Clear Sky Science · tr
KinForm: enzim kcat ve KM tahmini için kinetik bilgili özellik optimize edilmiş temsil modelleri
Enzimin hızını tahmin etmenin neden önemi var
Her canlı hücre, kimyasal reaksiyonları yönlendiren küçük protein makineler olan enzimlere dayanır. Bu enzimlerin ne kadar hızlı çalıştığı ve ortaklarına ne kadar sıkı bağlandığı, yiyecekleri nasıl metabolize ettiğimizden mikroorganizmaların biyoyakıt üretimine kadar pek çok şeyi şekillendirir. Bu kinetik özellikleri laboratuvarda tek tek ölçmek yavaş ve eksik kalır. Bu makale, bilinen örneklerden öğrenerek çok daha fazla protein için enzim davranışını tahmin etmeyi sağlayan ve biyologlar ile mühendislerin karmaşık biyokimyasal sistemleri daha etkili tasarlayıp analiz etmesine yardımcı olabilecek KinForm adlı bir makine öğrenimi yaklaşımını anlatıyor.
Enzimlerin bize söylemesi gerekenler
Enzim davranışını anlamada iki sayısal özellik merkezi bir rol oynar. İlk özellik, sıklıkla dönüşüm sayısı (turnover number) olarak adlandırılır ve bir enzimin belirli bir zaman içinde kaç reaksiyon döngüsü tamamlayabildiğini tanımlar. İkinci özellik ise enzimin ortak moleküle ne kadar sıkı bağlandığıyla ilgili olup reaksiyonların ne kadar kolay başlatılacağını yansıtır. Biyologlar bu değerleri metabolizmanın bilgisayar modellerini kurmak, mikroorganizmaların büyümesini tahmin etmek veya yeşil kimya için yeni yollar tasarlamak için kullanır. Ancak veri tabanları, bilinen tüm enzimlerin yalnızca küçük bir kısmı için ayrıntılı ölçümler içerir ve çoğu kayıt birkaç iyi incelenmiş protein ailesine odaklanır. Bu yamalı kapsama hem temel araştırmayı hem de pratik uygulamaları sınırlar.
Bilgisayarlara proteinlerin dilini öğretmek
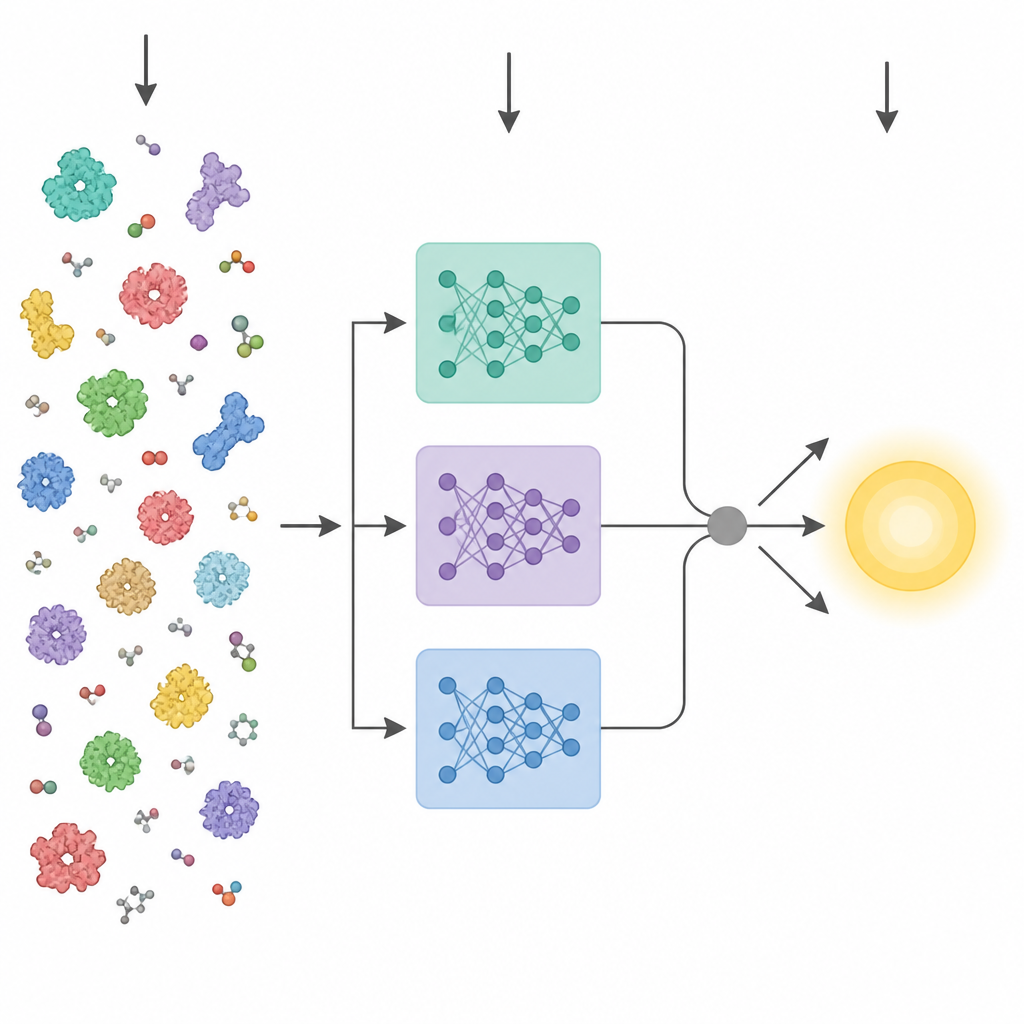
Yapay zekadaki son gelişmeler güçlü protein “dil modelleri” ortaya çıkardı. Bu araçlar milyonlarca ham amino asit dizisi üzerinde eğitilir ve deneysel etiketlere ihtiyaç duymadan üç boyutlu yapı ve işleve ilişkin desenleri öğrenir. Diziden enzim özelliklerini tahmin etmeye çalışan önceki yöntemler genellikle bu modellerin son katmanını tek bir ortalama vektöre indirger ve standart bir tahminciye beslerdi. KinForm daha nüanslı bir yol izler. Üç farklı protein dil modelinden yararlanır ve genellikle son katmandan daha faydalı bilgi taşıdığı görülen ara katmanlara odaklanır.
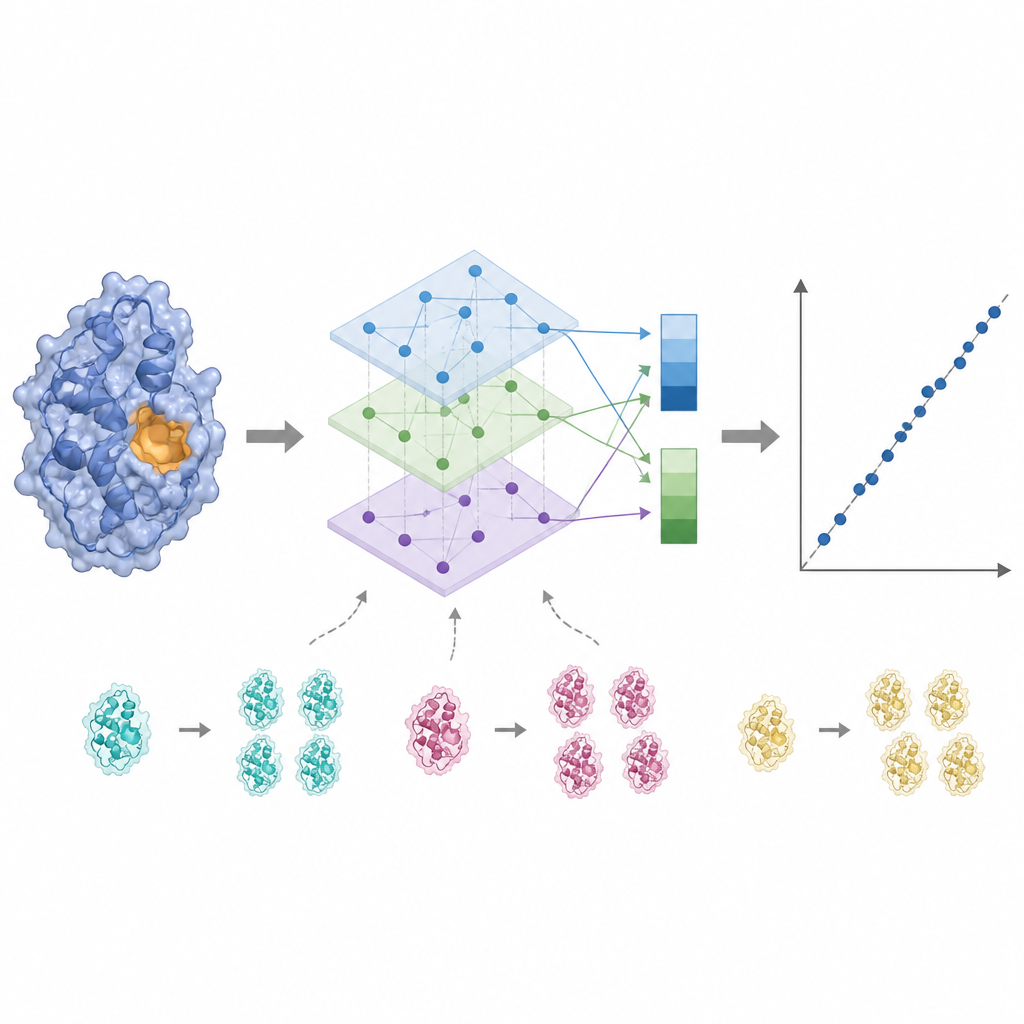
Aktif bölgeyi dinlemek ve gürültüyü budamak
Enzim aktivitesi genellikle bağlanma bölgesine yakın birkaç kilit kalıntı tarafından kontrol edilir; bu yüzden her amino asidi eşit görmek sinyali bulanıklaştırabilir. KinForm bunu, her kalıntının bağlanma bölgesine ait olma olasılığını puanlayan harici bir araç kullanarak düzeltir. Bu puanlar, dil modeli çıktıları ortalaması alınırken ağırlıklar olarak iş görür; böylece bütün proteini yansıtan bir vektör ile tahmin edilen aktif bölgeyi vurgulayan başka bir vektör elde edilir. Birkaç büyük modeli bu şekilde birleştirmek çok yüksek boyutlu veriler oluşturduğundan, KinForm daha sonra temel bileşen analizi uygular; bu istatistiksel teknik, tahmin için önemli olan çoğu varyasyonu korurken bilgiyi daha küçük bir koordinat setine sıkıştırır.
Benzerlikle başa çıkmak ve gerçek genelleme yeteneğini test etmek
Protein veri tabanları birbirine yakın dizilerle doludur; bu durum bir makine öğrenimi modelini ezberlemeye teşvik edebilir, oysa amaç genel kuralları öğrenmektir. KinForm bunu iki yolla ele alır. Birincisi, eğitim sırasında daha nadir ve düşük benzerlikli proteinleri kasıtlı olarak daha fazla örnekleyerek onların modele daha güçlü katkıda bulunmasını sağlar. İkincisi, yazarlar eğitim ve test kümeleri arasında herhangi bir dizi örtüşmesini engelleyen daha sıkı bir test şeması sunar. Bu daha zorlu koşullar altında, sıkıştırılmış temsiller ve dizi farkındalıklı örnekleme kullanan KinForm varyantları daha önceki yöntemlerden daha iyi performans gösterir; özellikle modelin daha önce görmediği, oldukça farklı enzim aileleri için fark belirgindir.
Sonuçların pratikte ne anlama geldiği
İki büyük enzim veri koleksiyonunda KinForm, önde gelen önceki bir modele kıyasla tahmin edilen dönüşüm sayıları ve bağlanma ile ilişkili sabitlerin doğruluğunu artırır. Kazançlar, verilerin en kıt olduğu ve tahminlerin en çok ihtiyaç duyulduğu uzak protein aileleri için en çarpıcıdır. Bu tahminler hücresel metabolizmanın ayrıntılı modellerine girildiğinde, genel davranıştaki iyileşmeler ılımlıdır; bu da diğer belirsizlik kaynaklarının hâlâ büyük rol oynadığını gösterir. Çalışma, dikkatle tasarlanmış protein temsillerinin ve daha gerçekçi test standartlarının yapay zekâ tabanlı kinetik tahminleri daha güvenilir kılabileceğini; aynı zamanda bu tahminlerin belirli bir ortam için kesin değerler değil, koşuldan bağımsız başlangıç noktaları olarak görülmesi gerektiğini vurgular.
Atıf: Alwer, S., Fleming, R.M.T. KinForm: kinetics-informed feature optimised representation models for enzyme kcat and KM prediction. npj Syst Biol Appl 12, 71 (2026). https://doi.org/10.1038/s41540-026-00692-5
Anahtar kelimeler: enzim kinetiği, protein dil modelleri, makine öğrenimi, metabolik modelleme, biyokimyasal tahmin