Clear Sky Science · it
Valutazione della segregazione residenziale basata su dati multiforme e metodo random forest: uno studio di caso su Nanchino
Perché il luogo in cui viviamo conta ancora
Nelle città, persone con redditi diversi spesso finiscono per abitare in quartieri separati. Questa selezione invisibile influenza tutto, dalla qualità delle scuole all'accesso a parchi e posti di lavoro. Tuttavia monitorare come questa separazione residenziale cambia nel tempo è sorprendentemente difficile, perché di solito si basa su indagini demografiche lente e costose. Questo studio si concentra su Nanchino, una grande città cinese, e mostra come mappe digitali moderne e dati immobiliari possano essere combinati per fornire un quadro più rapido e flessibile di chi vive dove — e di quanto la città sia mista o divisa.
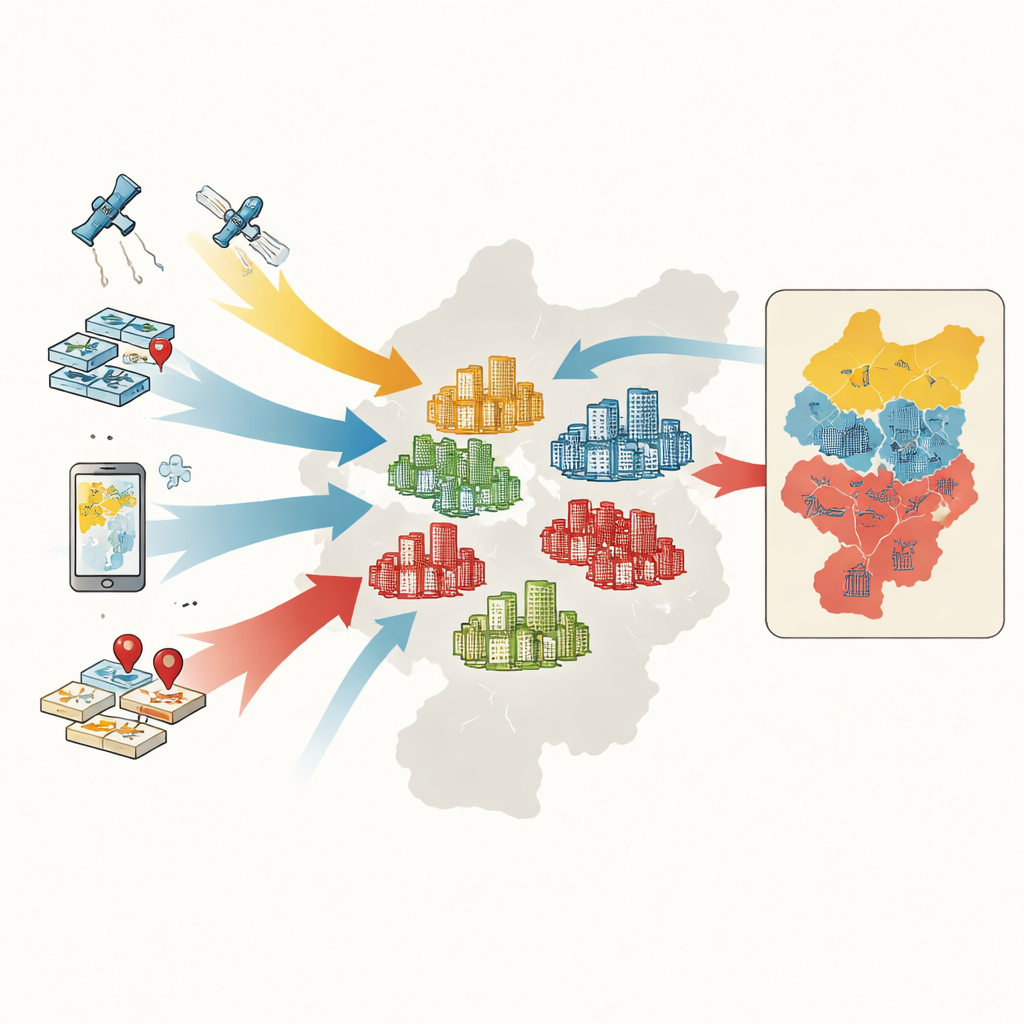
Dalle famiglie ai complessi residenziali
Gli studi tradizionali sulla segregazione si basano sui dati del censimento che contano quanti ricchi e poveri vivono in ciascuna area, per poi calcolare indici di separazione e diversità. Ma i censimenti sono poco frequenti e possono diventare rapidamente obsoleti in città che cambiano in fretta. Alcuni ricercatori hanno provato a ovviare a questo usando i prezzi delle abitazioni come proxy del reddito, ragionando che case più costose corrispondono in genere a residenti più ricchi. Altri combinano prezzi immobiliari con immagini satellitari e punti di interesse come scuole, negozi e parchi. Questi approcci aiutano, ma spesso ignorano un fatto cruciale: non ogni porzione di suolo è popolata in egual misura. Un'area industriale vuota può apparire «povera» su una mappa quanto un quartiere densamente popolato a basso reddito, anche se quasi nessuno ci abita.
Vedere i quartieri attraverso i complessi residenziali
Nelle città cinesi, la maggior parte dei residenti urbani vive in complessi residenziali chiaramente delimitati — gruppi di condomini con gate, giardini e servizi condivisi. All'interno di un dato complesso, i residenti tendono ad avere redditi e stili di vita simili, perché la qualità, l'età e l'intorno degli edifici «filtrano» chi può o vuole abitarvi. Questo studio considera ogni complesso come unità di analisi fondamentale. Gli autori sostengono che se è possibile classificare in modo affidabile i complessi in categorie di alto, medio e basso livello, si possono anche dedurre i probabili livelli di reddito delle persone che vi abitano, senza bisogno di dati personali dettagliati.
Trasformare i big data in una mappa cittadina
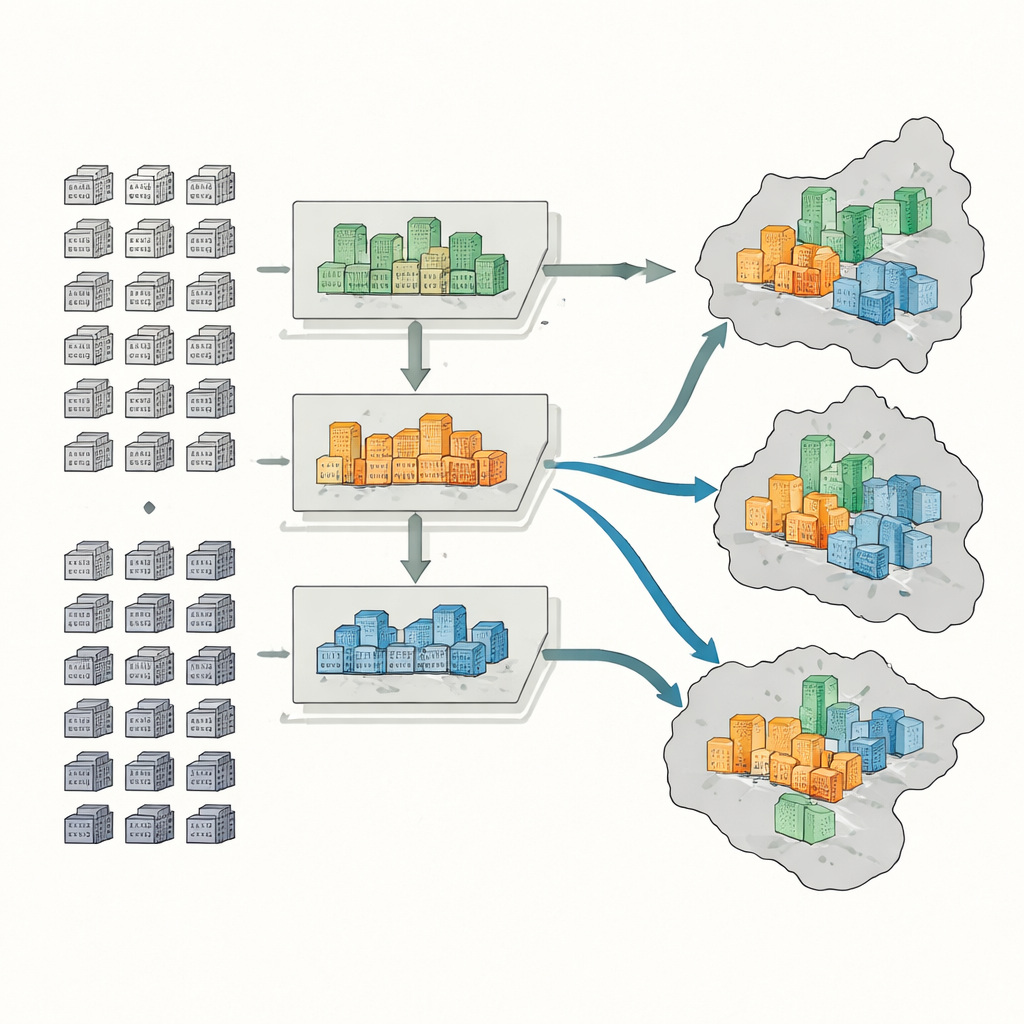
Per classificare i complessi, i ricercatori raccolgono cinque tipi di informazioni: mappe e confini ufficiali, registri delle transazioni immobiliari, sagome digitali dei complessi estratte da mappe online, misure satellitari della vegetazione e migliaia di punti che segnano servizi come supermercati, parchi e fermate dei mezzi pubblici. Per ciascun complesso misurano sei caratteristiche chiave: prezzo medio di vendita, età degli edifici, tipo strutturale, grado di verde, accesso a bus e metropolitana e densità dei servizi quotidiani. Un metodo di apprendimento automatico chiamato random forest impara quindi i modelli in queste caratteristiche e classifica oltre 4.400 complessi in gruppi alto, medio o basso livello.
Misurare chi vive dove
Successivamente il team stima quante persone vivono in ciascun complesso usando il numero di unità abitative e i tassi di sfitto tipici, che variano in base al tipo di complesso. Gli edifici di alto livello, per esempio, tendono ad avere più alloggi vuoti rispetto ai blocchi vecchi e di basso livello nel centro città. Dopodiché mappano le popolazioni di alto, medio e basso livello su due scale: distretti e sub-distretti più piccoli. Con questi dati calcolano tre indicatori standard: un indice di dissimilarità che mostra quanto sono separate le fasce più ricche da quelle meno agiate; un quoziente di localizzazione che rivela dove i residenti ricchi o a basso reddito sono insoliti concentrati; e un indice di diversità che cattura quanto equamente i diversi gruppi di reddito condividono le stesse aree.
Cosa rivelano i modelli a Nanchino
I risultati mostrano che, nel complesso, l'area urbana principale di Nanchino presenta un livello solo moderato di segregazione basata sul reddito. Tuttavia alcuni distretti risaltano. Jianye, un'area fortemente riqualificata, ha molti nuovi complessi di alto livello e relativamente pochi di basso livello, portando a una forte concentrazione di residenti agiati e a punteggi elevati di segregazione. Qinhuai, al contrario, contiene molti complessi vecchi e di basso livello e pochi sviluppi di lusso, quindi concentra residenti a reddito più basso. Altri distretti come Gulou e Qixia mostrano schemi più misti, con abitazioni vecchie e nuove affiancate. Alla scala più fine dei sub-distretti, alcuni luoghi emergono come molto misti, mentre altri sono dominati da un unico gruppo di reddito. Questi modelli corrispondono a controlli indipendenti basati su dati censuari e sui prezzi degli affitti, suggerendo che il metodo cattura divisioni sociali reali.
Perché questa nuova lente è importante
Per i non specialisti, la conclusione chiave è che ora possiamo monitorare la segregazione residenziale senza aspettare anni per un nuovo censimento. Usando i complessi residenziali come «contenitori» per gruppi sociali e alimentando dati multiforme in un algoritmo di apprendimento, gli autori offrono una scorciatoia praticabile: possono stimare dove vivono i diversi gruppi di reddito, quanto sono separati e come ciò varia nella città. Il loro studio di caso a Nanchino mostra che questo approccio è sia accurato sia pratico. Con il crescente numero di tracce digitali generate dalle città — immagini satellitari, mappe online, annunci immobiliari — questo metodo offre a pianificatori e decisori politici uno strumento nuovo per monitorare le disuguaglianze, indirizzare gli investimenti e verificare se i progetti di riqualificazione urbana stanno avvicinando le persone o allontanandole ulteriormente.
Citazione: Zhang, Y., Sun, Y., Zhu, AX. et al. Residential segregation assessment based on multi-source data and random forest method: a case study of Nanjing. Humanit Soc Sci Commun 13, 482 (2026). https://doi.org/10.1057/s41599-026-06840-w
Parole chiave: segregazione urbana, complessi residenziali, Nanchino, dati geospaziali, disuguaglianza abitativa