Clear Sky Science · nl
Beoordeling van woonsegregatie op basis van meervoudige databronnen en een random-forestmethode: een casestudy van Nanjing
Waarom waar we wonen nog steeds telt
In steden wonen mensen met verschillende inkomens vaak in gescheiden wijken. Deze onzichtbare scheiding bepaalt zaken als de kwaliteit van scholen en de toegang tot parken en banen. Het bijhouden van hoe deze woonsegregatie in de loop van de tijd verandert is echter verrassend lastig, omdat dat meestal afhangt van trage en dure bevolkingsonderzoeken. Deze studie richt zich op Nanjing, een grote Chinese stad, en laat zien hoe moderne digitale kaarten en woninggegevens kunnen worden gecombineerd om sneller en flexibeler in kaart te brengen wie waar woont — en hoe gemengd of verdeeld de stad is geworden.
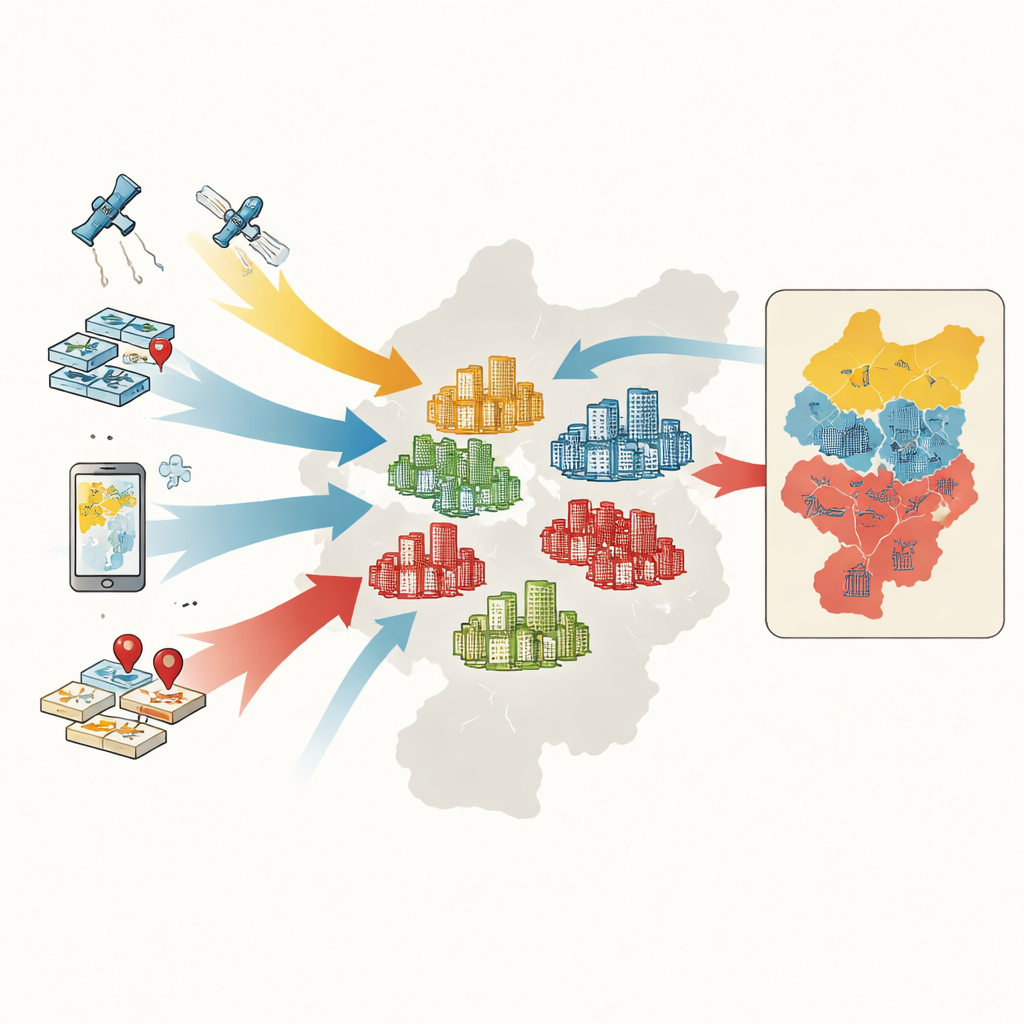
Van huishoudens naar wooncomplexen
Traditionele studies naar segregatie steunen op volkstellingsgegevens die tellen hoeveel rijke en arme mensen in elk gebied wonen en vervolgens scheidings- en diversiteitsindices berekenen. Maar volkstellingen zijn zeldzaam en raken in snel veranderende steden snel verouderd. Sommige onderzoekers proberen dit te omzeilen door woningprijzen als proxy voor inkomen te gebruiken, uitgaande van het idee dat duurdere woningen meestal duiden op rijkere bewoners. Anderen combineren woningprijzen met satellietbeelden en punten van interesse zoals scholen, winkels en parken. Deze benaderingen helpen, maar ze negeren vaak een cruciaal feit: niet elk stuk land is even dicht bevolkt. Een leeg industrieterrein kan op een kaart net zo "arm" lijken als een drukke laaginkomenswijk, terwijl er in het industrieterrein vrijwel niemand woont.
Buurten zien via wooncomplexen
In Chinese steden woont het merendeel van de stedelijke bevolking in duidelijk afgebakende wooncomplexen — groepen flatgebouwen met gedeelde poorten, tuinen en voorzieningen. Binnen een complex hebben bewoners vaak vergelijkbare inkomens en levensstijlen, omdat de kwaliteit, leeftijd en omgeving van de gebouwen 'filteren' wie er kan of wil wonen. Deze studie behandelt elk complex als een basisanalyse-eenheid. De auteurs betogen dat als je complexen betrouwbaar kunt indelen in luxe, middensegment en laagsegment, je ook de waarschijnlijke inkomensniveaus van de bewoners kunt afleiden zonder gedetailleerde persoonlijke gegevens.
Big data omzetten in een stadskaart
Om complexen te classificeren verzamelen de onderzoekers vijf soorten informatie: officiële kaarten en grenzen, gegevens over woningtransacties, digitale omtrekken van complexen uit online kaarten, satellietgebaseerde metingen van groenvoorziening en duizenden punten die voorzieningen zoals supermarkten, parken en openbaar vervoer markeren. Voor elk complex meten ze zes kernkenmerken: gemiddelde verkoopprijs, bouwjaar, constructietype, groenvoorziening, toegang tot bus en metro en de dichtheid van dagelijkse voorzieningen. Een machine-learningmethode genaamd random forest leert vervolgens patronen in deze kenmerken en classificeert meer dan 4.400 complexen als luxe, middensegment of laagsegment.
Meten wie waar woont
Vervolgens schat het team hoeveel mensen in elk complex wonen aan de hand van het aantal woningunits en typische leegstandspercentages, die verschillen per type complex. Luxueuze gebouwen hebben bijvoorbeeld vaak meer lege woningen dan oude, laagsegmentblokken in het stadscentrum. Ze brengen daarna de populaties van luxe, midden- en laagsegment in kaart op twee schaalniveaus: districten en kleinere subdistricten. Daarmee berekenen ze drie standaardindicatoren: een dissimilariteitsindex die aangeeft hoe scherp rijke en minder rijke groepen zijn gescheiden; een locatiequotient dat onthult waar rijke of laaginkomensbewoners uitzonderlijk geconcentreerd zijn; en een diversiteitsindex die weergeeft hoe gelijkmatig verschillende inkomensgroepen gebieden delen.
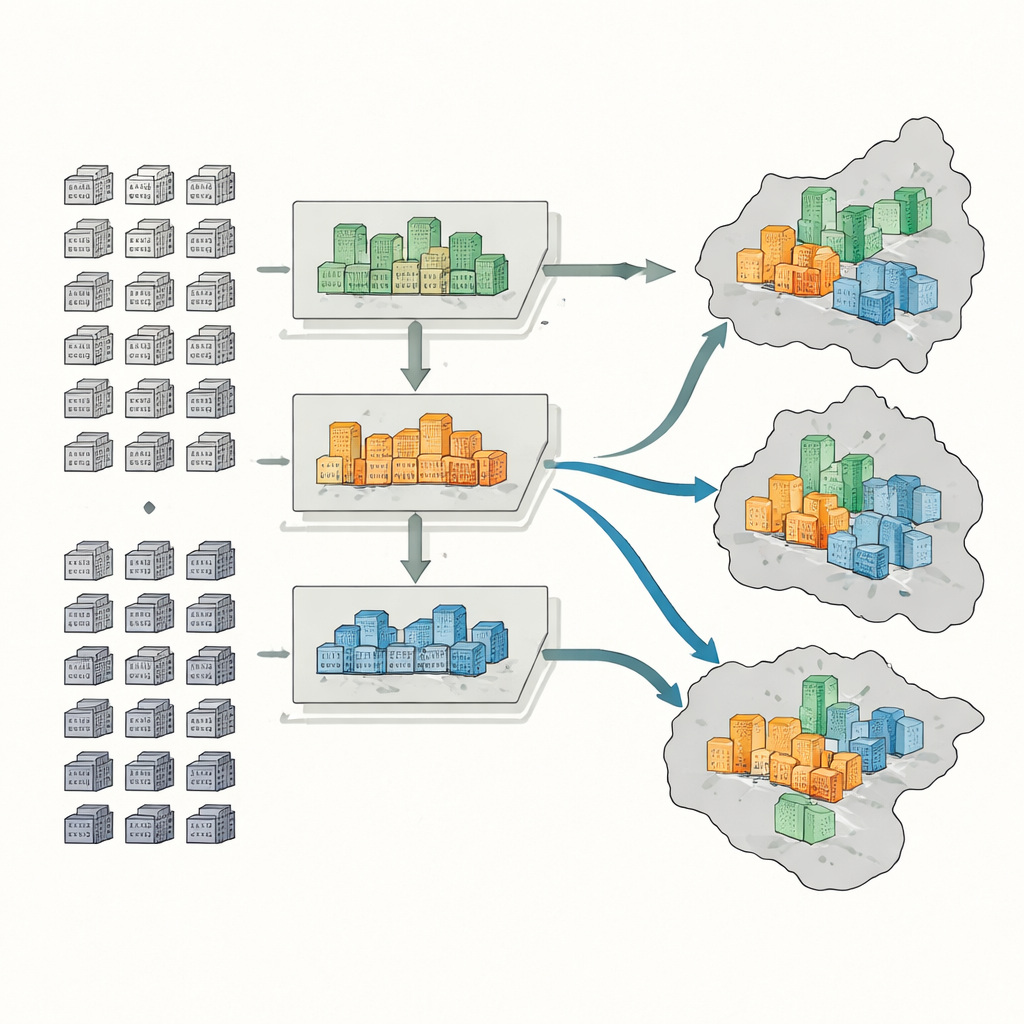
Wat de patronen in Nanjing onthullen
De resultaten tonen dat het hoofdstedelijk gebied van Nanjing in het algemeen slechts een gematigd niveau van inkomensscheiding vertoont. Toch vallen bepaalde districten op. Jianye, een sterk herontwikkeld gebied, heeft veel nieuwe luxecomplexen en relatief weinig laagsegmentcomplexen, wat leidt tot sterke concentratie van welvarende bewoners en hoge segregatiescores. Qinhuai daarentegen bevat veel oudere laagsegmentcomplexen en minder luxe ontwikkelingen, waardoor er een concentratie van lagere inkomens ontstaat. Andere districten zoals Gulou en Qixia tonen gemengdere patronen, met oude en nieuwe woningen naast elkaar. Op het fijnere subdistrictniveau ontstaan sommige plekken als zeer gemengd, terwijl andere worden gedomineerd door één inkomensgroep. Deze patronen komen overeen met onafhankelijke controles op basis van volkstellingsgegevens en huurprijzen, wat suggereert dat de methode echte sociale scheidslijnen vastlegt.
Waarom dit nieuwe perspectief ertoe doet
Voor niet-specialisten is de belangrijkste conclusie dat we nu woonsegregatie kunnen volgen zonder jaren te wachten op een nieuwe volkstelling. Door wooncomplexen te gebruiken als 'containers' voor sociale groepen en meervoudige databronnen in een leeralgoritme te verwerken, bieden de auteurs een bruikbare kortere weg: ze kunnen inschatten waar verschillende inkomensgroepen wonen, hoe gescheiden ze zijn en hoe dat binnen een stad varieert. Hun casestudy in Nanjing laat zien dat deze aanpak zowel nauwkeurig als praktisch is. Naarmate meer steden rijke digitale sporen genereren — satellietbeelden, online kaarten, vastgoedadvertenties — biedt deze methode planners en beleidsmakers een nieuw instrument om ongelijkheid te volgen, investeringen te richten en te toetsen of stadsvernieuwingsprojecten mensen dichter bij elkaar brengen of juist verder uit elkaar duwen.
Bronvermelding: Zhang, Y., Sun, Y., Zhu, AX. et al. Residential segregation assessment based on multi-source data and random forest method: a case study of Nanjing. Humanit Soc Sci Commun 13, 482 (2026). https://doi.org/10.1057/s41599-026-06840-w
Trefwoorden: stedelijke segregatie, wooncomplexen, Nanjing, georuimtelijke gegevens, huisvestingsongelijkheid