Clear Sky Science · ru
KinForm: модели представления признаков, информированные кинетикой, для предсказания kcat и KM ферментов
Почему важно предсказывать скорость ферментов
Каждая живая клетка зависит от ферментов — крошечных белковых машин, приводящих в действие химические реакции. Насколько быстро работают эти ферменты и насколько прочно они связываются со своими партнёрами определяет всё: от того, как мы усваиваем пищу, до того, как микроорганизмы синтезируют биотопливо. Измерять эти кинетические характеристики в лаборатории по одному ферменту — медленно и неполно. В этой статье описан KinForm, подход на основе машинного обучения, который учится на известных примерах и оценивает поведение больших массивов белков, что потенциально помогает биологам и инженерам проектировать и анализировать сложные биохимические системы более эффективно.
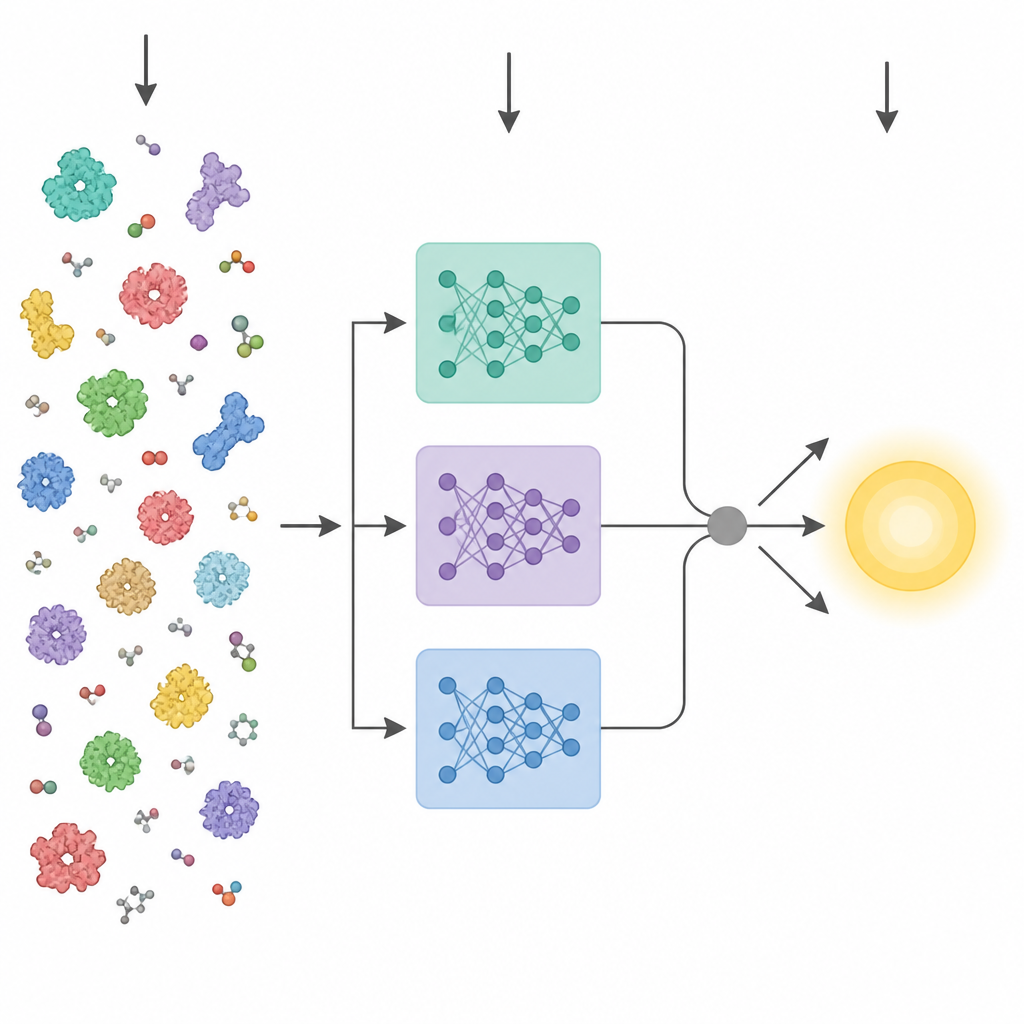
Что нужно знать о ферментах
Две числовые характеристики центральны для понимания поведения ферментов. Первая, часто называемая числом оборотов (turnover number), описывает, сколько циклов реакции фермент способен провести за единицу времени. Вторая, связанная с тем, насколько прочно фермент связывает молекулу-субстрат, отражает, насколько легко запускаются реакции. Биологи используют эти значения для построения компьютерных моделей метаболизма, прогнозирования роста микроорганизмов или планирования новых путей для «зелёной» химии. Однако в базах данных подробно измерены лишь небольшая доля всех известных ферментов, и большинство записей сосредоточены на нескольких хорошо изученных семействах белков. Такое фрагментарное покрытие ограничивает как фундаментальные исследования, так и практические приложения.
Обучение компьютеров языку белков
Недавние достижения в искусственном интеллекте породили мощные «языковые» модели белков. Эти инструменты обучаются на миллионах сырых аминокислотных последовательностей и усваивают закономерности, связанные с трёхмерной структурой и функцией, без необходимости в экспериментальных метках. Ранние методы, пытавшиеся предсказывать свойства ферментов по последовательности, обычно сводили последний слой такой модели к одному усреднённому вектору и подавали его в стандартный предиктор. KinForm идёт более тонким путём. Он использует три разные языковые модели белков и фокусируется на промежуточных слоях, которые оказываются более информативными для кинетического предсказания, чем привычный финальный слой.
Учет активного сайта и сокращение шума
Активность фермента часто контролируется лишь несколькими ключевыми остатками вблизи сайта связывания, поэтому равное отношение ко всем аминокислотам может размывать сигнал. KinForm исправляет это, используя внешний инструмент, который оценивает вероятность принадлежности каждого остатка к сайту связывания. Эти оценки выступают в роли весов при усреднении выходов языковых моделей, формируя один вектор, который отражает весь белок, и другой, подчеркивающий предсказанную активную область. Поскольку сочетание нескольких крупных моделей таким образом создаёт данные очень высокой размерности, KinForm затем применяет метод главных компонент (PCA) — статистический приём, сжимающий информацию в меньший набор координат, сохраняя при этом большую часть вариации, важной для предсказания.
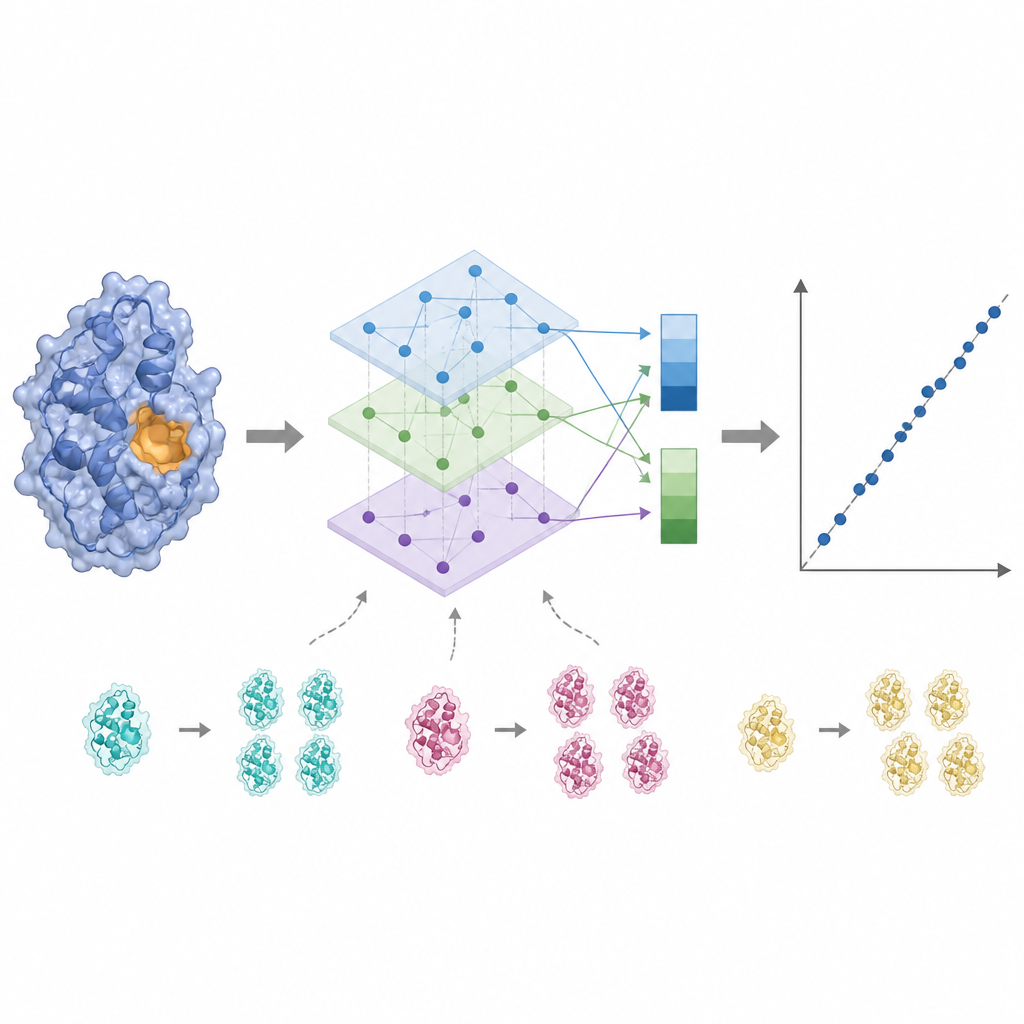
Управление сходством и проверка истинной обобщаемости
Белковые базы данных полны близкородственных последовательностей, что может склонять модель машинного обучения к запоминанию вместо выведения общих правил. KinForm решает эту проблему двумя способами. Во‑первых, при обучении он целенаправленно перевзвешивает образцы редких, низкосходных белков, чтобы они вносили больший вклад в модель. Во‑вторых, авторы вводят более строгую схему тестирования, исключающую любую пересекаемость последовательностей между обучающей и тестовой выборками. В таких жестких условиях варианты KinForm, использующие сжатые представления и выборку с учётом сходства последовательностей, показывают лучшие результаты по сравнению с прежними методами, особенно для ферментов, сильно отличающихся от всего, что модель видела ранее.
Что означают эти результаты на практике
На двух крупных эталонных наборах данных по ферментам KinForm повышает точность предсказаний чисел оборотов и констант, связанных со связыванием, по сравнению с ведущей предыдущей моделью. Улучшения наиболее заметны для отдалённых семейств белков, где данные наиболее скудны и прогнозы наиболее востребованы. Когда такие предсказания используют в детализированных моделях клеточного метаболизма, улучшения в общем поведении оказываются умеренными, что указывает на то, что другие источники неопределённости по‑прежнему играют большую роль. Работа демонстрирует, что тщательно продуманные представления белков и более реалистичные стандарты тестирования делают кинетические оценки на основе ИИ более надёжными, но также подчёркивает, что их следует рассматривать как нейтральные по условиям отправные точки, а не как точные значения для конкретной среды.
Цитирование: Alwer, S., Fleming, R.M.T. KinForm: kinetics-informed feature optimised representation models for enzyme kcat and KM prediction. npj Syst Biol Appl 12, 71 (2026). https://doi.org/10.1038/s41540-026-00692-5
Ключевые слова: кинетика ферментов, языковые модели белков, машинное обучение, моделирование метаболизма, биохимическое предсказание