Clear Sky Science · nl
ModernBERT is efficiënter dan conventionele BERT voor classificatie van borstkas‑CT‑bevindingen in Japanse radiologierapporten
Waarom sneller lezen van medische rapporten ertoe doet
Dagelijks genereren ziekenhuizen duizenden radiologierapporten die beschrijven wat artsen op scans zien. Het omzetten van deze vrije‑tekstnotities naar gestructureerde informatie kan helpen bij onderzoek, kwaliteitscontrole en zelfs toekomstige AI‑systemen die bij de diagnose ondersteunen. Maar computers moeten de taal eerst “begrijpen”, wat bijzonder lastig is voor Japanse medische teksten door de mix van vaktermen, afkortingen en Engelse termen. Deze studie onderzoekt of een nieuwer taalmodel, ModernBERT, Japanse borstkas‑CT‑rapporten efficiënter kan lezen dan de oudere, veelgebruikte BERT‑modellen zonder nauwkeurigheid te verliezen.
Hoe computers leren scanrapporten lezen
Om modellen eerlijk te vergelijken richtten de onderzoekers zich op een concrete taak: voor elk borstkas‑CT‑rapport bepalen welke van 18 mogelijke bevindingen aanwezig zijn, zoals longknobbels, emfyseem of vocht rond de longen. Ze gebruikten een grote openbare dataset genaamd CT‑RATE‑JPN, met meer dan 22.000 vertaalde borstkas‑CT‑rapporten in het Japans, ieder gelabeld door deskundigen. De meeste rapporten werden gebruikt om drie modellen te trainen en te verfijnen: een standaard BERT, een medisch gefocuste JMedRoBERTa en ModernBERT. Een aparte set van 150 rapporten testte hoe goed elk model de juiste combinatie van bevindingen kon toewijzen.
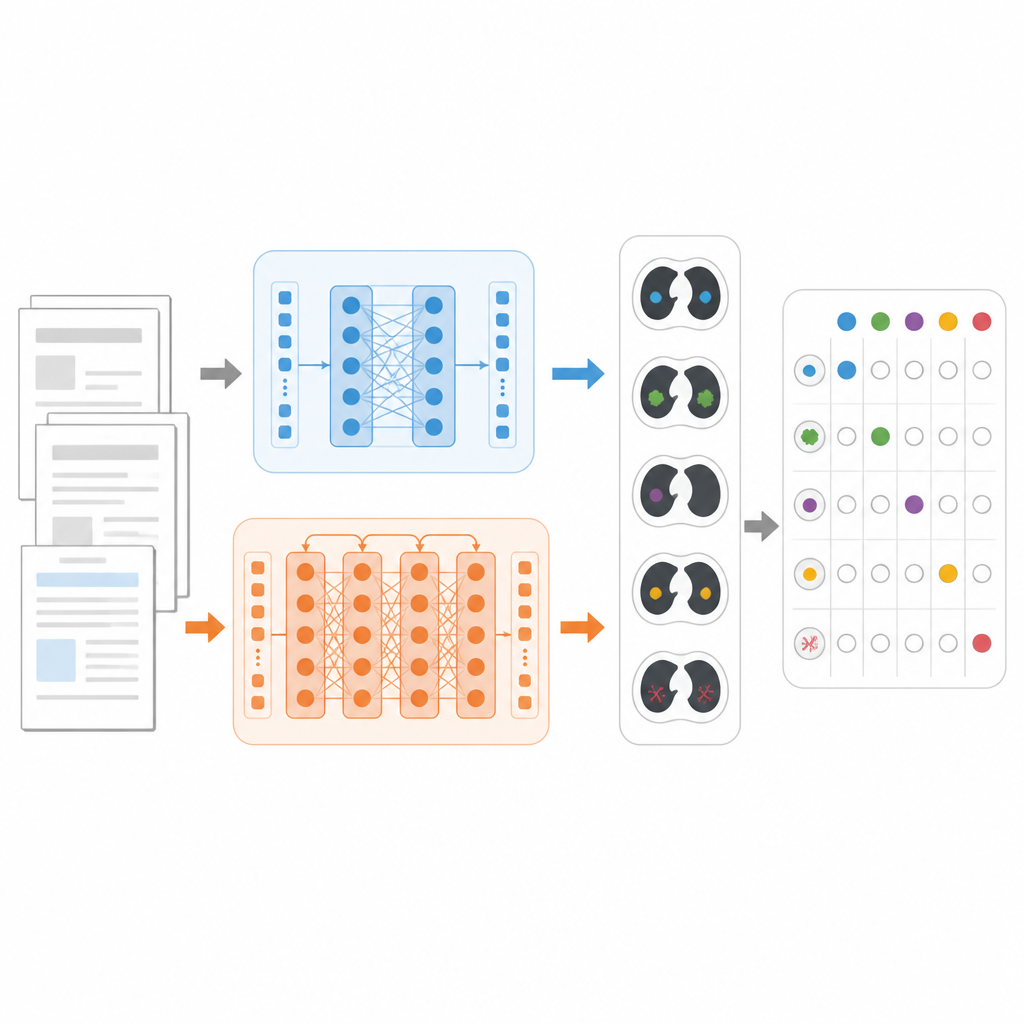
Het bouwen van een zwaardere real‑world test
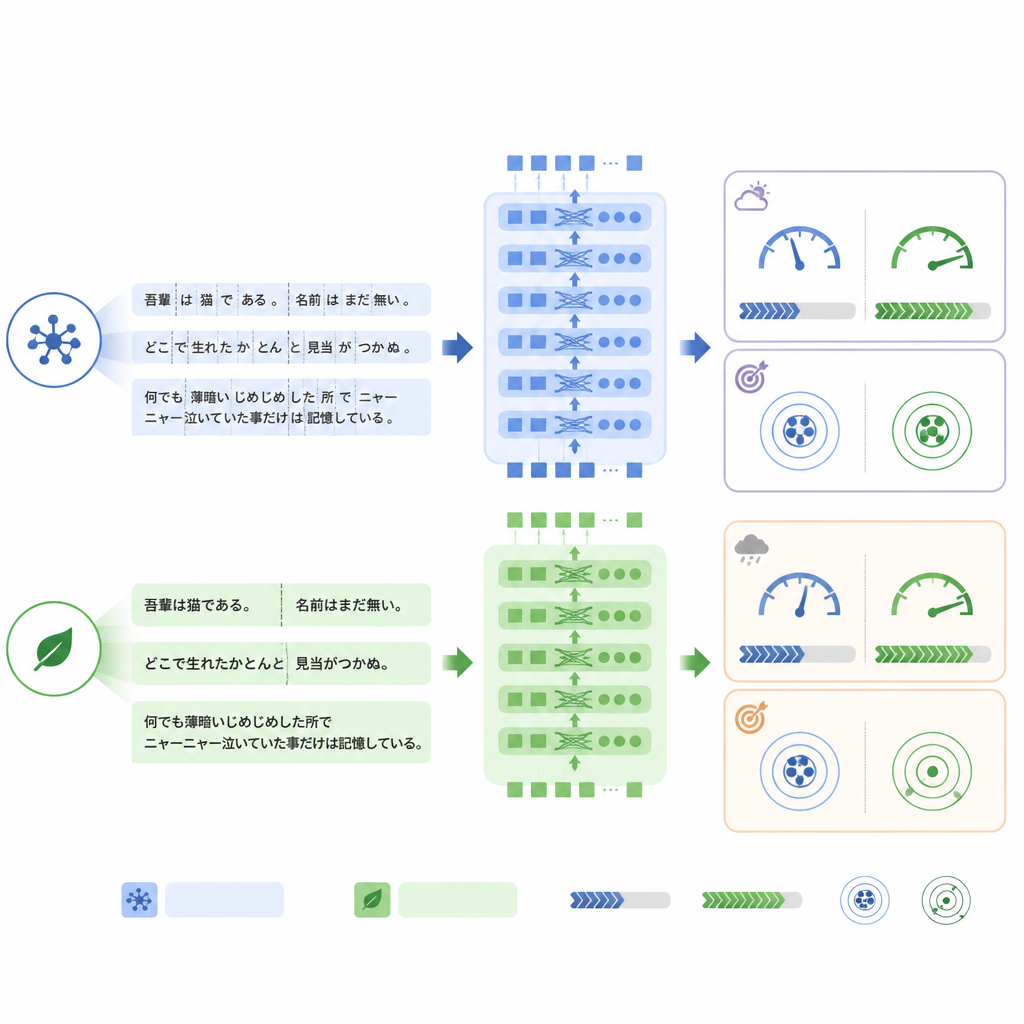
Aangezien vertaalde rapporten uniformer kunnen zijn dan alledaagse klinische schrijfstijl, bouwde het team ook een nieuwe externe dataset genaamd RR‑Findings. Deze 243 Japanse rapporten stammen uit echte longkankergevallen en zijn geschreven door negen gecertificeerde radiologen. Elk rapport werd gelabeld met dezelfde 18 bevindingen via een zorgvuldige tweestaps beoordelingsproces door ervaren artsen. In tegenstelling tot de vertaalde dataset bevatten deze rapporten uiteenlopende stijlen, parafraseringen en afkortingen die weerspiegelen hoe radiologen in de praktijk daadwerkelijk schrijven, waardoor RR‑Findings een zwaardere test is voor hoe modellen omgaan met natuurlijke taalverschillen.
Winst in snelheid door kortere “woord”chunks
Een belangrijk verschil tussen de modellen zit in hoe ze tekst in stukjes, of tokens, opdelen voordat ze verwerken. ModernBERT gebruikt een veel rijkere woordenschat die Japanse termen en gemengde Engelse uitdrukkingen efficiënter afhandelt, zodat het minder tokens nodig heeft om hetzelfde rapport weer te geven. In de interne testset verlaagde ModernBERT het gemiddelde aantal tokens met ongeveer een kwart vergeleken met BERT. Minder tokens betekende snellere berekeningen: ModernBERT verwerkte tijdens zowel training als testen ongeveer anderhalve tot tweemaal zoveel rapporten per seconde, en voltooide de volledige training in veel minder tijd dan de andere modellen. Belangrijk is dat deze efficiëntie niet ten koste ging van de interne taak: alle drie de modellen bereikten vergelijkbare nauwkeurigheid, met ModernBERT licht voorop in de strikte maat “alle labels correct”.
Wanneer taalstijl verschuift, is stabiliteit belangrijk
Het beeld veranderde toen de modellen werden getest op de real‑world RR‑Findings dataset. Hier behaalde de standaard BERT de beste exact‑match nauwkeurigheid, terwijl ModernBERT de grootste daling liet zien vergeleken met zijn prestaties op de vertaalde rapporten. Gedetailleerde analyse suggereerde dat ModernBERT meer moeite had wanneer radiologen andere bewoording gebruikten dan tijdens de training was gezien, bijvoorbeeld door littekens te beschrijven als “chronische inflammatoire verandering” in plaats van een directer term te gebruiken, of door afkortingen zoals GGN voor bepaalde noduli te hanteren. Toch bleef zijn rangorde van welke bevindingen waarschijnlijker waren redelijk goed, wat suggereert dat het vooral de drempelwaarden voor vertrouwen, in plaats van het basale vermogen om patronen te onderscheiden, waren die gevoelig waren voor deze verandering in taalstijl.
Wat dit betekent voor AI‑hulpmiddelen in ziekenhuizen
Voor ziekenhuizen die lokale, private AI‑hulpmiddelen willen inzetten om radiologierapporten door te nemen, biedt ModernBERT duidelijke voordelen in snelheid en rekencapaciteit, vooral voor langere teksten. Op goed overeenkomende data kan het de nauwkeurigheid van oudere modellen evenaren of licht overtreffen terwijl het minder middelen gebruikt. Deze studie toont echter ook aan dat efficiëntie alleen niet voldoende is: modellen moeten op een breed scala aan natuurlijke klinische taal worden getraind en gekalibreerd om de rommelige realiteit van dagelijkse rapportage aan te kunnen. De auteurs concluderen dat ModernBERT een sterk, efficiënt optie is voor Japanse radiologietekst, maar dat toekomstig werk meer diverse trainingsgegevens en slimmere afstemming moet toevoegen zodat snelle modellen betrouwbaar blijven wanneer schrijfstijlen en patiëntpopulaties veranderen.
Bronvermelding: Yamagishi, Y., Kikuchi, T., Hanaoka, S. et al. ModernBERT is more efficient than conventional BERT for chest CT findings classification in Japanese radiology reports. Sci Rep 16, 15956 (2026). https://doi.org/10.1038/s41598-026-44292-z
Trefwoorden: radiologierapporten, Japanse medische AI, BERT, ModernBERT, borstkas‑CT‑bevindingen