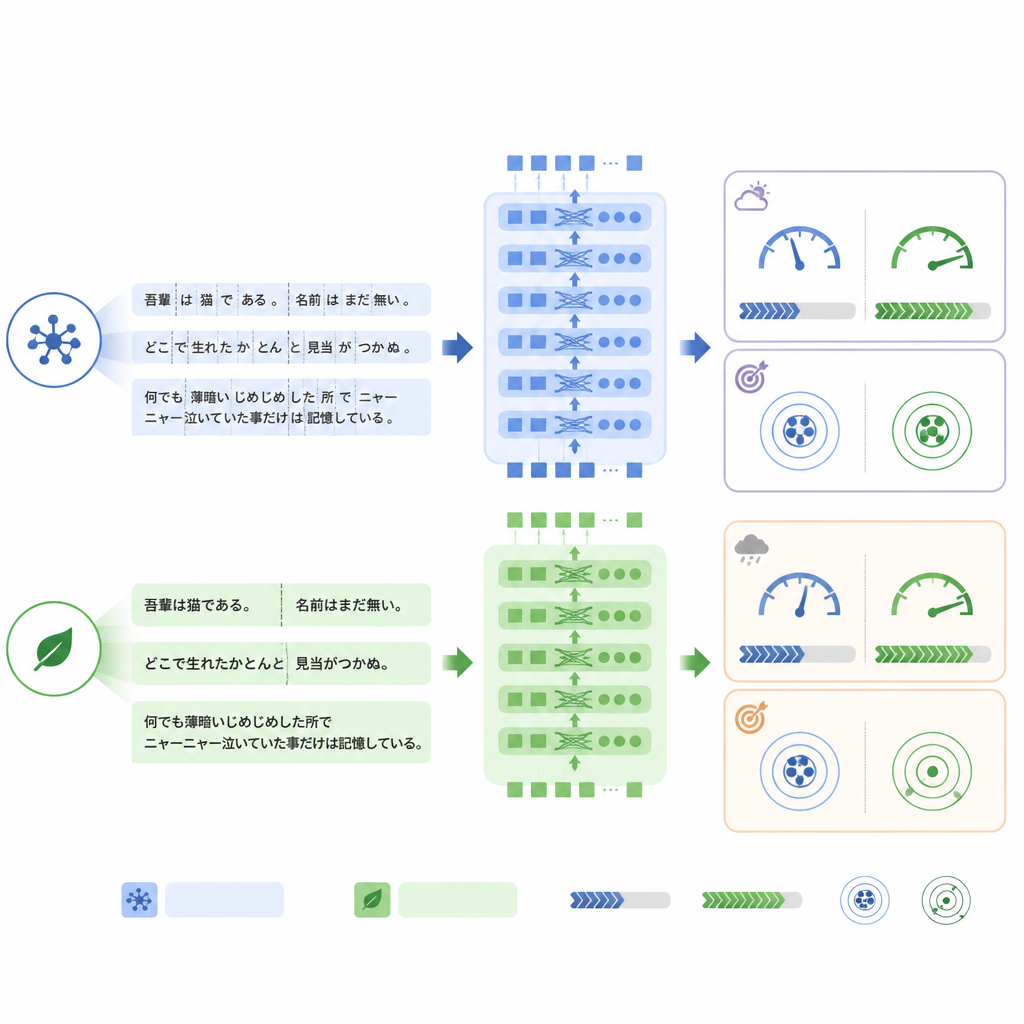
När språklig stil skiftar blir stabilitet viktig
Bilden förändrades när modellerna testades på den verkliga RR‑Findings‑datamängden. Här uppnådde standard‑BERT bäst träffsäkerhet för exakt matchning, medan ModernBERT visade den största nedgången jämfört med sin prestanda på översatta rapporter. Detaljerad analys tyder på att ModernBERT hade svårare när radiologer använde annat ordval än det modellen sett under träning — till exempel att kalla ärrbildning för "kronisk inflammatorisk förändring" istället för en mer direkt term, eller att förlita sig på förkortningar som GGN för vissa noduli. Trots detta var modellens rangordning av vilka fynd som var mer eller mindre sannolika rimligt bra, vilket antyder att dess konfidenströsklar, snarare än dess grundläggande förmåga att skilja mönster, var särskilt känsliga för denna förändring i språkstil.
Vad detta betyder för AI‑verktyg på sjukhus
För sjukhus som vill ha lokala, privata AI‑verktyg för att sålla igenom radiologirapporter erbjuder ModernBERT tydliga fördelar i hastighet och beräkningskostnad, särskilt för längre texter. På välmatchade data kan det nå eller något överträffa noggrannheten hos äldre modeller samtidigt som färre resurser används. Studien visar dock också att effektivitet ensam inte räcker: modeller måste tränas och kalibreras på ett brett spektrum av naturligt kliniskt språk för att hantera verklighetens röriga rapportering. Författarna drar slutsatsen att ModernBERT är ett starkt, effektivt alternativ för japansk radiologisk text, men att framtida arbete bör tillföra mer varierad träningsdata och smartare finjusteringar så att snabba modeller förblir tillförlitliga även när skrivsätt och patientpopulationer förändras.
Citering: Yamagishi, Y., Kikuchi, T., Hanaoka, S. et al. ModernBERT is more efficient than conventional BERT for chest CT findings classification in Japanese radiology reports. Sci Rep 16, 15956 (2026). https://doi.org/10.1038/s41598-026-44292-z
Nyckelord: radiologirapporter, japansk medicinsk AI, BERT, ModernBERT, fynd i bröstkorgs‑CT