Clear Sky Science · he
זיהוי גורמי סיכון בלתי מפוקחים בחצאי סרטן ומודאליות נתונים שונות באמצעות בינה מלאכותית ברת-הסביר
מדוע גילוי דפוסי סיכון סמויים חשוב
רופאי סרטן יודעים שאנשים עם אותה אבחנה יכולים לעתים קרובות לחוות עתיד שונה מאוד. חלקם מגיבים היטב לטיפול וחיים שנים רבות, בעוד אחרים אינם זוכים לכך, גם אם המחלה שלהם נראית דומה במסמכים. מאמר זה מציג דרך חדשה לאפשר למחשבים לסרוק נתונים רפואיים שגרתיים וסריקות כדי לגלות קבוצות חולים סמויות שמשתפות סיכויי הישרדות דומים. בהפיכת הממצאים לקבוצות סיכון ברורות, העבודה שואפת לתמוך בהחלטות טיפוליות מותאמות יותר מבלי לדרוש בדיקות נוספות מורכבות.
דרך חדשה לקיבוץ חולים לפי תוצאה
החוקרים מתמקדים במשימה נפוצה ברפואה: סיווג סיכון, כלומר מיון חולים לקבוצות עם פרוספקטיבה טובה יותר או גרועה יותר. כלים סטטיסטיים מסורתיים יכולים לאמוד כיצד מדידות فردיות מתקשרות להישרדות, אך לרוב הם אינם מתורגמים בצורה נקייה לקטגוריות פשוטות של סיכון נמוך, בינוני או גבוה שניתן להשתמש בהן קלינית. מערכות בינה מלאכותית מודרניות רבות מוסיפות כוח חיזוי אך עדיין מתקשות לספק קיבוצים ברורים וקלים לפרשנות. המחברים מתמודדים עם הפער הזה על־ידי לימוד ישיר של רשתות נוירונים ליצור אשכולות חולים שמבדילים זה מזה ככל האפשר מבחינת הישרדות, במקום רק לנסות לנבא זמן הישרדות עצמו או לקבץ חולים לפי דמיון חיצוני.
הנעה של הלמידה באמצעות נתוני הישרדות
בלב השיטה עומד עיבוד מחדש של סטטיסטיקת הישרדות קלאסית, המכונה מבחן הלוגרנק, לאובייקטיב חלק שיכול להיות מותאם על־ידי רשת נוירונים. במקום למקם כל מטופל באופן מוחלט בקבוצה במהלך האימון, המודל מטפל בחברות בקבוצה כהסתברויות ומעדן אותן כדי לחדד את הבדלי ההישרדות בין האשכולות. מונח איזון מונע פתרון טריוויאלי שבו בעיקר החולים נופלים לאותה קטגוריה. מאחר שמתכון האימון הזה פועל אך ורק כפונקציית אובדן, ניתן לשלבו לסוגים רבים של רשתות נוירונים ולסוגי קלט שונים מבלי לשנות את המבנה הפנימי שלהם.
מה שלמדה השיטה מבדיקות דם
כדי להדגים ערך קליני, הצוות יישם תחילה את הגישה על כמעט אלף אנשים עם מיאלומה נפוצה, סרטן של הדם, באמצעות עשר מדידות דם סטנדרטיות בלבד שנלקחו סביב האבחון. הרשת שלהם יצרה באופן אוטומטי שלוש קבוצות סיכון עקומות הישרדותיהן היו מופרדות בבירור. הקבוצה הגרועה ביותר נהנתה מהישרדות חציונית של כארבע שנים, בעוד שכ־70% מהקבוצה הטובה ביותר היו עדיין בחיים תשע שנים לאחר מכן. כשהמחברים השתמשו בכלי פרשנות כדי לזהות אילו ערכי מעבדה הניעו את הקיבוצים הללו, סמנים ידועים של עומס מחלה ועומס כלייתי, כגון ביתא-2-מיקרוגלובולין וקריאטינין, דחפו מטופלים לעבר סיכון גבוה יותר, בעוד רמות בריאות יותר של אלבומין והמוגלובין משכו אותם לעבר סיכון נמוך יותר. אותם דפוסים הופיעו גם במאגר נתונים של ניסוי קליני עצמאי, מה שמרמז שהקיבוצים שזוהו עמידים.
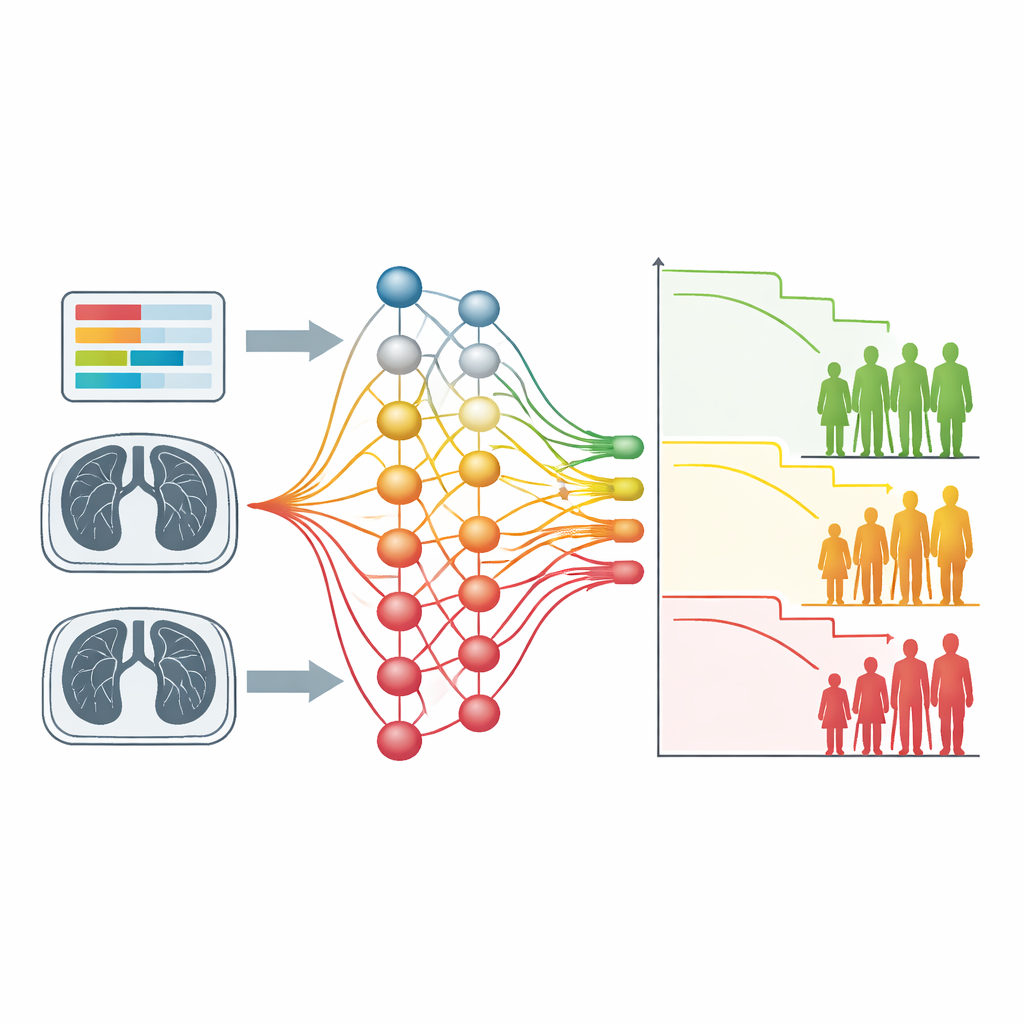
מה מצאה השיטה בסריקות ריאה
מקרי הבדיקה השני השתמש בסריקות CT של בית חזה ממאות אנשים עם סרטן ריאה שאינו תאי קטנה. כאן הקלט היה תמונה בלבד, ללא מתארי גידול שנוסחו ביד או תכונות מחושבות מראש. רשת קונבולוציה שאומנה עם פונקציית האובדן החדשה חילקה את החולים לשתי קבוצות עם זמני הישרדות שונים באופן בולט, בדומה לשיטות רדיומיקס הדורשות עבודה רבה יותר. מפות הסבר חזותיות חשפו שהמודל למד להתמקד באזורים בריאות שהכילו גידולים והשתתרעויות חדירות שלהם, וכן במבנים סמוכים כגון כלי דם של הלב. בחולים בסיכון גבוה, מבנים אלה נטו לתרום בחוזקה להחלטות המודל, דבר המשקף ידע קליני שצמיחה חודרת ומחלות לב מקושרות לתוצאות גרועות יותר.
כיצד זה עשוי לעצב את טיפולי הסרטן בעתיד
בסך הכל, המחקר מראה כי קיבוץ מונחה הישרדות יכול לגלות מחדש גורמי סיכון מוכרים הן מבדיקות דם פשוטות והן מסריקות מורכבות, ויכול לעשות זאת ללא תיוג ידני או כללים מעוצבים. מאחר שאותו מתכון אימון עובד על פני סוגי סרטן ונתונים שונים, הוא מציע נקודת התחלה גמישה לחקר דפוסי פרוגנוזה חדשים, כולל בתחומים כמו פרופילי פעילות גנים או נתוני טיפול משתנים בזמן. עבור מטופלים, ההבטחה ארוכת הטווח היא קטגוריות סיכון ברורות הנובעות ישירות מהנתונים האישיים שלהם ועוזרות לרופאים להתאים את עוצמת וסוג הטיפול לרמת הסיכון, בעוד שחוקרים מקבלים כלי לגילוי אותות חדשים הקשורים לתוצאה.
ציטוט: Ferle, M., Ader, J., Wiemers, T. et al. Unsupervised risk factor identification across cancer types and data modalities via explainable artificial intelligence. npj Digit. Med. 9, 363 (2026). https://doi.org/10.1038/s41746-026-02663-w
מילות מפתח: סיווג סיכון בסרטן, אנליזת הישרדות, בינה מלאכותית בדימות רפואי, מיאלומה נפוצה, סרטן הריאה