Clear Sky Science · sv
Bedömning av bostadssegregation baserad på multipla datakällor och random forest-metod: en fallstudie i Nanjing
Varför det fortfarande spelar roll var vi bor
I städer tenderar människor med olika inkomster ofta att hamna i separata kvarter. Denna osynliga sortering påverkar allt från skolors kvalitet till tillgången till parker och jobb. Att följa hur denna bostadsseparation förändras över tiden är dock förvånansvärt svårt, eftersom det vanligen förlitar sig på långsamma och kostsamma folkräkningar. Denna studie fokuserar på Nanjing, en stor stad i Kina, och visar hur moderna digitala kartor och bostadsdata kan kombineras för att ge en snabbare och mer flexibel bild av vem som bor var — och hur blandad eller uppdelad staden har blivit.
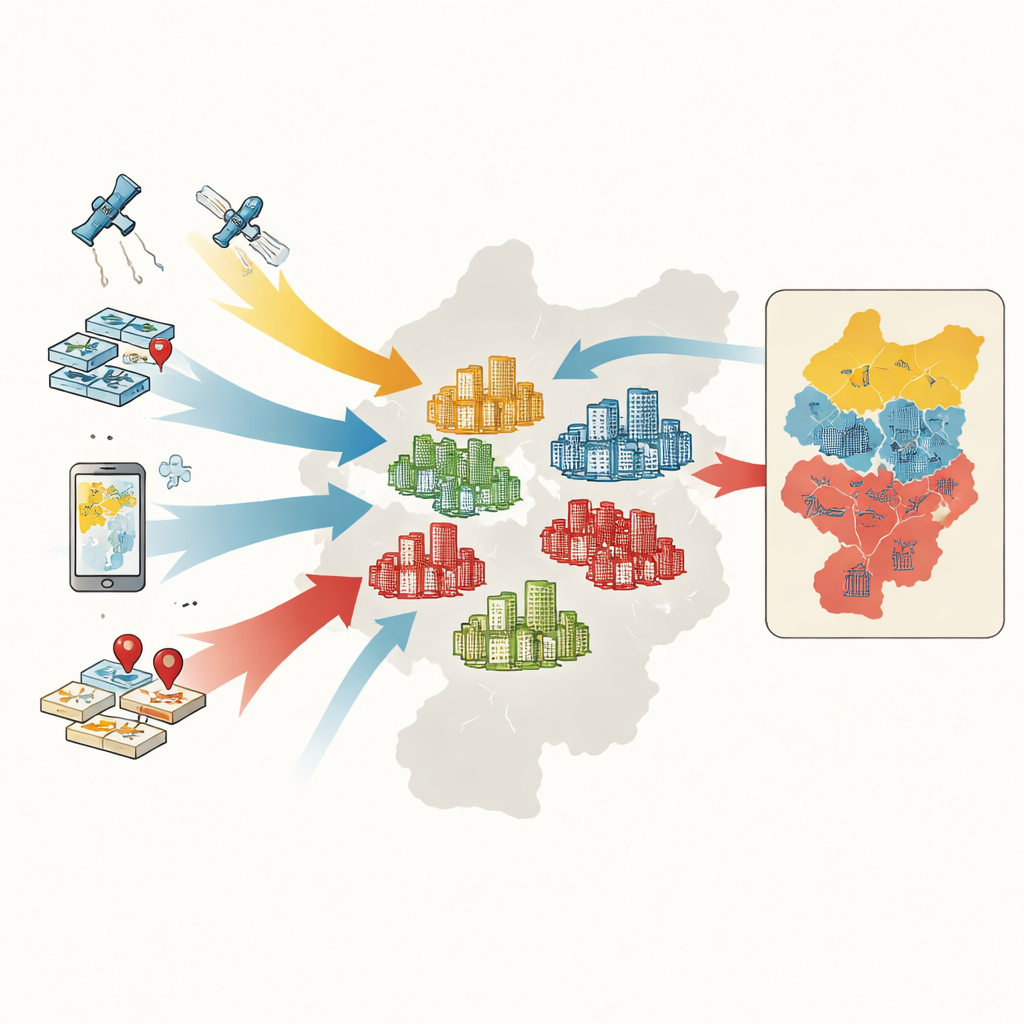
Från hushåll till bostadskomplex
Traditionella studier av segregation förlitar sig på folkräkningsdata som räknar hur många rika och fattiga som bor i varje område, för att sedan beräkna index för separation och mångfald. Men folkräkningar är glesa i tiden och kan snabbt bli inaktuella i snabbt föränderliga städer. Vissa forskare har försökt kringgå detta genom att använda bostadspriser som en proxy för inkomst, med antagandet att dyrare bostäder oftast betyder rikare invånare. Andra kombinerar bostadspriser med satellitbilder och punkter av intresse som skolor, butiker och parker. Dessa angreppssätt hjälper, men de förbiser ofta en avgörande detalj: inte varje markyta är lika befolkad. Ett tomt industriområde kan se lika "fattigt" ut på en karta som ett tättbefolkat låginkomstkvarter, trots att nästan ingen bor där.
Se kvarteren genom bostadskomplex
I kinesiska städer bor de flesta stadsbor i tydligt avgränsade bostadskomplex — grupper av flerfamiljshus med gemensamma grindar, trädgårdar och tjänster. Inom ett givet komplex tenderar invånarna att ha liknande inkomster och livsstilar, eftersom byggnadernas standard, ålder och omgivning "filtrerar" vilka som kan eller vill bo där. Denna studie behandlar varje komplex som en grundläggande analysenhet. Författarna hävdar att om man pålitligt kan sortera komplex i högklassiga, medelklassiga och lågklassiga kategorier, kan man också härleda sannolika inkomstnivåer för de som bor där, utan att behöva detaljerade personuppgifter.
Göra big data till en stadsöversikt
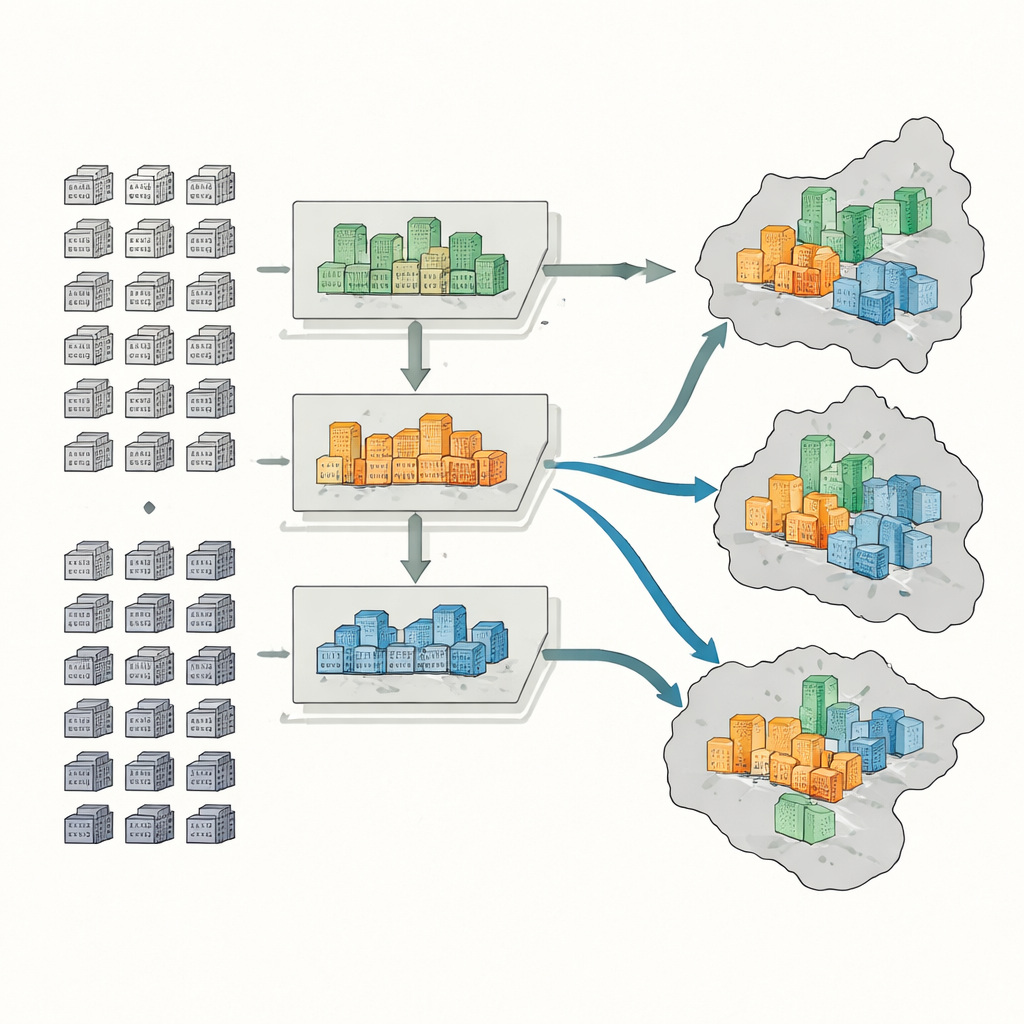
För att klassificera komplex samlar forskarna fem typer av information: officiella kartor och gränser, register över bostadsförsäljningar, digitala konturer av komplexens fotavtryck från onlinekartor, satellitbaserade mått på grönska och tusentals punkter som markerar tjänster som stormarknader, parker och kollektivtrafikhållplatser. För varje komplex mäter de sex nyckelfunktioner: genomsnittligt försäljningspris, byggnadsålder, byggnadstyp, grönska, tillgång till buss och tunnelbana samt täthet av vardagliga tjänster. En maskininlärningsmetod kallad random forest lär sig mönster i dessa egenskaper och sorterar mer än 4 400 komplex i högklassiga, medelklassiga eller lågklassiga grupper.
Mäta vem som bor var
Nästa steg är att uppskatta hur många som bor i varje komplex genom att använda antalet bostadsenheter och typiska vakansgrader, som skiljer sig mellan komplextyper. Högklassiga byggnader tenderar till exempel att ha fler tomma lägenheter än gamla, lågklassiga kvarter i innerstaden. Därefter kartlägger de hög-, medel- och låginkomstpopulationer på två skalor: stadsdelar och mindre sub-distrikt. Med detta beräknar de tre standardindikatorer: ett dissimilaritetsindex som visar hur skarpt välbärgade och mindre välbärgade grupper är åtskilda; ett lokaliseringskvot som avslöjar var förmögna eller låginkomsttagare är ovanligt koncentrerade; och ett mångfaldsindex som fångar hur jämnt olika inkomstgrupper delar samma områden.
Vad mönstren i Nanjing visar
Resultaten visar att Nanjings centrala stadsområde i stort sett endast uppvisar en måttlig nivå av inkomstbaserad separation. Vissa stadsdelar sticker dock ut. Jianye, ett starkt ombyggt område, har många nya högklassiga komplex och relativt få lågklassiga, vilket leder till stark koncentration av förmögna invånare och höga segregeringsvärden. Qinhuai, däremot, innehåller många äldre, lågklassiga komplex och färre lyxutvecklingar, så det koncentrerar låginkomsttagare. Andra distrikt som Gulou och Qixia visar mer blandade mönster, med gammalt och nytt boende sida vid sida. På den finare sub-distriktsnivån framträder några områden som mycket blandade, medan andra domineras av en inkomstgrupp. Dessa mönster stämmer överens med oberoende kontroller med folkräkningsuppgifter och hyrespriser, vilket tyder på att metoden fångar verkliga sociala klyftor.
Varför detta nya perspektiv är viktigt
För icke-specialister är huvudslutsatsen att vi nu kan följa bostadssegregation utan att behöva vänta år på en ny folkräkning. Genom att använda bostadskomplex som "behållare" för sociala grupper och mata multipla datakällor till en inlärningsalgoritm levererar författarna en praktisk genväg: de kan uppskatta var olika inkomstgrupper bor, hur åtskilda de är och hur detta varierar över en stad. Deras fallstudie i Nanjing visar att detta tillvägagångssätt är både noggrant och praktiskt. Allt eftersom fler städer genererar rika digitala spår — satellitbilder, onlinekartor, bostadsannonser — erbjuder denna metod planerare och beslutsfattare ett nytt verktyg för att övervaka ojämlikhet, rikta investeringar och pröva om stadsförnyelseprojekt faktiskt förenar människor eller skjuter dem längre ifrån varandra.
Citering: Zhang, Y., Sun, Y., Zhu, AX. et al. Residential segregation assessment based on multi-source data and random forest method: a case study of Nanjing. Humanit Soc Sci Commun 13, 482 (2026). https://doi.org/10.1057/s41599-026-06840-w
Nyckelord: urban segregation, bostadskomplex, Nanjing, geospatial data, bostadsojämlikhet