Clear Sky Science · es
Identificación no supervisada de factores de riesgo entre tipos de cáncer y modalidades de datos mediante inteligencia artificial explicable
Por qué importa encontrar patrones de riesgo ocultos
Los oncólogos saben que personas con el mismo diagnóstico pueden tener futuros muy diferentes. Algunos responden bien al tratamiento y viven muchos años, mientras que otros no, aun cuando su enfermedad parezca similar sobre el papel. Este artículo presenta una nueva forma de permitir que los ordenadores examinen datos médicos rutinarios y escáneres para descubrir grupos ocultos de pacientes que comparten probabilidades similares de supervivencia. Al convertir esto en categorías de riesgo claras, el trabajo pretende apoyar decisiones de tratamiento más personalizadas sin exigir pruebas adicionales complejas.
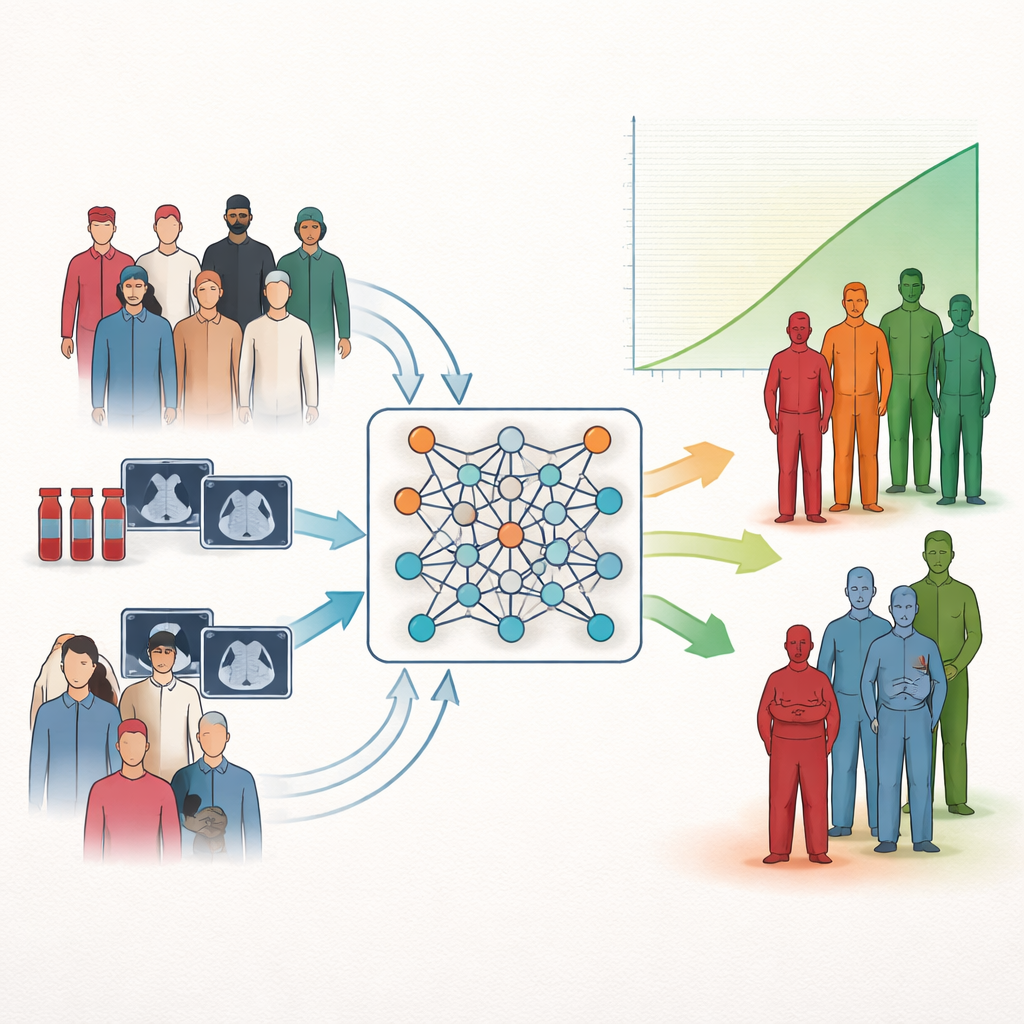
Una nueva manera de agrupar pacientes según el resultado
Los investigadores se centran en una tarea común en medicina: la estratificación del riesgo, que consiste en clasificar a los pacientes en grupos con mejor o peor pronóstico. Las herramientas estadísticas tradicionales pueden estimar cómo mediciones individuales se relacionan con la supervivencia, pero a menudo no se traducen de forma nítida en categorías sencillas de bajo, medio o alto riesgo que los clínicos puedan usar en la práctica. Muchos sistemas modernos de inteligencia artificial añaden potencia pero siguen sin ofrecer agrupaciones claras y fáciles de interpretar. Los autores abordan esta brecha enseñando directamente a las redes neuronales a formar conglomerados de pacientes que difieran tanto como sea posible en supervivencia, en lugar de limitarse a predecir el tiempo de supervivencia o a agrupar pacientes por similitud superficial.
Dejar que los datos de supervivencia guíen el aprendizaje
En el corazón del método está la reconfiguración de una estadística clásica de supervivencia, conocida como la prueba log-rank, en un objetivo diferenciable que una red neuronal puede optimizar. En lugar de asignar a cada paciente de forma rígida a un grupo durante el entrenamiento, el modelo trata la pertenencia a grupos como probabilidades y las ajusta para acentuar las diferencias de supervivencia entre los clústeres. Un término de balance evita la solución trivial en la que casi todos los pacientes caen en la misma categoría. Como esta receta de entrenamiento actúa solo como una función de pérdida, puede incorporarse a muchos tipos de redes neuronales y a distintos tipos de datos de entrada sin cambiar su diseño interno.
Lo que el método aprendió a partir de análisis de sangre
Para mostrar valor clínico, el equipo aplicó primero su enfoque a casi mil personas con mieloma múltiple, un cáncer de la sangre, usando solo diez mediciones sanguíneas estándar tomadas alrededor del diagnóstico. Su red formó automáticamente tres grupos de riesgo cuyas curvas de supervivencia estaban claramente separadas. El grupo de peor pronóstico tuvo una supervivencia mediana de aproximadamente cuatro años, mientras que alrededor del setenta por ciento del mejor grupo seguía vivo nueve años después. Cuando los autores emplearon herramientas de explicabilidad para ver qué valores de laboratorio impulsaban estas agrupaciones, marcadores bien conocidos de carga tumoral y de estrés renal, como la beta-2-microglobulina y la creatinina, empujaban a los pacientes hacia mayor riesgo, mientras que niveles más saludables de albúmina y hemoglobina los orientaban hacia menor riesgo. Los mismos patrones se mantuvieron en un conjunto de datos de un ensayo clínico independiente, lo que sugiere que las agrupaciones descubiertas son robustas.
Lo que el método encontró en escáneres de pulmón
El segundo caso de prueba utilizó tomografías computarizadas de tórax de cientos de personas con cáncer de pulmón no microcítico. Aquí la entrada fue solo la imagen, sin contornos de tumor trazados a mano ni características precomputadas. Una red neuronal convolucional entrenada con la nueva función de pérdida dividió a los pacientes en dos grupos con tiempos de supervivencia claramente diferentes, similar a enfoques radiómicos más laboriosos. Mapas de explicación visual revelaron que el modelo había aprendido a centrarse en regiones pulmonares que contenían tumores y sus extensiones ramificadas e infiltrativas, así como en estructuras cercanas como vasos del corazón. En pacientes de alto riesgo, estas estructuras tendían a contribuir fuertemente a las decisiones del modelo, lo que concuerda con el conocimiento clínico de que el crecimiento infiltrativo y la enfermedad cardiaca están vinculados a peores resultados.
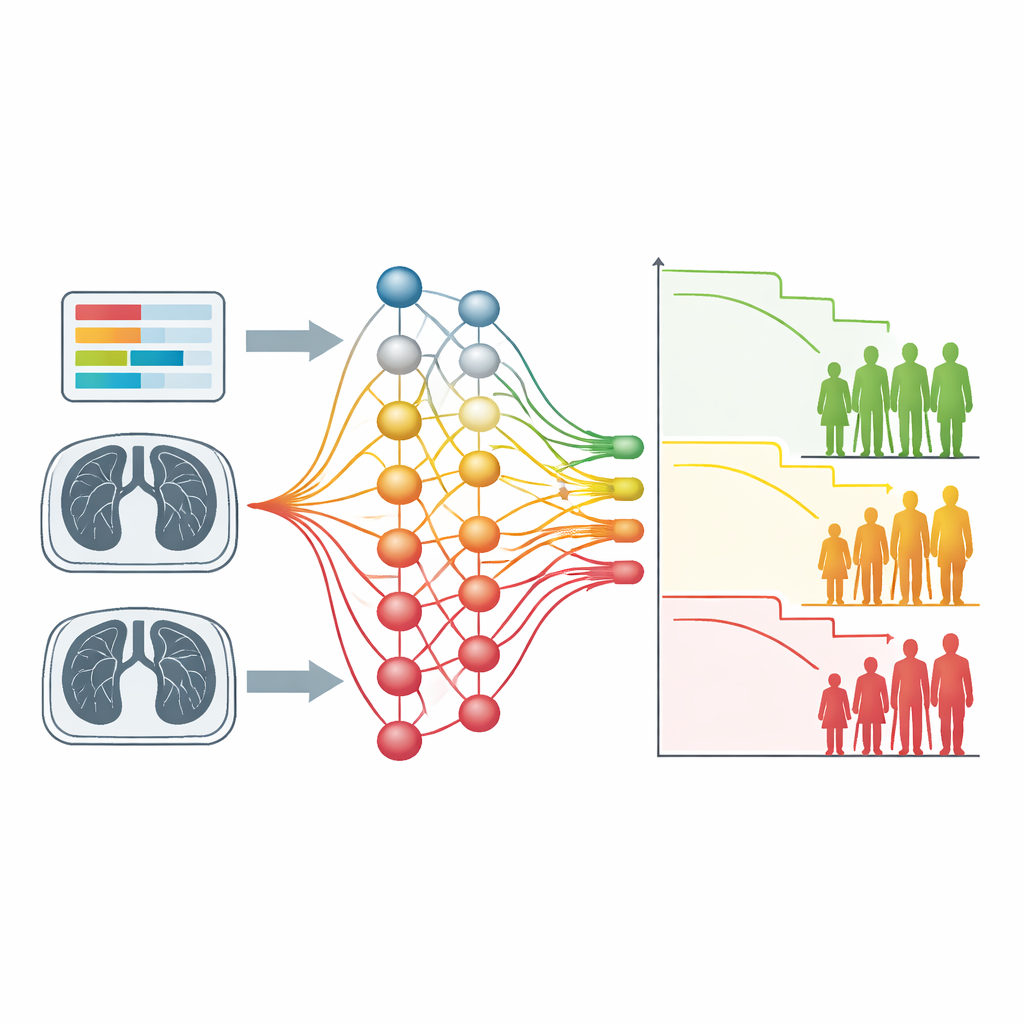
Cómo esto podría influir en la atención del cáncer en el futuro
En conjunto, el estudio muestra que el agrupamiento guiado por supervivencia puede redescubrir factores de riesgo conocidos tanto a partir de simples análisis de sangre como de escáneres complejos, y puede hacerlo sin etiquetado manual ni reglas hechas a mano. Debido a que la misma receta de entrenamiento funciona a través de distintos cánceres y tipos de datos, ofrece un punto de partida flexible para explorar nuevos patrones pronósticos, incluso en áreas como perfiles de actividad génica o datos de tratamiento que varían en el tiempo. Para los pacientes, la promesa a largo plazo son categorías de riesgo más claras que surgen directamente de sus propios datos y que ayudan a los clínicos a ajustar la intensidad y el estilo de la terapia al nivel de riesgo, mientras que los investigadores obtienen una herramienta para detectar nuevas señales vinculadas al resultado.
Cita: Ferle, M., Ader, J., Wiemers, T. et al. Unsupervised risk factor identification across cancer types and data modalities via explainable artificial intelligence. npj Digit. Med. 9, 363 (2026). https://doi.org/10.1038/s41746-026-02663-w
Palabras clave: estratificación del riesgo en cáncer, análisis de supervivencia, IA en imagen médica, mieloma múltiple, cáncer de pulmón