Clear Sky Science · fr
Évaluation de la ségrégation résidentielle basée sur des données multi-sources et la méthode des forêts aléatoires : étude de cas de Nankin
Pourquoi l'endroit où nous vivons compte encore
Dans les villes, les personnes aux revenus différents se retrouvent souvent à vivre dans des quartiers séparés. Ce tri invisible façonne tout, de la qualité des écoles à l'accès aux parcs et aux emplois. Pourtant, suivre l'évolution de cette séparation résidentielle est étonnamment difficile, car cela repose généralement sur des enquêtes démographiques longues et coûteuses. Cette étude se concentre sur Nankin, une grande ville chinoise, et montre comment des cartes numériques modernes et des données immobilières peuvent être combinées pour fournir une image plus rapide et plus souple de qui vit où — et dans quelle mesure la ville est mixte ou fragmentée.
Des ménages aux résidences collectives
Les études traditionnelles sur la ségrégation reposent sur les données du recensement qui comptent combien de personnes aisées ou modestes vivent dans chaque zone, puis calculent des indices de séparation et de diversité. Mais les recensements sont peu fréquents et peuvent vite être périmés dans des villes en rapide mutation. Certains chercheurs contournent ce problème en utilisant les prix de l'immobilier comme substitut au revenu, en partant du principe que des logements plus chers correspondent généralement à des résidents plus riches. D'autres combinent les prix de l'immobilier avec des images satellitaires et des points d'intérêt comme les écoles, commerces et parcs. Ces approches aident, mais elles négligent souvent un fait crucial : toutes les parcelles n'ont pas la même densité de population. Une friche industrielle vide peut paraître « pauvre » sur une carte comme un quartier populaire très dense, alors que presque personne n'y habite.
Observer les quartiers à travers les résidences collectives
Dans les villes chinoises, la majorité des urbains vivent dans des résidences collectives clairement délimitées — ensembles d'immeubles avec portails, jardins et services partagés. Au sein d'une même résidence, les habitants ont tendance à avoir des revenus et des modes de vie similaires, car la qualité des bâtiments, leur âge et leur environnement « filtrent » qui peut ou veut s'y installer. Cette étude prend chaque résidence comme unité d'analyse de base. Les auteurs soutiennent que si l'on peut classer de manière fiable les résidences en catégories haut de gamme, milieu de gamme et bas de gamme, on peut en déduire les niveaux de revenus probables des personnes qui y vivent, sans données personnelles détaillées.
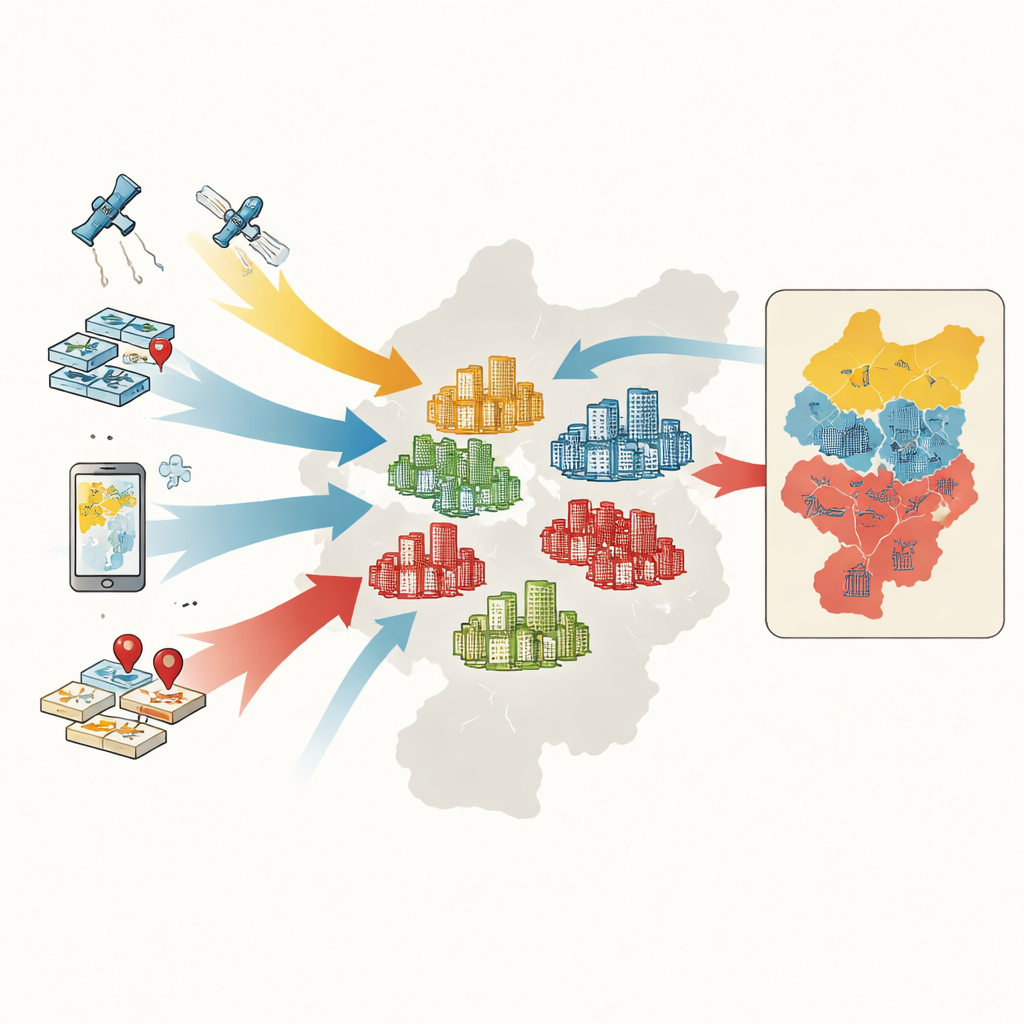
Transformer le big data en carte urbaine
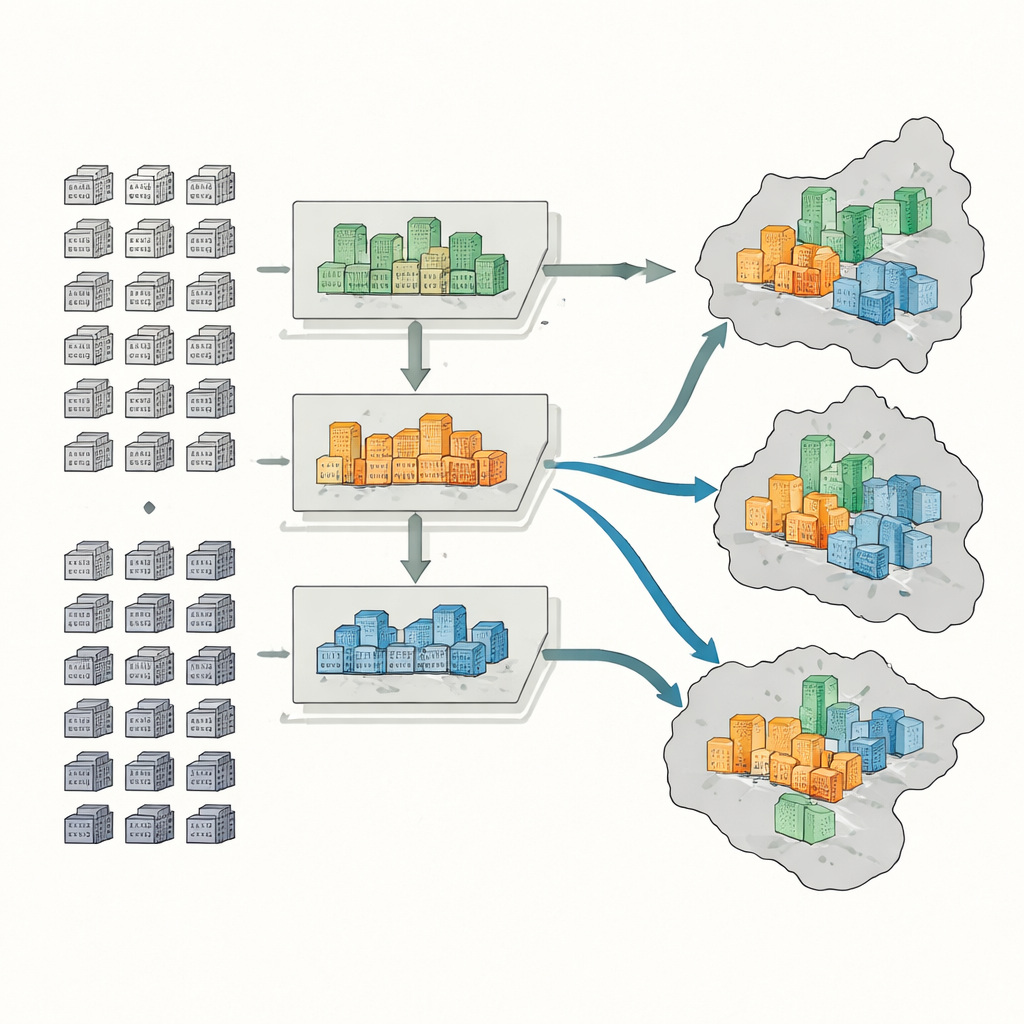
Pour classer les résidences, les chercheurs réunissent cinq types d'informations : cartes et limites officielles, enregistrements des transactions immobilières, contours numériques des résidences issus de cartes en ligne, mesures satellitaires de la végétation, et des milliers de points localisant des services comme supermarchés, parcs et arrêts de transports en commun. Pour chaque résidence, ils mesurent six caractéristiques clés : prix moyen de vente, âge des bâtiments, type structurel, verdure, accessibilité aux bus et au métro, et densité des services quotidiens. Une méthode d'apprentissage automatique appelée forêt aléatoire apprend alors les motifs dans ces caractéristiques et classe plus de 4 400 résidences en catégories haut de gamme, milieu de gamme ou bas de gamme.
Mesurer qui habite où
Ensuite, l'équipe estime le nombre d'habitants par résidence à partir du nombre de logements et des taux de vacance typiques, qui varient selon le type de résidence. Les immeubles haut de gamme, par exemple, tendent à avoir plus de logements vides que les vieux blocs bas de gamme du centre-ville. Ils cartographient ensuite les populations haut de gamme, milieu de gamme et bas de gamme à deux échelles : les districts et des sous-districts plus petits. À partir de ces cartes, ils calculent trois indicateurs standards : un indice de dissimilarité montrant à quel point les groupes aisés et moins aisés sont séparés ; un quotient de localisation révélant où les résidents riches ou pauvres sont anormalement concentrés ; et un indice de diversité capturant la manière dont les différents groupes de revenus partagent équitablement les mêmes zones.
Ce que révèlent les motifs à Nankin
Les résultats montrent que, globalement, la zone urbaine principale de Nankin présente un niveau modéré de séparation fondée sur le revenu. Néanmoins, certains districts se distinguent. Jianye, fortement réaménagé, comporte de nombreuses résidences neuves haut de gamme et relativement peu de résidences bas de gamme, ce qui entraîne une forte concentration de résidents aisés et des scores élevés de ségrégation. Qinhuai, en revanche, contient de nombreuses résidences anciennes et bas de gamme et moins de développements luxueux, concentrant ainsi les ménages à revenus plus faibles. D'autres districts comme Gulou et Qixia affichent des schémas plus mixtes, avec logements anciens et neufs côte à côte. À l'échelle fine des sous-districts, certains lieux apparaissent très mixtes, tandis que d'autres sont dominés par un seul groupe de revenus. Ces schémas concordent avec des vérifications indépendantes utilisant les comptes du recensement et les loyers, suggérant que la méthode capte de réelles divisions sociales.
Pourquoi ce nouveau prisme est important
Pour un public non spécialiste, l'idée clé est que nous pouvons désormais suivre la ségrégation résidentielle sans attendre des années pour un nouveau recensement. En utilisant les résidences collectives comme « conteneurs » de groupes sociaux et en alimentant un algorithme d'apprentissage avec des données multi-sources, les auteurs offrent un raccourci opérationnel : ils peuvent estimer où vivent les différents groupes de revenus, à quel point ils sont séparés, et comment cela varie dans la ville. Leur étude de cas à Nankin montre que cette approche est à la fois précise et pratique. À mesure que davantage de villes génèrent des traces numériques riches — images satellitaires, cartes en ligne, annonces immobilières — cette méthode fournit aux urbanistes et décideurs un nouvel outil pour surveiller les inégalités, cibler les investissements et vérifier si les projets de renouvellement urbain rapprochent les personnes ou les éloignent davantage.
Citation: Zhang, Y., Sun, Y., Zhu, AX. et al. Residential segregation assessment based on multi-source data and random forest method: a case study of Nanjing. Humanit Soc Sci Commun 13, 482 (2026). https://doi.org/10.1057/s41599-026-06840-w
Mots-clés: ségrégation urbaine, résidences collectives, Nankin, données géospatiales, inégalités de logement