Clear Sky Science · de
KinForm: kinetics-informed feature optimised representation models for enzyme kcat and KM prediction
Warum die Vorhersage der Enzymgeschwindigkeit wichtig ist
Jede lebende Zelle ist auf Enzyme angewiesen, winzige Proteine, die chemische Reaktionen antreiben. Wie schnell diese Enzyme arbeiten und wie stark sie an ihre Partner binden, bestimmt vieles — von der Nahrungsmittelverwertung bis zur Herstellung von Biokraftstoffen durch Mikroben. Diese kinetischen Eigenschaften im Labor einzeln zu messen, ist langsam und unvollständig. Dieser Artikel beschreibt KinForm, einen maschinellen Lernansatz, der aus bekannten Beispielen lernt, um das Verhalten vieler weiterer Proteine abzuschätzen und damit Biologen und Ingenieuren dabei helfen kann, komplexe biochemische Systeme effektiver zu entwerfen und zu analysieren.
Was Enzyme uns sagen müssen
Zwei numerische Merkmale sind zentral zum Verständnis enzymatischen Verhaltens. Das erste, oft als Umsatzzahl bezeichnet, beschreibt, wie viele Reaktionszyklen ein Enzym in einer bestimmten Zeitspanne ausführen kann. Das zweite, das mit der Bindungsstärke zwischen Enzym und Partnermolekül zusammenhängt, spiegelt wider, wie leicht Reaktionen gestartet werden. Biologen nutzen diese Werte, um Computermodelle des Stoffwechsels zu bauen, das Wachstum von Mikroben vorherzusagen oder neue Pfade für grüne Chemie zu planen. Datenbanken enthalten jedoch detaillierte Messungen nur für einen kleinen Anteil aller bekannten Enzyme, und die meisten Einträge konzentrieren sich auf einige gut untersuchte Proteinfamilien. Diese lückenhafte Abdeckung begrenzt sowohl die Grundlagenforschung als auch praktische Anwendungen.
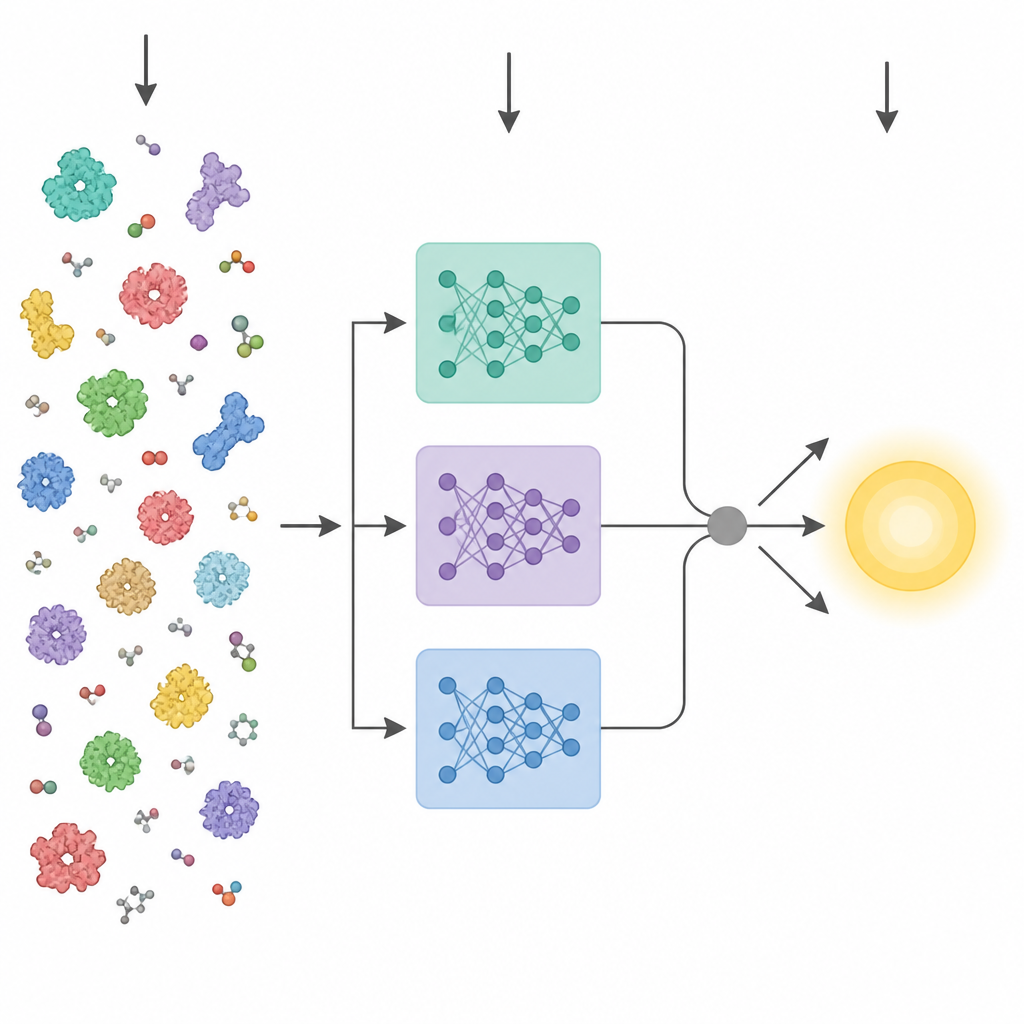
Computern die Sprache der Proteine beibringen
Jüngste Fortschritte in der künstlichen Intelligenz haben leistungsfähige Protein-„Sprachmodelle“ hervorgebracht. Diese Werkzeuge werden mit Millionen von Aminosäuresequenzen trainiert und lernen Muster, die mit dreidimensionaler Struktur und Funktion zusammenhängen, ohne experimentelle Labels zu benötigen. Frühere Methoden, die versuchten, Enzymeigenschaften aus Sequenzen vorherzusagen, fassten meist die letzte Schicht eines solchen Modells zu einem einzigen Mittelwertvektor zusammen und gaben ihn an einen Standardprädiktor weiter. KinForm wählt einen nuancierteren Ansatz: Es nutzt drei verschiedene Protein-Sprachmodelle und fokussiert sich auf Zwischenschichten, die sich als informativer für die kinetische Vorhersage erweisen als die übliche Endschicht.
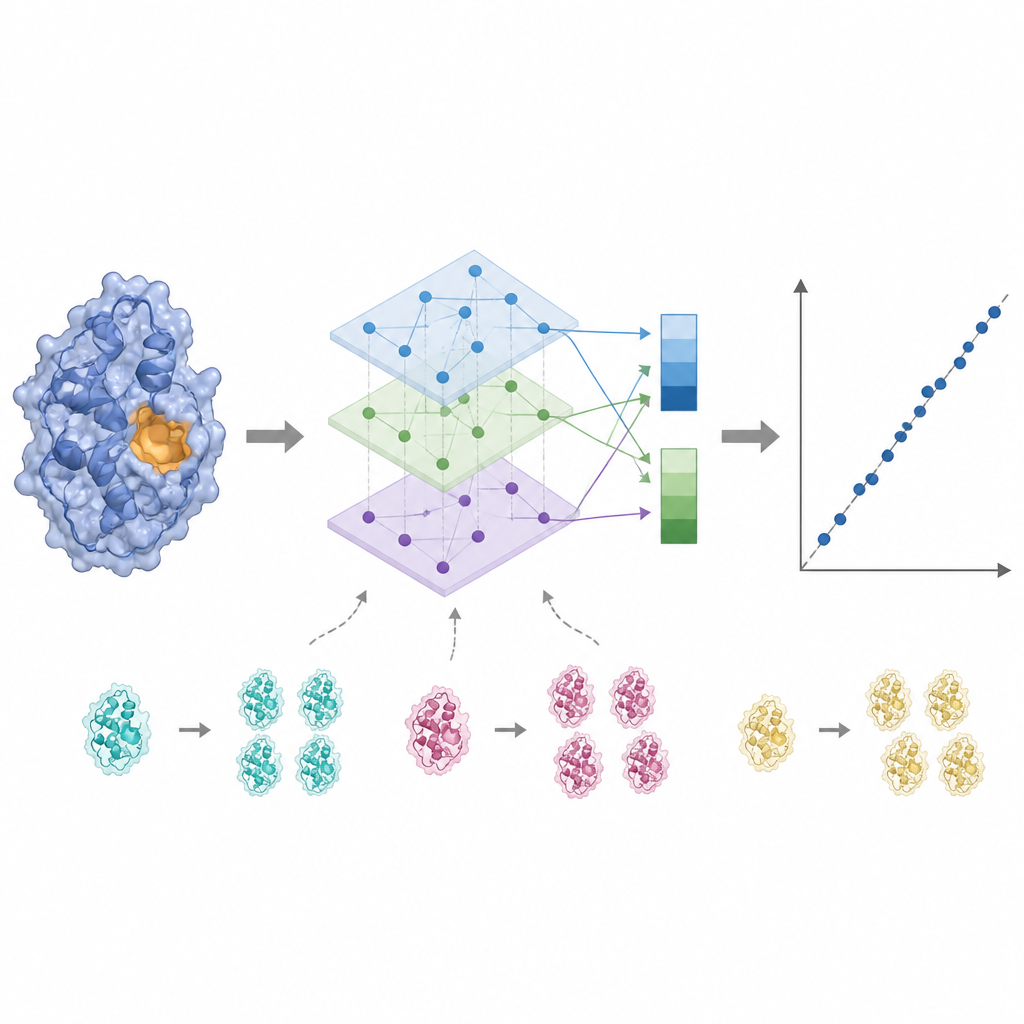
Auf das aktive Zentrum hören und Störsignale wegschneiden
Die Enzymaktivität wird oft nur von wenigen Schlüsselresten in der Nähe der Bindungsstelle gesteuert, weshalb eine gleichmäßige Behandlung aller Aminosäuren das Signal verwischen kann. KinForm korrigiert das, indem es ein externes Werkzeug verwendet, das bewertet, wie wahrscheinlich es ist, dass jedes Residuum zur Bindungsstelle gehört. Diese Bewertungen dienen als Gewichte beim Mittelwertbilden der Ausgaben der Sprachmodelle und erzeugen einen Vektor, der das gesamte Protein widerspiegelt, und einen weiteren, der die vorhergesagte aktive Region betont. Da die Kombination mehrerer großer Modelle auf diese Weise sehr hochdimensionale Daten erzeugt, wendet KinForm anschließend Hauptkomponentenanalyse an, eine statistische Technik, die die Informationen in ein kleineres Koordinatenset komprimiert und dabei den Großteil der für die Vorhersage relevanten Variation erhält.
Umgang mit Ähnlichkeit und Prüfung echter Generalisierung
Proteindatenbanken sind voller eng verwandter Sequenzen, was ein maschinelles Lernmodell dazu verleiten kann, auswendig zu lernen statt allgemeine Regeln zu erfassen. KinForm begegnet dem auf zwei Arten. Erstens oversampelt es während des Trainings gezielt seltener vorkommende, wenig ähnliche Proteine, damit diese stärker zum Modell beitragen. Zweitens führen die Autoren ein strengeres Testschema ein, das jede Überschneidung von Sequenzen zwischen Trainings- und Testsatz verhindert. Unter diesen härteren Bedingungen schneiden KinForm-Varianten, die komprimierte Repräsentationen und sequenzbewusstes Sampling verwenden, besser ab als frühere Methoden, insbesondere für Enzyme, die sich deutlich von allem unterscheiden, was das Modell zuvor gesehen hat.
Was die Ergebnisse in der Praxis bedeuten
Über zwei große Benchmark-Sammlungen enzymatischer Daten verbessert KinForm die Genauigkeit der vorhergesagten Umsatzzahlen und bindungsrelevanten Konstanten im Vergleich zu einem führenden früheren Modell. Die Verbesserungen sind am deutlichsten für entfernte Proteinfamilien, in denen Daten am knappsten sind und Vorhersagen am meisten benötigt werden. Wenn diese Vorhersagen in detaillierte Modelle des zellulären Stoffwechsels eingespeist werden, sind die Verbesserungen im Gesamtverhalten moderat, was darauf hindeutet, dass andere Unsicherheitsquellen weiterhin eine große Rolle spielen. Die Arbeit zeigt, dass sorgfältig gestaltete Proteinrepräsentationen und realistischere Teststandards KI-basierte kinetische Schätzungen zuverlässiger machen können, betont aber auch, dass sie als zustandsneutrale Ausgangspunkte und nicht als exakte Werte für eine spezifische Umgebung betrachtet werden sollten.
Zitation: Alwer, S., Fleming, R.M.T. KinForm: kinetics-informed feature optimised representation models for enzyme kcat and KM prediction. npj Syst Biol Appl 12, 71 (2026). https://doi.org/10.1038/s41540-026-00692-5
Schlüsselwörter: Enzymkinetik, Protein-Sprachmodelle, Maschinelles Lernen, Stoffwechselmodellierung, biochemische Vorhersage