Clear Sky Science · nl
KinForm: kinetics-informed feature optimised representation models voor voorspelling van enzym-kcat en KM
Waarom het voorspellen van enzym‑snelheid ertoe doet
Elke levende cel is afhankelijk van enzymen, kleine eiwitmachines die chemische reacties aandrijven. Hoe snel deze enzymen werken en hoe sterk ze zich aan hun partners hechten bepaalt alles, van hoe we voedsel metaboliseren tot hoe microben biobrandstoffen produceren. Het in het lab per enzym meten van deze kinetische eigenschappen is traag en onvolledig. Dit artikel beschrijft KinForm, een machine‑learning‑benadering die leert van bekende voorbeelden om het gedrag van veel meer eiwitten te schatten, wat biologen en ingenieurs kan helpen bij het ontwerpen en analyseren van complexe biochemische systemen.
Wat enzymen ons moeten vertellen
Twee numerieke eigenschappen zijn centraal voor het begrijpen van enzymgedrag. De eerste, vaak het turnover‑getal genoemd, beschrijft hoeveel reacties een enzym in een bepaalde tijd kan doorlopen. De tweede, gerelateerd aan hoe sterk een enzym bindt aan zijn partnermolecuul, weerspiegelt hoe gemakkelijk reacties op gang komen. Biologen gebruiken deze waarden om computermodellen van metabolisme te bouwen, om de groei van microben te voorspellen of om nieuwe routes voor groene chemie te plannen. Databases bevatten echter gedetailleerde metingen voor slechts een klein deel van alle bekende enzymen, en de meeste gegevens betreffen een paar goed bestudeerde eiwitfamilies. Deze onregelmatige dekking beperkt zowel fundamenteel onderzoek als praktische toepassingen.
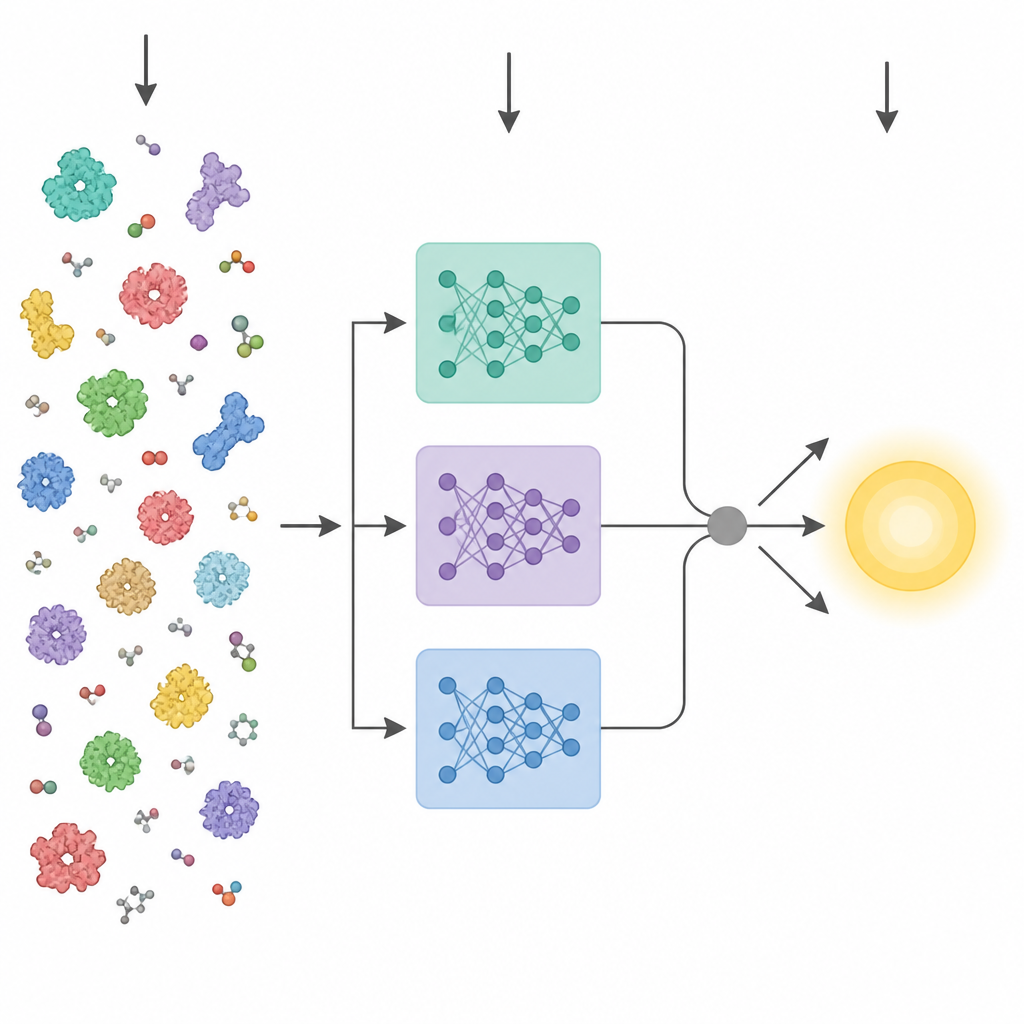
Computers het eiwit‑taalgebruik leren
Recente vorderingen in kunstmatige intelligentie hebben krachtige eiwit‑“taalmodellen” opgeleverd. Deze hulpmiddelen worden getraind op miljoenen ruwe aminozuursequenties en leren patronen die samenhangen met driedimensionale structuur en functie, zonder experimentele labels. Eerdere methoden die probeerden enzymeigenschappen uit sequentie te voorspellen, reduceerden gewoonlijk de laatste laag van zo’n model tot één gemiddelde vector en voerden die in een standaardvoorspeller. KinForm kiest een genuanceerdere route. Het maakt gebruik van drie verschillende eiwittaalmodellen en richt zich op tussenliggende lagen die meer bruikbare informatie blijken te dragen voor kinetische voorspellingen dan de gebruikelijke eindlaag.
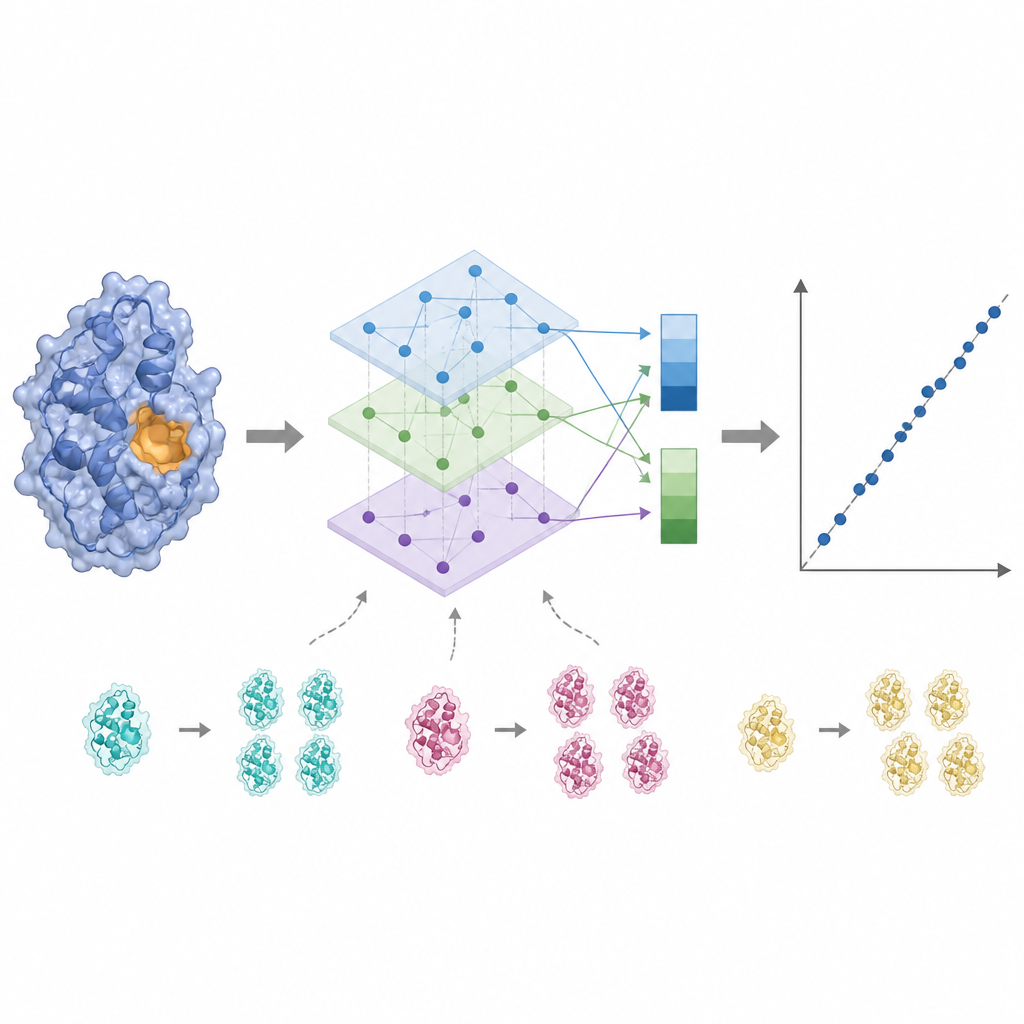
Luisteren naar de actieve plaats en de ruis wegsnijden
Enzymactiviteit wordt vaak bepaald door slechts een paar sleutelresiduen nabij de bindingsplaats, dus alle aminozuren gelijk behandelen kan het signaal vervagen. KinForm corrigeert dit door een extern hulpmiddel te gebruiken dat voor elk residu een score geeft voor de waarschijnlijkheid dat het tot de bindingsplaats behoort. Deze scores fungeren als gewichten bij het middelen van de outputs van de taalmodellen, resulterend in een vector die het hele eiwit weerspiegelt en een andere die de voorspelde actieve regio benadrukt. Omdat het combineren van meerdere grote modellen op deze manier zeer hoogdimensionale data oplevert, past KinForm vervolgens hoofdcomponentenanalyse toe, een statistische techniek die de informatie comprimeert tot een kleinere set coördinaten terwijl het grootste deel van de variatie die voor voorspelling relevant is behouden blijft.
Omgaan met gelijkenis en testen op echte generalisatie
Eiwitdatabases zitten vol met nauw verwante sequenties, wat een machine‑learningmodel kan verleiden om te memoriseren in plaats van algemene regels te leren. KinForm pakt dit op twee manieren aan. Ten eerste oversampelt het opzettelijk zeldzamere, laag‑vergelijkbare eiwitten tijdens training zodat zij een grotere bijdrage leveren aan het model. Ten tweede introduceren de auteurs een striktere testopzet die elke overlap in sequentie tussen trainings‑ en testsets voorkomt. Onder deze zwaardere voorwaarden presteren KinForm‑varianten die gecomprimeerde representaties en sequentiebewuste sampling gebruiken beter dan eerdere methoden, vooral voor enzymen die behoorlijk anders zijn dan alles wat het model eerder heeft gezien.
Wat de resultaten in de praktijk betekenen
Over twee grote benchmarkverzamelingen van enzymgegevens verbetert KinForm de nauwkeurigheid van voorspelde turnovergetallen en bindingsgerelateerde constanten vergeleken met een toonaangevend eerder model. De verbeteringen zijn het duidelijkst voor verre eiwitfamilies, waar data het schaarsst zijn en voorspellingen het meest nodig. Wanneer deze voorspellingen in gedetailleerde modellen van cellulair metabolisme worden ingevoerd, zijn de verbeteringen in het algehele gedrag bescheiden, wat suggereert dat andere onzekerheidsbronnen nog altijd een grote rol spelen. Het werk laat zien dat zorgvuldig samengestelde eiwitrepresentaties en realistischer teststandaarden AI‑gebaseerde kinetische schattingen betrouwbaarder kunnen maken, terwijl het ook benadrukt dat deze schattingen beter als condities‑neutrale uitgangspunten worden gezien dan als exacte waarden voor een specifieke omgeving.
Bronvermelding: Alwer, S., Fleming, R.M.T. KinForm: kinetics-informed feature optimised representation models for enzyme kcat and KM prediction. npj Syst Biol Appl 12, 71 (2026). https://doi.org/10.1038/s41540-026-00692-5
Trefwoorden: enzymkinetiek, eiwittaalmodellen, machine learning, metabole modellering, biochemische voorspelling