Clear Sky Science · de
Bewertung der Wohnsegregation anhand multiquelliger Daten und Random-Forest-Methode: Eine Fallstudie zu Nanjing
Warum unser Wohnort weiterhin wichtig ist
In Städten leben Menschen mit unterschiedlichen Einkommen häufig in räumlich getrennten Vierteln. Dieses unsichtbare Sortieren beeinflusst alles – von der Qualität der Schulen bis zum Zugang zu Parks und Arbeitsplätzen. Die Entwicklung dieser Wohntrennung über die Zeit zu verfolgen ist jedoch überraschend schwierig, weil man sich meist auf langsame, teure Bevölkerungsbefragungen stützt. Diese Studie konzentriert sich auf Nanjing, eine Großstadt in China, und zeigt, wie moderne digitale Karten und Wohnungsdaten kombiniert werden können, um schneller und flexibler abzubilden, wer wo lebt – und wie durchmischt oder getrennt die Stadt geworden ist.
Von Haushalten zu Wohnsiedlungen
Traditionelle Studien zur Segregation stützen sich auf Volkszählungsdaten, die zählen, wie viele wohlhabende und weniger wohlhabende Menschen in jedem Gebiet leben, und daraus Trennungs- und Diversitätsindizes berechnen. Volkszählungen sind jedoch selten und können in schnell veränderlichen Städten rasch veralten. Einige Forschende nutzen Wohnpreise als Proxy für Einkommen, in der Annahme, dass teurere Wohnungen meist wohlhabendere Bewohner bedeuten. Andere kombinieren Wohnpreise mit Satellitenbildern und Points of Interest wie Schulen, Geschäften und Parks. Diese Ansätze helfen, übersehen aber oft eine wichtige Tatsache: Nicht jeder Quadratmeter Land ist gleich dicht besiedelt. Ein leerer Industriepark kann auf einer Karte genauso „arm“ aussehen wie ein dichtes, einkommensschwaches Viertel, obwohl dort kaum jemand wohnt.
Nachbarschaften durch Wohnsiedlungen sehen
In chinesischen Städten leben die meisten Stadtbewohner in klar abgegrenzten Wohnsiedlungen – Gruppen von Wohnblocks mit gemeinsamen Toren, Gärten und Dienstleistungen. Innerhalb einer Siedlung haben die Bewohner tendenziell ähnliche Einkommen und Lebensstile, weil die Qualität, das Alter und die Umgebung der Gebäude filtern, wer dort wohnen kann oder will. Diese Studie behandelt jede Siedlung als Basiseinheit der Analyse. Die Autoren argumentieren, dass sich, wenn man Siedlungen zuverlässig in High-End-, Mittelklassen- und Low-End-Kategorien einteilen kann, daraus auch die wahrscheinlichen Einkommensniveaus der dort lebenden Menschen ableiten lassen, ohne detaillierte Personendaten zu benötigen.
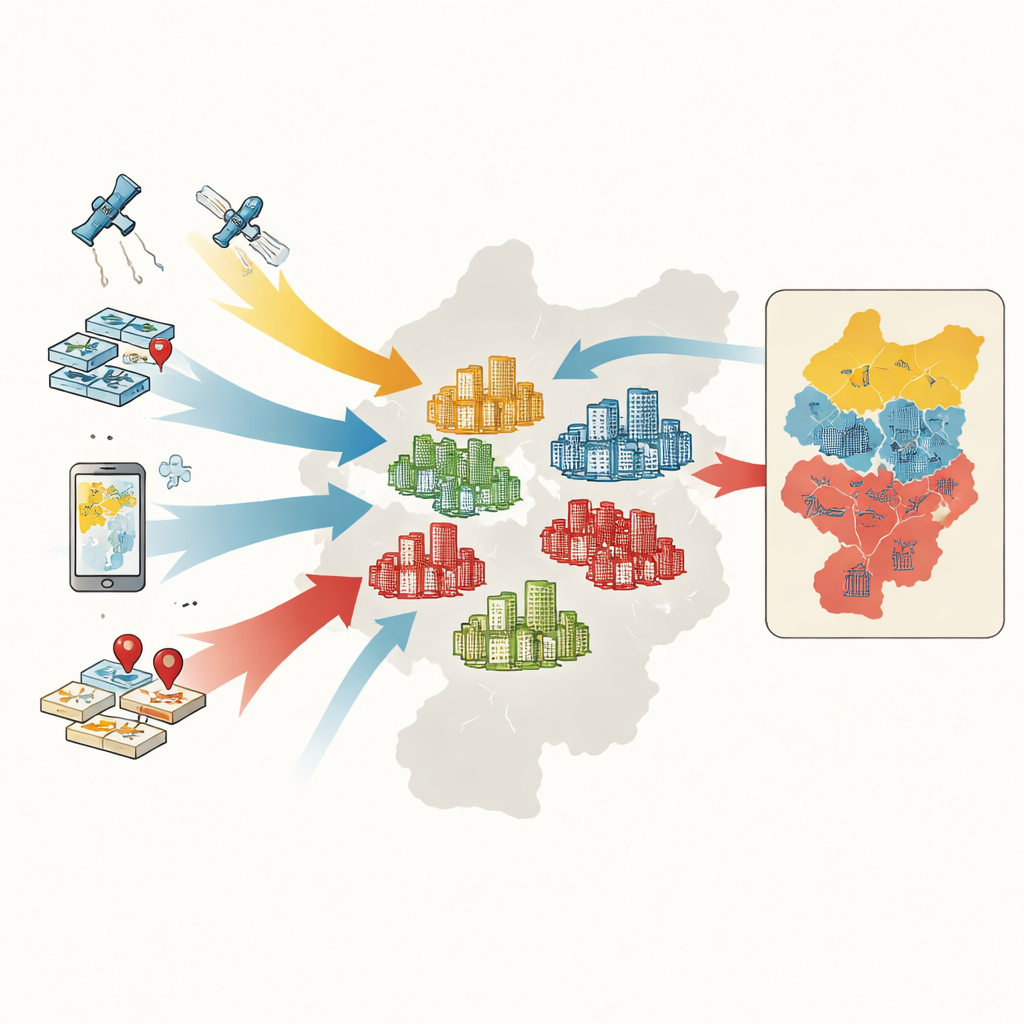
Big Data in eine stadtweite Karte verwandeln
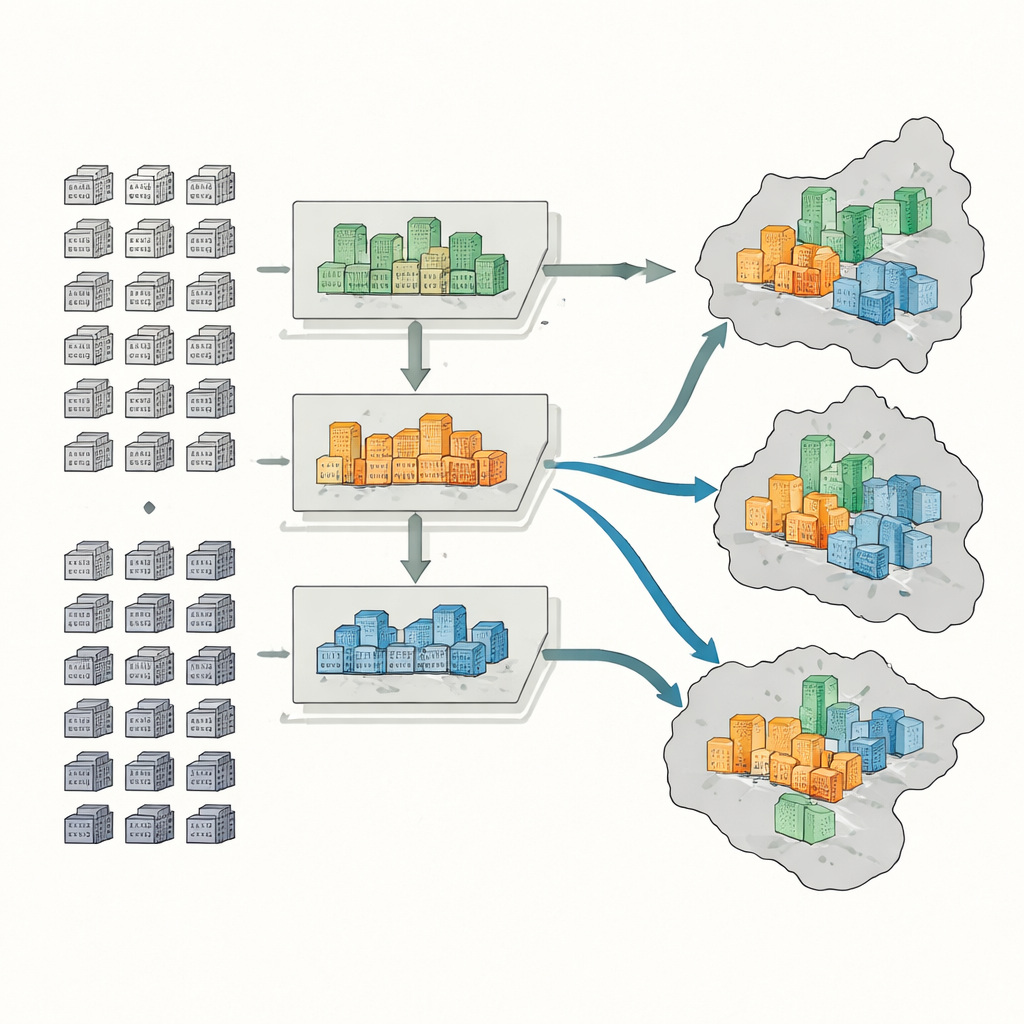
Um Siedlungen zu klassifizieren, bündeln die Forschenden fünf Informationsarten: amtliche Karten und Grenzen, Aufzeichnungen zu Wohnungstransaktionen, digitale Umrisse der Siedlungsflächen aus Online-Karten, satellitengestützte Vegetationsmessungen und tausende Punkte mit Serviceangeboten wie Supermärkten, Parks und Haltestellen des öffentlichen Nahverkehrs. Für jede Siedlung messen sie sechs Schlüsselfeatures: durchschnittlicher Verkaufspreis, Baualter, Gebäudetyp, Grünanteil, Erreichbarkeit von Bus und Metro sowie Dichte alltäglicher Dienstleistungen. Ein maschinelles Lernverfahren namens Random Forest erkennt dann Muster in diesen Merkmalen und teilt mehr als 4.400 Siedlungen in High-End-, Mittelklasse- oder Low-End-Gruppen ein.
Messen, wer wo lebt
Als Nächstes schätzt das Team, wie viele Menschen in jeder Siedlung leben, mithilfe der Anzahl der Wohneinheiten und typischer Leerstandsquoten, die je nach Siedlungstyp variieren. High-End-Gebäude zum Beispiel haben tendenziell mehr leerstehende Wohnungen als alte, niedrigpreisige Blöcke im Stadtzentrum. Anschließend kartieren sie High-, Mittel- und Low-End-Bevölkerung auf zwei Maßstabsebenen: Bezirke und kleinere Unterbezirke. Damit berechnen sie drei gängige Indikatoren: einen Dissimilaritätsindex, der zeigt, wie stark wohlhabende und weniger wohlhabende Gruppen getrennt sind; einen Lokationsquotienten, der aufzeigt, wo wohlhabende oder einkommensschwache Bewohner ungewöhnlich konzentriert sind; und einen Diversitätsindex, der erfasst, wie gleichmäßig verschiedene Einkommensgruppen dieselben Gebiete teilen.
Was die Muster in Nanjing offenbaren
Die Ergebnisse zeigen, dass das zentrale Stadtgebiet von Nanjing insgesamt nur ein moderates Maß an einkommensbasierter Trennung aufweist. Bestimmte Bezirke stechen jedoch hervor. Jianye, stark umgestaltet, hat viele neue High-End-Siedlungen und vergleichsweise wenige Low-End-Siedlungen, was zu einer starken Konzentration wohlhabender Bewohner und hohen Segregationswerten führt. Qinhuai dagegen enthält viele ältere, niedrigpreisige Siedlungen und wenige Luxusentwicklungen, sodass dort stärker einkommensschwächere Bewohner konzentriert sind. Andere Bezirke wie Gulou und Qixia zeigen gemischtere Muster, mit alten und neuen Wohnformen nebeneinander. Auf der feineren Unterbezirksebene ergeben sich einige sehr gemischte Orte, während andere von einer Einkommensgruppe dominiert werden. Diese Muster stimmen mit unabhängigen Prüfungen anhand von Volkszählungsdaten und Mietpreisen überein, was darauf hindeutet, dass die Methode reale soziale Trennungen erfasst.
Warum diese neue Perspektive wichtig ist
Für Nichtfachleute lautet die zentrale Erkenntnis: Wir können Wohnsegregation jetzt verfolgen, ohne jahrelang auf eine neue Volkszählung warten zu müssen. Indem Wohnsiedlungen als „Behälter“ sozialer Gruppen verwendet und multiquellige Daten in einen Lernalgorithmus eingespeist werden, liefern die Autoren eine praktikable Abkürzung: Sie können abschätzen, wo verschiedene Einkommensgruppen leben, wie stark sie getrennt sind und wie sich das innerhalb einer Stadt unterscheidet. Die Fallstudie in Nanjing zeigt, dass dieser Ansatz sowohl genau als auch praktikabel ist. Da immer mehr Städte reichhaltige digitale Spuren erzeugen – Satellitenbilder, Online-Karten, Immobilienangebote – bietet diese Methode Planerinnen, Politikern und Verwaltungen ein neues Instrument, Ungleichheit zu überwachen, Investitionen zu steuern und zu prüfen, ob Stadterneuerungsprojekte Menschen zusammenbringen oder weiter auseinanderdrängen.
Zitation: Zhang, Y., Sun, Y., Zhu, AX. et al. Residential segregation assessment based on multi-source data and random forest method: a case study of Nanjing. Humanit Soc Sci Commun 13, 482 (2026). https://doi.org/10.1057/s41599-026-06840-w
Schlüsselwörter: städtische Segregation, Wohnsiedlungen, Nanjing, geodaten, Wohnungsungleichheit