Clear Sky Science · pt
Avaliação da segregação residencial com base em dados de múltiplas fontes e método de random forest: um estudo de caso de Nanjing
Por que Onde Vivemos Ainda Importa
Nas cidades, pessoas com diferentes rendas frequentemente acabam morando em bairros separados. Essa separação invisível molda tudo, da qualidade das escolas ao acesso a parques e empregos. Ainda assim, acompanhar como essa separação residencial muda ao longo do tempo é surpreendentemente difícil, porque normalmente depende de levantamentos populacionais lentos e caros. Este estudo foca em Nanjing, uma grande cidade na China, e mostra como mapas digitais modernos e dados de habitação podem ser combinados para oferecer uma imagem mais rápida e flexível de quem mora onde — e o quanto a cidade está misturada ou dividida.
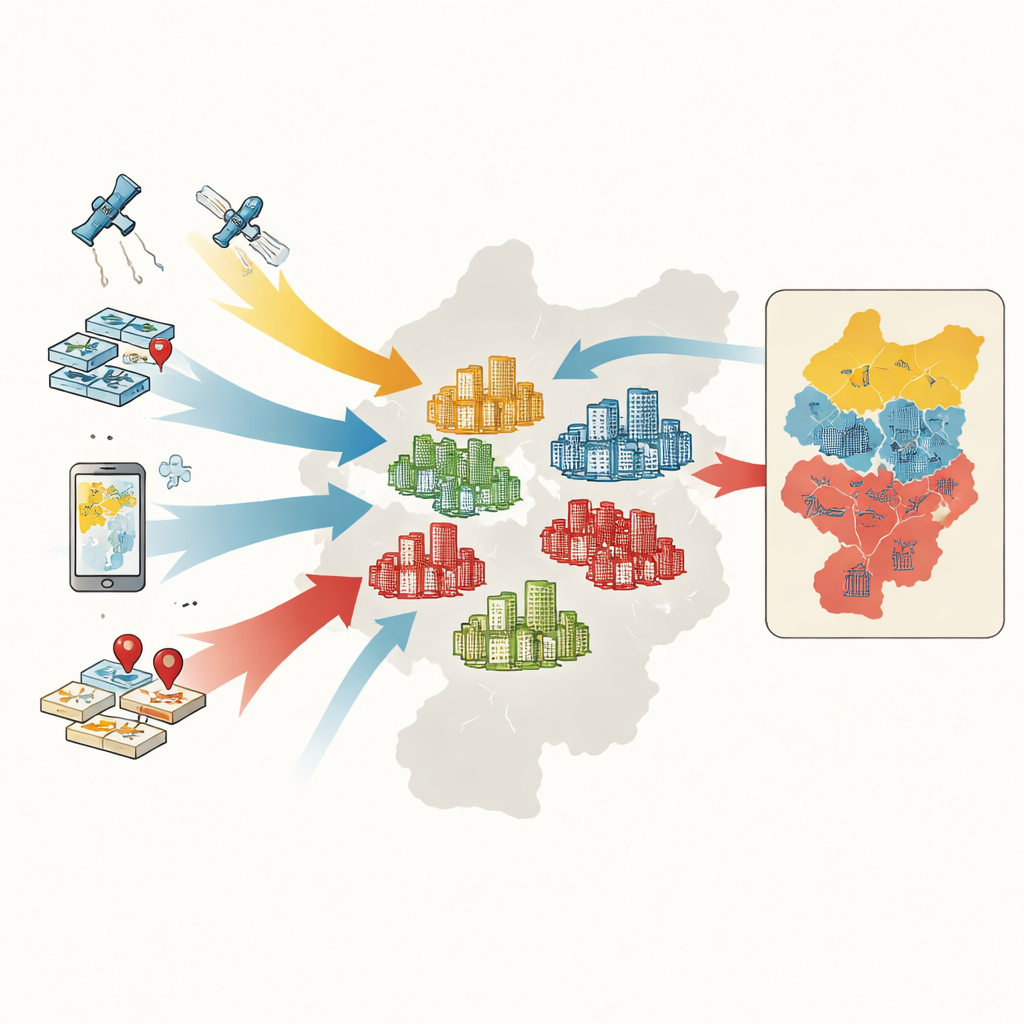
De Famílias a Conjuntos Habitacionais
Estudos tradicionais sobre segregação dependem de dados do censo que contabilizam quantas pessoas ricas e pobres vivem em cada área e depois calculam índices de separação e diversidade. Mas censos são pouco frequentes e podem ficar rapidamente desatualizados em cidades que mudam rápido. Alguns pesquisadores tentaram contornar isso usando preços de moradia como proxy de renda, partindo do raciocínio de que lares mais caros geralmente indicam moradores mais ricos. Outros combinam preços de moradia com imagens de satélite e pontos de interesse como escolas, lojas e parques. Essas abordagens ajudam, mas muitas vezes ignoram um fato crucial: nem todo pedaço de terra é igualmente povoado. Uma área industrial vazia pode parecer tão “pobre” num mapa quanto um bairro de baixa renda e muito povoado, embora quase ninguém viva ali.
Vendo Bairros Através de Conjuntos Residenciais
Nas cidades chinesas, a maioria dos residentes urbanos vive em conjuntos residenciais claramente delimitados — grupos de blocos de apartamentos com portões, jardins e serviços compartilhados. Dentro de um mesmo conjunto, os moradores tendem a ter rendas e estilos de vida semelhantes, porque a qualidade, a idade e o entorno dos edifícios “filtram” quem pode ou quer morar ali. Este estudo trata cada conjunto como uma unidade básica de análise. Os autores argumentam que, se for possível classificar os conjuntos de forma confiável em categorias de alto padrão, médio e baixo padrão, também se pode inferir os prováveis níveis de renda das pessoas que vivem neles, sem precisar de dados pessoais detalhados.
Transformando Big Data em um Mapa da Cidade
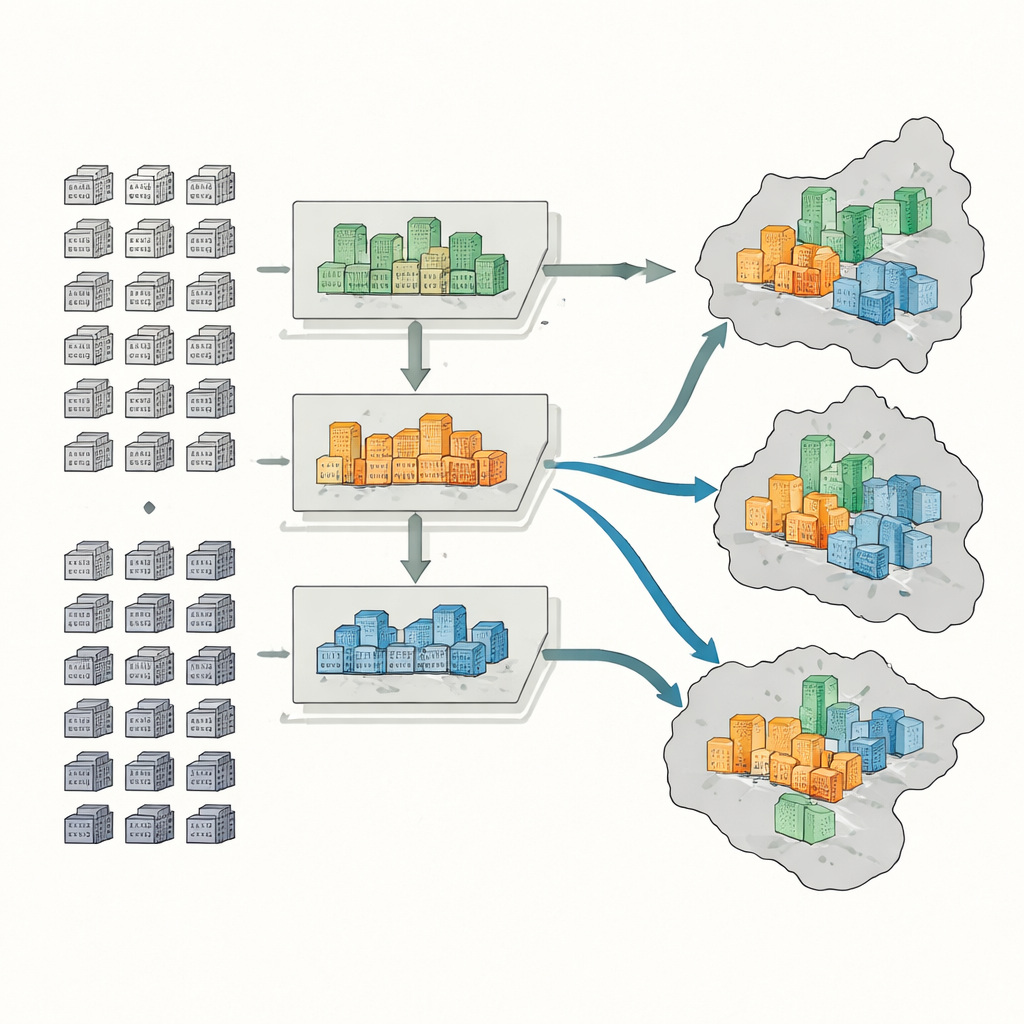
Para classificar os conjuntos, os pesquisadores reúnem cinco tipos de informação: mapas e limites oficiais, registros de transações de imóveis, contornos digitais das áreas dos conjuntos em mapas online, medidas de vegetação a partir de satélite e milhares de pontos que marcam serviços como supermercados, parques e pontos de transporte público. Para cada conjunto, medem seis características-chave: preço médio de venda, idade do edifício, tipo estrutural, presença de áreas verdes, acesso a ônibus e metrô e densidade de serviços cotidianos. Um método de aprendizado de máquina chamado random forest aprende padrões nessas características e classifica mais de 4.400 conjuntos em grupos de alto, médio ou baixo padrão.
Medindo Quem Mora Onde
Em seguida, a equipe estima quantas pessoas vivem em cada conjunto usando o número de unidades habitacionais e taxas típicas de vacância, que variam conforme o tipo de conjunto. Prédios de alto padrão, por exemplo, tendem a ter mais moradias vazias do que blocos antigos e de baixo padrão no centro da cidade. Depois, mapeiam as populações de alto, médio e baixo padrão em duas escalas: distritos e subdistritos menores. Com isso, calculam três indicadores padrão: um índice de dissimilaridade que mostra quão nítida é a separação entre grupos mais e menos afluentes; um quociente de localização que revela onde residentes ricos ou de baixa renda estão incomumente concentrados; e um índice de diversidade que captura quão uniformemente diferentes grupos de renda compartilham as mesmas áreas.
O que os Padrões em Nanjing Revelam
Os resultados mostram que, no geral, a área urbana principal de Nanjing apresenta apenas um nível moderado de separação por renda. Ainda assim, certos distritos se destacam. Jianye, uma área fortemente requalificada, tem muitos conjuntos de alto padrão recém-construídos e relativamente poucos de baixo padrão, levando a uma forte concentração de residentes afluentes e a índices elevados de segregação. Qinhuai, por outro lado, contém muitos conjuntos antigos e de baixo padrão e menos empreendimentos de luxo, concentrando assim residentes de baixa renda. Outros distritos como Gulou e Qixia mostram padrões mais mistos, com habitação antiga e nova lado a lado. Na escala mais fina dos subdistritos, alguns locais surgem como muito mistos, enquanto outros são dominados por um único grupo de renda. Esses padrões correspondem a verificações independentes usando contagens do censo e preços de aluguel, sugerindo que o método está capturando divisões sociais reais.
Por que Esta Nova Perspectiva Importa
Para não especialistas, a principal conclusão é que agora podemos monitorar a segregação residencial sem esperar anos por um novo censo. Ao usar conjuntos residenciais como “recipientes” de grupos sociais e alimentar um algoritmo com dados de múltiplas fontes, os autores oferecem um atalho viável: é possível estimar onde diferentes grupos de renda moram, o quão separados estão e como isso varia pela cidade. O estudo de caso em Nanjing mostra que essa abordagem é ao mesmo tempo precisa e prática. À medida que mais cidades geram vestígios digitais ricos — imagens de satélite, mapas online, anúncios de imóveis — esse método oferece a planejadores e formuladores de políticas uma nova ferramenta para monitorar a desigualdade, direcionar investimentos e testar se projetos de renovação urbana estão aproximando as pessoas ou empurrando-as ainda mais para longe.
Citação: Zhang, Y., Sun, Y., Zhu, AX. et al. Residential segregation assessment based on multi-source data and random forest method: a case study of Nanjing. Humanit Soc Sci Commun 13, 482 (2026). https://doi.org/10.1057/s41599-026-06840-w
Palavras-chave: segregação urbana, conjuntos residenciais, Nanjing, dados geoespaciais, desigualdade habitacional