Clear Sky Science · es
Evaluación de la segregación residencial basada en datos multisource y el método random forest: estudio de caso en Nanjing
Por qué sigue importando dónde vivimos
En las ciudades, las personas con ingresos distintos a menudo acaban viviendo en vecindarios separados. Esta clasificación invisible condiciona desde la calidad de las escuelas hasta el acceso a parques y al empleo. Sin embargo, seguir la evolución de esta separación residencial a lo largo del tiempo resulta sorprendentemente difícil, porque suele depender de encuestas de población lentas y costosas. Este estudio se centra en Nanjing, una gran ciudad de China, y muestra cómo los mapas digitales modernos y los datos de vivienda pueden combinarse para ofrecer una imagen más rápida y flexible de quién vive dónde y de cuán mezclada o dividida está la ciudad.
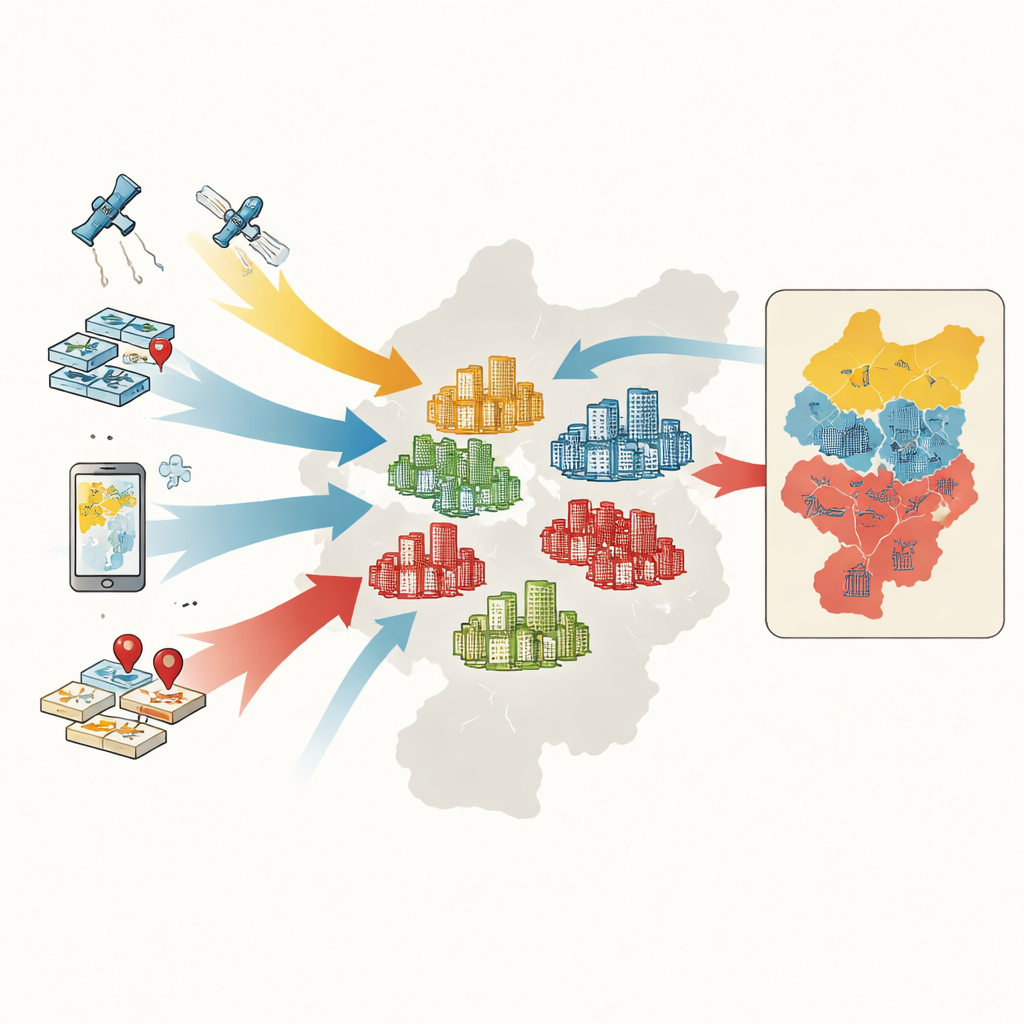
De los hogares a los complejos residenciales
Los estudios tradicionales sobre segregación se apoyan en datos censales que cuentan cuántas personas ricas y pobres viven en cada área, y luego calculan índices de separación y diversidad. Pero los censos son infrecuentes y pueden quedar rápidamente obsoletos en ciudades que cambian deprisa. Algunos investigadores han intentado sortear esto usando los precios de la vivienda como sustituto del ingreso, razonando que las viviendas más caras suelen indicar residentes más pudientes. Otros combinan precios de la vivienda con imágenes satelitales y puntos de interés como escuelas, comercios y parques. Estos enfoques ayudan, pero a menudo pasan por alto un hecho crucial: no todas las superficies de terreno están igualmente pobladas. Un polígono industrial vacío puede parecer igual de “pobre” en un mapa que un barrio densamente habitado de bajos ingresos, aunque prácticamente nadie viva allí.
Ver los barrios a través de los complejos residenciales
En las ciudades chinas, la mayoría de los residentes urbanos vive en complejos residenciales claramente delimitados: conjuntos de edificios de apartamentos con puertas, jardines y servicios compartidos. Dentro de un mismo complejo, los residentes tienden a tener ingresos y estilos de vida similares, porque la calidad, la antigüedad y el entorno de los edificios “filtran” quién puede o quiere vivir allí. Este estudio trata cada complejo como la unidad básica de análisis. Los autores sostienen que si es posible clasificar con fiabilidad los complejos en categorías de alta, media y baja gama, también se puede inferir el nivel de ingresos probable de las personas que viven en ellos, sin necesidad de datos personales detallados.
Convertir los megadatos en un mapa de la ciudad
Para clasificar los complejos, los investigadores reúnen cinco tipos de información: mapas y límites oficiales, registros de transacciones de vivienda, contornos digitales de las huellas de los complejos extraídos de mapas en línea, medidas de vegetación derivadas de satélite y miles de puntos que marcan servicios como supermercados, parques y paradas de transporte público. Para cada complejo miden seis características clave: precio medio de venta, antigüedad del edificio, tipo estructural, nivel de vegetación, acceso a autobuses y metro, y densidad de servicios cotidianos. Un método de aprendizaje automático llamado random forest aprende los patrones en estas características y clasifica más de 4.400 complejos en grupos de alta, media o baja gama.
Medir quién vive dónde
A continuación, el equipo estima cuántas personas viven en cada complejo usando el número de viviendas y las tasas típicas de vacancia, que varían según el tipo de complejo. Por ejemplo, los edificios de alta gama suelen tener más viviendas vacías que los bloques antiguos y de baja renta del centro. Luego mapean las poblaciones de alta, media y baja gama en dos escalas: distritos y subdistritos más pequeños. Con esto calculan tres indicadores estándar: un índice de disimilitud que muestra la separación entre grupos acomodados y menos acomodados; un cociente de localización que revela dónde los residentes ricos o de bajos ingresos están inusualmente concentrados; y un índice de diversidad que captura cuán uniformemente distintos grupos de ingresos comparten las mismas áreas.
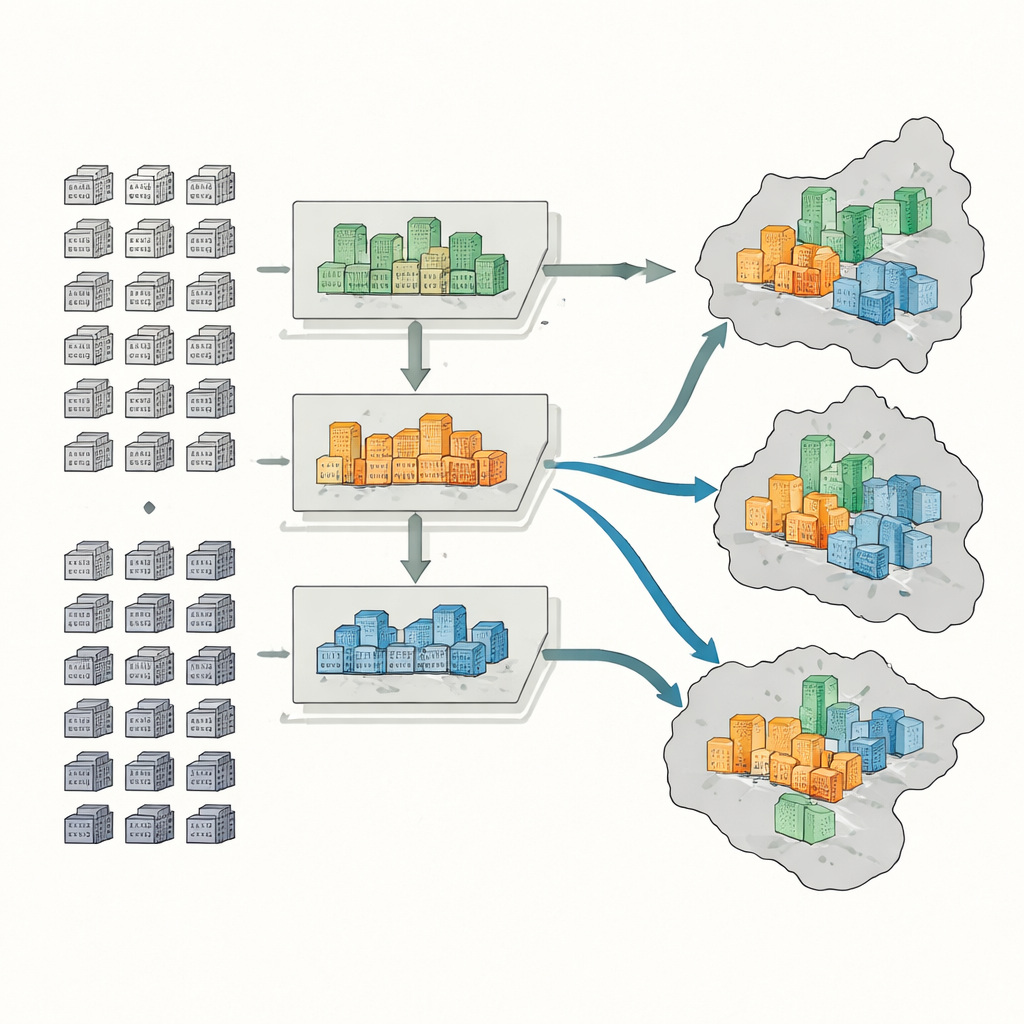
Qué revelan los patrones en Nanjing
Los resultados muestran que, en conjunto, el área urbana principal de Nanjing presenta solo un nivel moderado de separación por ingresos. No obstante, ciertos distritos destacan. Jianye, una zona muy remodelada, cuenta con muchos complejos nuevos de alta gama y relativamente pocos de baja gama, lo que conduce a una fuerte concentración de residentes acomodados y a altos puntajes de segregación. Qinhuai, en contraste, contiene muchos complejos antiguos y de baja gama y menos desarrollos de lujo, por lo que concentra a residentes de menores ingresos. Otros distritos como Gulou y Qixia muestran patrones más mixtos, con vivienda antigua y nueva lado a lado. A escala de subdistrito más fina, algunos lugares emergen como muy mixtos, mientras que otros están dominados por un solo grupo de ingresos. Estos patrones coinciden con verificaciones independientes usando conteos censales y precios de alquiler, lo que sugiere que el método captura divisiones sociales reales.
Por qué importa este nuevo enfoque
Para el público no especializado, la conclusión clave es que ahora podemos rastrear la segregación residencial sin esperar años a un nuevo censo. Al usar los complejos residenciales como “contenedores” de grupos sociales y alimentar un algoritmo con datos multisource, los autores ofrecen un atajo operativo: pueden estimar dónde viven distintos grupos de ingresos, cuán separados están y cómo varía eso en la ciudad. Su estudio de caso en Nanjing demuestra que este enfoque es a la vez preciso y práctico. A medida que más ciudades generan huellas digitales ricas —imágenes satelitales, mapas en línea, anuncios de propiedades—, este método ofrece a planificadores y responsables de políticas una nueva herramienta para monitorear la desigualdad, dirigir inversiones y comprobar si los proyectos de renovación urbana están acercando a las personas o empujándolas a separarse aún más.
Cita: Zhang, Y., Sun, Y., Zhu, AX. et al. Residential segregation assessment based on multi-source data and random forest method: a case study of Nanjing. Humanit Soc Sci Commun 13, 482 (2026). https://doi.org/10.1057/s41599-026-06840-w
Palabras clave: segregación urbana, complejos residenciales, Nanjing, datos geoespaciales, desigualdad de la vivienda