Clear Sky Science · pl
Ocena segregacji mieszkaniowej na podstawie danych wieloźródłowych i metody lasu losowego: studium przypadku Nankinu
Dlaczego miejsce zamieszkania nadal ma znaczenie
W miastach osoby o różnych dochodach często trafiają do odrębnych sąsiedztw. Ta niewidzialna selekcja kształtuje wszystko, od jakości szkół po dostęp do parków i miejsc pracy. Śledzenie zmian tej separacji w czasie jest jednak zaskakująco trudne, ponieważ zwykle opiera się na wolnych i kosztownych badaniach ludności. W tym badaniu skupiono się na Nankinie, ważnym mieście w Chinach, i pokazano, jak nowoczesne mapy cyfrowe oraz dane o mieszkaniach można połączyć, by szybciej i elastyczniej uzyskać obraz tego, kto gdzie mieszka — oraz jak bardzo miasto jest mieszane lub podzielone.
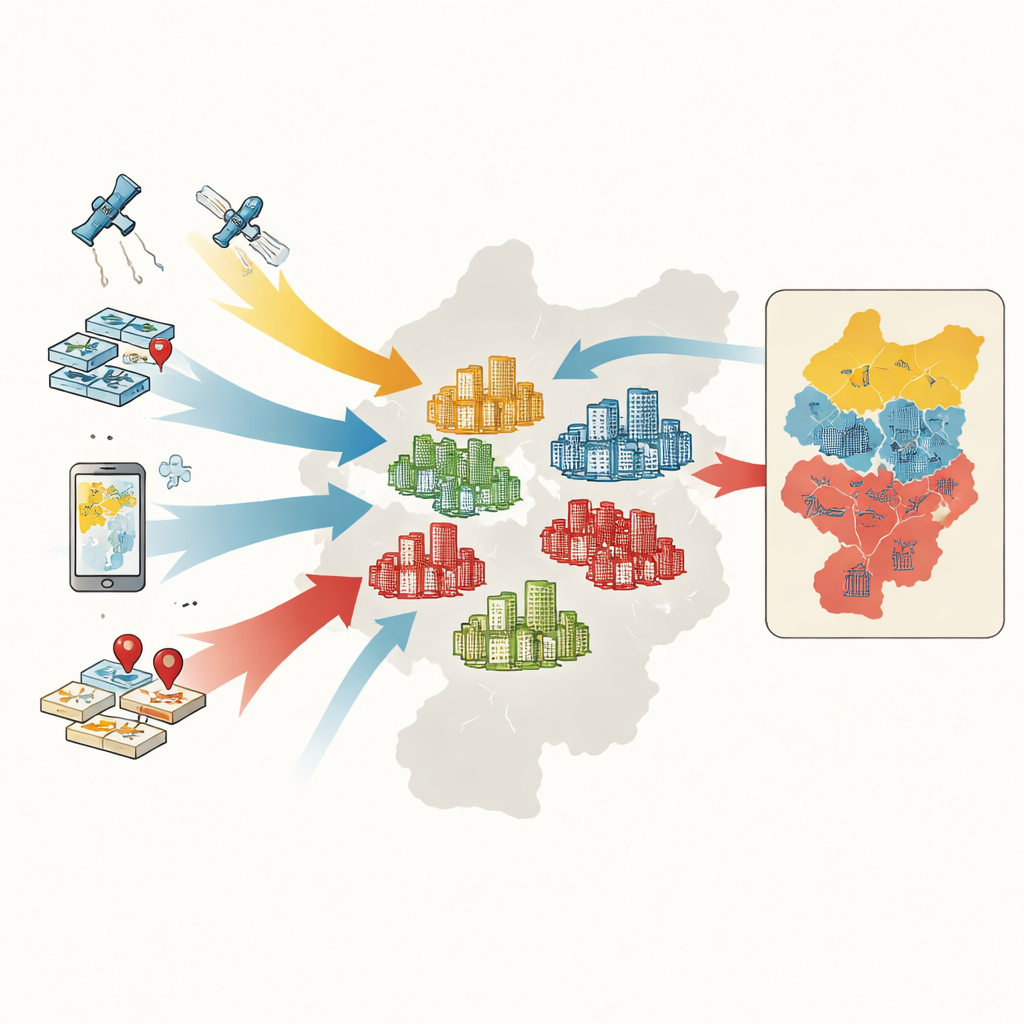
Od gospodarstw domowych do zespołów mieszkaniowych
Tradycyjne badania segregacji opierają się na danych spisowych, które liczą, ile osób zamożnych i mniej zamożnych mieszka w każdym obszarze, a następnie wyliczają wskaźniki separacji i różnorodności. Spisy są jednak rzadkie i szybko mogą się zdezaktualizować w szybko zmieniających się miastach. Niektórzy badacze próbowali obejść to, używając cen mieszkań jako zamiennika dochodu, przyjmując, że droższe domy zwykle oznaczają bogatszych mieszkańców. Inni łączą ceny mieszkań z obrazami satelitarnymi i punktami zainteresowania, takimi jak szkoły, sklepy czy parki. Te podejścia pomagają, ale często pomijają istotny fakt: nie każda powierzchnia ziemi jest równie zaludniona. Pusty teren przemysłowy na mapie może wyglądać na „biedny” tak samo jak zatłoczone, niskodochodowe osiedle, choć prawie nikt tam nie mieszka.
Widzieć sąsiedztwa przez pryzmat zespołów mieszkaniowych
W chińskich miastach większość mieszkańców żyje w wyraźnie wydzielonych zespołach mieszkaniowych — grupach bloków mieszkalnych z bramami, ogrodami i wspólnymi usługami. W obrębie takiego zespołu mieszkańcy mają tendencję do podobnego poziomu dochodów i stylu życia, ponieważ jakość budynków, ich wiek i otoczenie „filtrują” to, kto może lub chce tam mieszkać. W badaniu każdy zespół traktowany jest jako podstawowa jednostka analizy. Autorzy twierdzą, że jeśli można wiarygodnie sklasyfikować zespoły na wysokiej, średniej i niskiej klasy, można także wywnioskować prawdopodobne poziomy dochodów mieszkańców bez konieczności posiadania szczegółowych danych osobowych.
Przekształcanie big data w mapę całego miasta
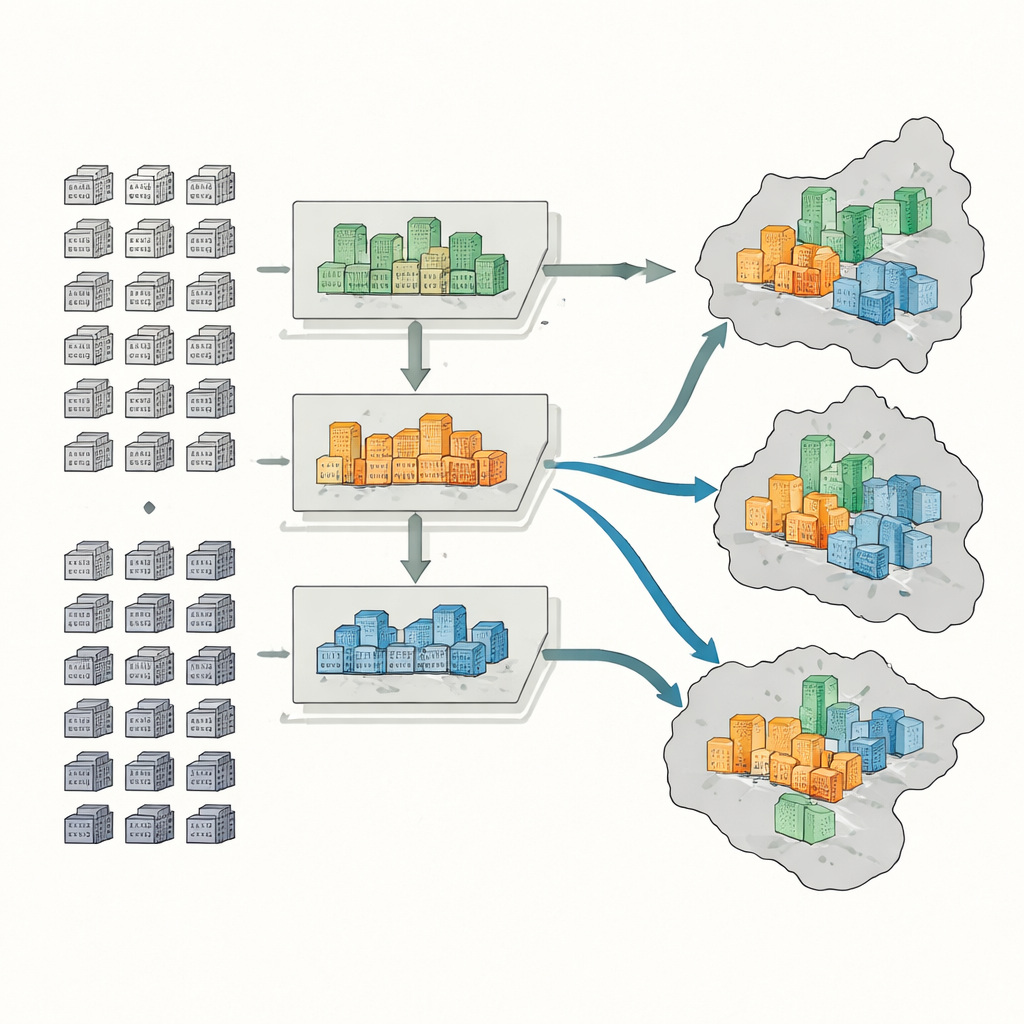
Aby sklasyfikować zespoły, badacze zgromadzili pięć rodzajów informacji: oficjalne mapy i granice, zapisy transakcji mieszkaniowych, cyfrowe zarysy obrysów zespołów z map online, satelitarne miary zieleni oraz tysiące punktów oznaczających usługi takie jak supermarkety, parki i przystanki transportu publicznego. Dla każdego zespołu zmierzyli sześć kluczowych cech: średnią cenę sprzedaży, wiek budynku, typ konstrukcji, stopień zazielenienia, dostęp do autobusów i metra oraz gęstość usług codziennych. Metoda uczenia maszynowego zwana lasem losowym uczy się wzorców w tych cechach i klasyfikuje ponad 4400 zespołów jako wysokiej, średniej lub niskiej klasy.
Pomiary kto mieszka gdzie
Następnie zespół szacuje, ile osób mieszka w każdym zespole, korzystając z liczby jednostek mieszkalnych i typowych wskaźników pustostanów, które różnią się w zależności od typu zespołu. Budynki z wyższej półki na przykład mają tendencję do większej liczby pustych mieszkań niż stare, niskoklasowe bloki w centrum. Potem mapują populacje wysokiej, średniej i niskiej klasy na dwóch skalach: dzielnic i mniejszych poddzielnic. Na tej podstawie obliczają trzy standardowe wskaźniki: indeks niesymetryczności pokazujący, jak wyraźna jest separacja między zamożnymi a mniej zamożnymi grupami; iloraz lokalizacji ujawniający, gdzie bogaci lub osoby o niskich dochodach są nietypowo skoncentrowane; oraz indeks różnorodności mierzący, jak równomiernie różne grupy dochodowe dzielą te same obszary.
Co ujawniają wzorce w Nankinie
Wyniki pokazują, że ogólnie główny obszar miejski Nankinu ma jedynie umiarkowany poziom separacji opartej na dochodach. Niemniej pewne dzielnice wyróżniają się. Jianye, mocno przebudowany obszar, ma wiele nowych zespołów wysokiej klasy i stosunkowo niewiele niskoklasowych, co prowadzi do silnej koncentracji zamożnych mieszkańców i wysokich wskaźników segregacji. Qinhuai, odwrotnie, zawiera wiele starszych, niskoklasowych zespołów i mniej luksusowych inwestycji, więc koncentruje mieszkańców o niższych dochodach. Inne dzielnice, takie jak Gulou i Qixia, wykazują bardziej mieszane wzory, z zabudową starą i nową obok siebie. W skali mniejszych poddzielnic niektóre miejsca okazują się bardzo mieszane, podczas gdy inne są zdominowane przez jedną grupę dochodową. Te wzorce zgadzają się z niezależnymi kontrolami opartymi na danych spisowych i cenach najmu, co sugeruje, że metoda odzwierciedla rzeczywiste podziały społeczne.
Dlaczego ta nowa perspektywa ma znaczenie
Dla osób niezwiązanych ze specjalistycznymi badaniami kluczowy wniosek jest taki, że teraz możemy śledzić segregację mieszkaniową bez oczekiwania lat na nowy spis. Dzięki traktowaniu zespołów mieszkaniowych jako „pojemników” dla grup społecznych i wprowadzaniu danych wieloźródłowych do algorytmu uczącego, autorzy dostarczają praktycznego skrótu: mogą oszacować, gdzie mieszkają różne grupy dochodowe, jak bardzo są one oddzielone i jak to różni się w obrębie miasta. Studium przypadku Nankinu pokazuje, że to podejście jest zarówno dokładne, jak i praktyczne. W miarę jak coraz więcej miast generuje bogate cyfrowe ślady — obrazy satelitarne, mapy online, ogłoszenia nieruchomości — metoda ta oferuje planistom i decydentom nowe narzędzie do monitorowania nierówności, ukierunkowywania inwestycji oraz oceny, czy projekty rewitalizacji miejskiej łączą ludzi, czy też pogłębiają ich rozdzielenie.
Cytowanie: Zhang, Y., Sun, Y., Zhu, AX. et al. Residential segregation assessment based on multi-source data and random forest method: a case study of Nanjing. Humanit Soc Sci Commun 13, 482 (2026). https://doi.org/10.1057/s41599-026-06840-w
Słowa kluczowe: segregacja miejska, zespoły mieszkaniowe, Nankin, dane geoprzestrzenne, nierówności mieszkaniowe