Clear Sky Science · sv
Oövervakad identifiering av riskfaktorer över cancertyper och datamodaliteter via förklarbar artificiell intelligens
Varför det är viktigt att hitta dolda riskmönster
Cancerläkare vet att personer med samma diagnos kan få mycket olika prognoser. Vissa svarar väl på behandling och lever i många år, medan andra inte gör det, även när sjukdomen ser likadan ut på pappret. Den här artikeln presenterar ett nytt sätt att låta datorer söka igenom rutinmässiga medicinska data och skanningar för att upptäcka dolda patientgrupper som delar liknande överlevnadschanser. Genom att omvandla detta till tydliga riskgrupper syftar arbetet till att stödja mer skräddarsydda behandlingsbeslut utan att kräva komplexa extra tester.
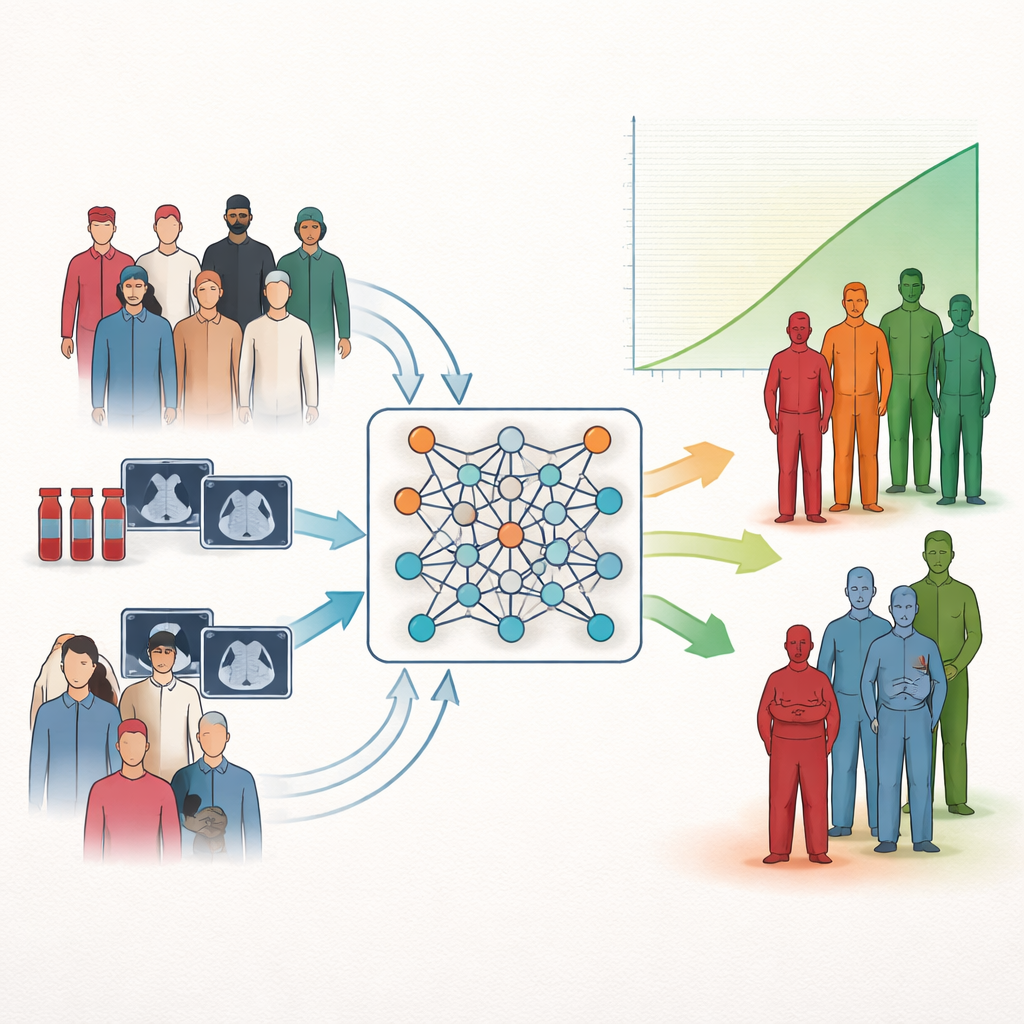
Ett nytt sätt att gruppera patienter efter utfall
Forskarna fokuserar på en vanlig uppgift inom medicinen: riskstratifiering, det vill säga att sortera patienter i grupper med bättre eller sämre prognos. Traditionella statistiska verktyg kan uppskatta hur enskilda mätvärden relaterar till överlevnad, men de kartlägger sig ofta inte enkelt till tydliga låg-, medel- eller högriskkategorier som kliniker kan använda vid sängkanten. Många moderna AI-system ökar styrkan men har ändå svårt att leverera klara, lätttolkade grupptillhörigheter. Författarna tar sig an detta gap genom att direkt lära neurala nätverk att bilda patientkluster som skiljer sig så mycket som möjligt i överlevnad, istället för att enbart försöka förutsäga överlevnadstid eller klustra patienter efter ytliga likheter.
Låta överlevnadsdata styra inlärningen
I kärnan av metoden ligger en omarbetning av en klassisk överlevnadsstatistik, känd som logrank-testet, till ett slätt (differentiellt) mål som ett neuralt nätverk kan optimera. Istället för att under träningen placera varje patient strikt i en grupp behandlar modellen grupptillhörighet som sannolikheter och justerar dem för att skärpa överlevnadsskillnaderna mellan kluster. En balanseringsterm hindrar den triviala lösningen där nästan alla patienter hamnar i samma kategori. Eftersom denna träningsrecept fungerar enbart som en förlustfunktion kan den kopplas in i många typer av neurala nätverk och många typer av indata utan att ändra deras interna design.
Vad metoden lärde sig från blodprov
För att visa kliniskt värde tillämpade teamet först sin metod på nästan tusen personer med multipelt myelom, en blodcancer, med endast tio standardiserade blodmätningar tagna i anslutning till diagnos. Deras nätverk bildade automatiskt tre riskgrupper vars överlevnadskurvor var tydligt åtskilda. Den sämsta gruppen hade en medianöverlevnad på ungefär fyra år, medan cirka sjuttio procent av den bästa gruppen fortfarande levde nio år senare. När författarna använde förklarbarhetsverktyg för att se vilka laboratorievärden som drev dessa grupptilldelningar, var välkända markörer för sjukdomsbörda och njurpåverkan, såsom beta-2-mikroglobulin och kreatinin, drivande mot högre risk, medan friskare nivåer av albumin och hemoglobin drog patienter mot lägre risk. Samma mönster fanns i en oberoende klinisk studie-dataset, vilket tyder på att de upptäckta grupperingarna är robusta.
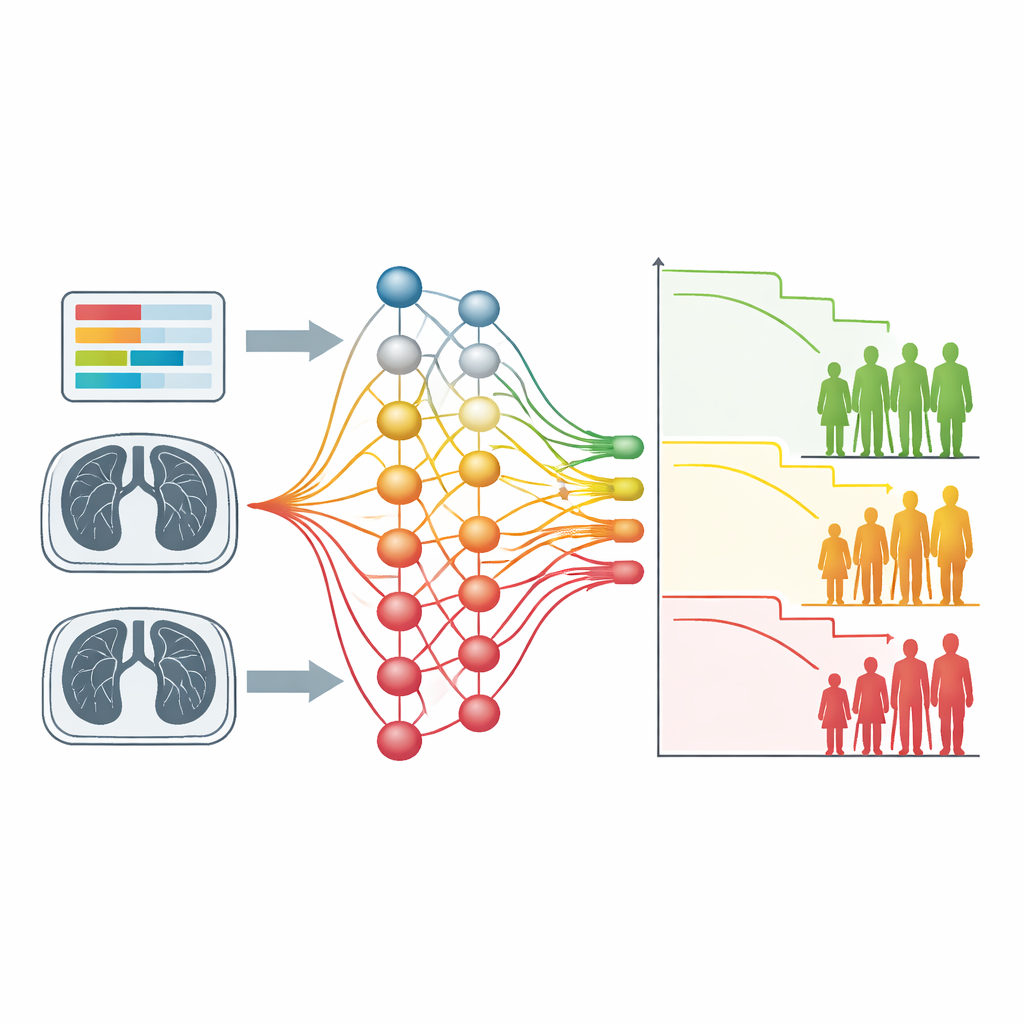
Vad metoden fann i lungröntgen
Det andra testfallet använde bröstkorgs-CT-bilder från hundratals personer med icke-småcellig lungcancer. Här var indata endast bilder, utan några handritade tumörkonturer eller förberäknade egenskaper. Ett konvolutionellt neuralt nätverk tränat med den nya förlustfunktionen delade patienter i två grupper med klart olika överlevnadstider, liknande mer arbetsintensiva radiomics-metoder. Visualiseringskartor för förklarbarhet avslöjade att modellen lärde sig att fokusera på lungregioner som innehöll tumörer och deras förgrenande, infiltrerande utbredning, samt närliggande strukturer som hjärtats kärl. Hos högriskpatienter tenderade dessa strukturer att bidra starkt till modellens beslut, vilket speglar klinisk kunskap om att infiltrativ tillväxt och hjärtsjukdom är kopplade till sämre utfall.
Hur detta kan påverka framtida cancervård
Sammanfattningsvis visar studien att överlevnadsstyrd klustring kan återupptäcka kända riskfaktorer från både enkla blodprov och komplexa skanningar, och kan göra det utan manuell märkning eller handbyggda regler. Eftersom samma träningsrecept fungerar över cancerformer och datatyper erbjuder det en flexibel utgångspunkt för att utforska nya prognostiska mönster, inklusive områden som genuttrycksprofiler eller tidsvarierande behandlingsdata. För patienter är det långsiktiga löftet tydligare riskkategorier som uppstår direkt från deras egna data och som hjälper kliniker att anpassa intensitet och inriktning på behandlingen efter risknivån, samtidigt som forskare får ett verktyg för att upptäcka nya signaler kopplade till utfall.
Citering: Ferle, M., Ader, J., Wiemers, T. et al. Unsupervised risk factor identification across cancer types and data modalities via explainable artificial intelligence. npj Digit. Med. 9, 363 (2026). https://doi.org/10.1038/s41746-026-02663-w
Nyckelord: cancer riskstratifiering, överlevnadsanalys, medicinsk bild‑AI, multipelt myelom, lungcancer