Clear Sky Science · pl
KinForm: kinetycznie informowane modele reprezentacji z optymalizacją cech do przewidywania kcat i KM enzymów
Dlaczego warto przewidywać szybkość enzymów
Każda żywa komórka zależy od enzymów, małych białkowych maszyn napędzających reakcje chemiczne. To, jak szybko działają te enzymy i jak silnie wiążą się ze swoimi partnerami, kształtuje wszystko — od tego, jak metabolizujemy pokarm, po to, jak mikroby produkują biopaliwa. Pomiar tych cech kinetycznych pojedynczo, w laboratorium, jest powolny i niepełny. Artykuł opisuje KinForm, podejście uczenia maszynowego, które uczy się na znanych przykładach, by oszacować zachowanie enzymów dla znacznie większej liczby białek, co może pomóc biologom i inżynierom lepiej projektować i analizować złożone systemy biochemiczne.
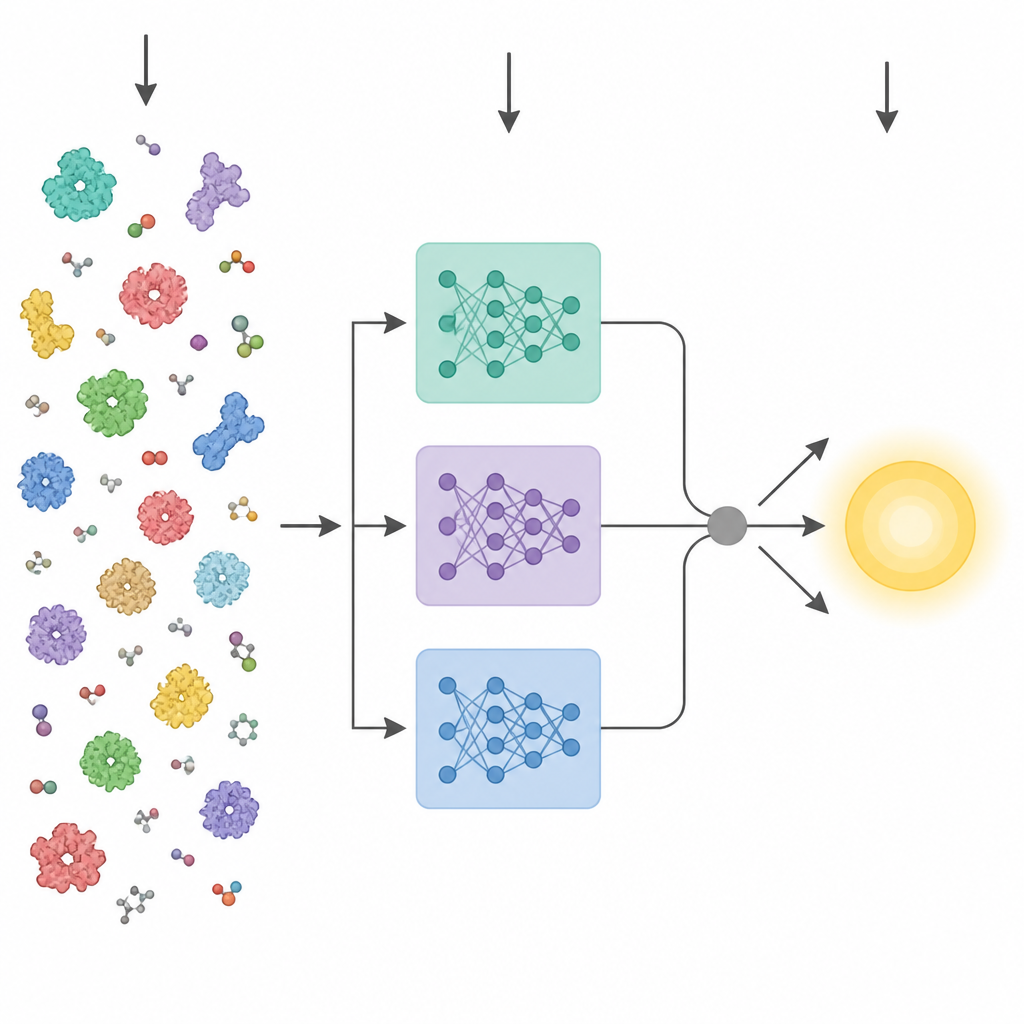
Co enzymy muszą nam powiedzieć
Dwie cechy liczbowe są kluczowe dla zrozumienia zachowania enzymu. Pierwsza, często nazywana liczbą obrotów (turnover number), opisuje, ile cykli reakcji enzym może wykonać w danym czasie. Druga, związana z tym, jak mocno enzym wiąże swój substrat, odzwierciedla, jak łatwo rozpoczynają się reakcje. Biolodzy wykorzystują te wartości do budowy modeli komputerowych metabolizmu, przewidywania wzrostu drobnoustrojów lub planowania nowych ścieżek dla zielonej chemii. Bazy danych zawierają jednak szczegółowe pomiary tylko dla niewielkiej części znanych enzymów, a większość wpisów skupia się na kilku dobrze zbadanych rodzinach białek. Ta fragmentaryczna dostępność ogranicza zarówno badania podstawowe, jak i zastosowania praktyczne.
Nauczanie komputerów języka białek
Ostatnie postępy w sztucznej inteligencji dały potężne „modele języka” białek. Narzędzia te są trenowane na milionach surowych sekwencji aminokwasowych i uczą się wzorców związanych ze strukturą trójwymiarową i funkcją, bez potrzeby etykiet eksperymentalnych. Wcześniejsze metody przewidywania cech enzymatycznych ze sekwencji zwykle sprowadzały ostatnią warstwę takiego modelu do pojedynczego uśrednionego wektora i podawały go standardowemu predyktorowi. KinForm wybiera bardziej zniuansowane podejście. Korzysta z trzech różnych modeli języka białek i koncentruje się na warstwach pośrednich, które okazują się zawierać bardziej użyteczne informacje do przewidywania kinetyki niż zwykła warstwa końcowa.
Słuchanie centrum aktywnego i przycinanie szumu
Aktywność enzymu często kontrolowana jest przez zaledwie kilka kluczowych reszt w pobliżu miejsca wiążącego, więc traktowanie każdego aminokwasu równie może rozmyć sygnał. KinForm koryguje to, używając zewnętrznego narzędzia oceniającego, jak prawdopodobne jest, że każdy reszt staje się częścią miejsca wiążącego. Te oceny działają jako wagi przy uśrednianiu wyjść modeli językowych, dając jeden wektor odzwierciedlający całe białko i drugi podkreślający prognozowany region aktywny. Ponieważ łączenie kilku dużych modeli w ten sposób tworzy bardzo wysokowymiarowe dane, KinForm stosuje następnie analizę głównych składowych (PCA), technikę statystyczną kompresującą informacje do mniejszego zestawu współrzędnych, zachowując jednocześnie większość wariancji istotnej dla przewidywania.
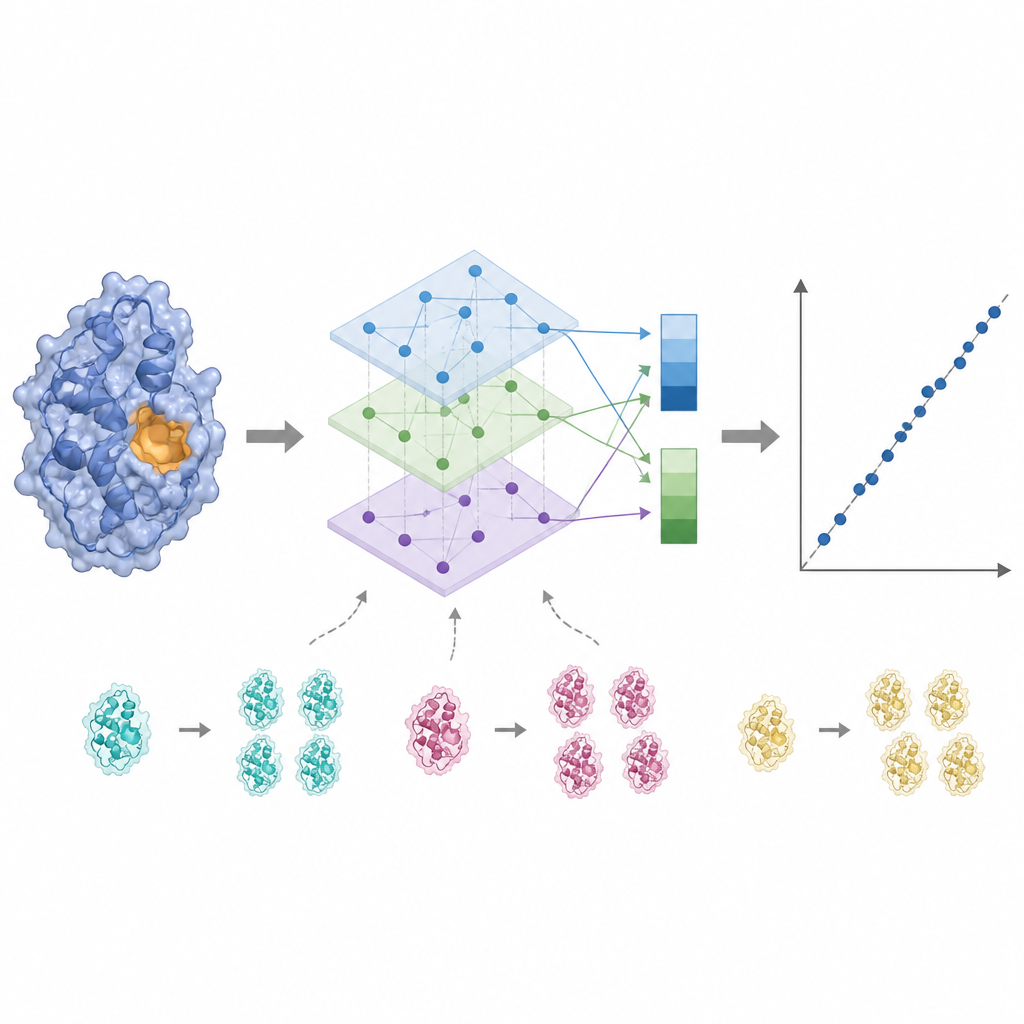
Radzenie sobie z podobieństwem i testowanie prawdziwej uogólnialności
Bazy danych białkowych pełne są blisko spokrewnionych sekwencji, co może skłaniać model uczenia maszynowego do zapamiętywania zamiast uczenia się ogólnych zasad. KinForm przeciwdziała temu na dwa sposoby. Po pierwsze, celowo nadreprezentuje rzadsze, mało podobne białka podczas treningu, aby miały większy wpływ na model. Po drugie, autorzy wprowadzają surowszy schemat testowania, który uniemożliwia jakiekolwiek nakładanie się sekwencji między zbiorami treningowymi i testowymi. W tych trudniejszych warunkach warianty KinForm wykorzystujące skompresowane reprezentacje i próbkowanie uwzględniające sekwencję wypadają lepiej niż wcześniejsze metody, szczególnie dla enzymów znacznie różniących się od czegokolwiek, co model widział wcześniej.
Co wyniki oznaczają w praktyce
Na dwóch dużych zestawach referencyjnych danych enzymatycznych KinForm poprawia dokładność przewidywanych liczb obrotów i stałych związanych z wiązaniem w porównaniu z wiodącym wcześniejszym modelem. Zyski są najbardziej wyraźne dla odległych rodzin białek, gdzie dane są najskromniejsze, a przewidywania najbardziej potrzebne. Gdy te przewidywania są wprowadzane do szczegółowych modeli metabolizmu komórkowego, poprawy w zachowaniu całościowym są umiarkowane, co sugeruje, że inne źródła niepewności nadal mają duże znaczenie. Praca pokazuje, że starannie zaprojektowane reprezentacje białek i bardziej realistyczne standardy testowania mogą uczynić oparte na AI oszacowania kinetyczne bardziej wiarygodnymi, jednocześnie podkreślając, że należy je traktować jako neutralne względem warunków punkty wyjścia, a nie jako dokładne wartości dla konkretnego środowiska.
Cytowanie: Alwer, S., Fleming, R.M.T. KinForm: kinetics-informed feature optimised representation models for enzyme kcat and KM prediction. npj Syst Biol Appl 12, 71 (2026). https://doi.org/10.1038/s41540-026-00692-5
Słowa kluczowe: kinetyka enzymów, modele języka białek, uczenie maszynowe, modelowanie metaboliczne, predykcja biochemiczna