Clear Sky Science · fr
Identification non supervisée de facteurs de risque à travers les types de cancer et les modalités de données via une intelligence artificielle explicable
Pourquoi il est important de déceler des motifs de risque cachés
Les oncologues savent que des personnes ayant le même diagnostic peuvent voir leur avenir diverger fortement. Certaines répondent bien aux traitements et vivent de nombreuses années, tandis que d'autres ne le font pas, même lorsque leur maladie paraît similaire sur le papier. Cet article présente une nouvelle manière de laisser les ordinateurs explorer les données médicales et les scanners de routine pour découvrir des groupes cachés de patients partageant des chances de survie comparables. En traduisant cela en catégories de risque claires, le travail vise à soutenir des décisions thérapeutiques plus personnalisées sans exiger d'examens supplémentaires complexes.
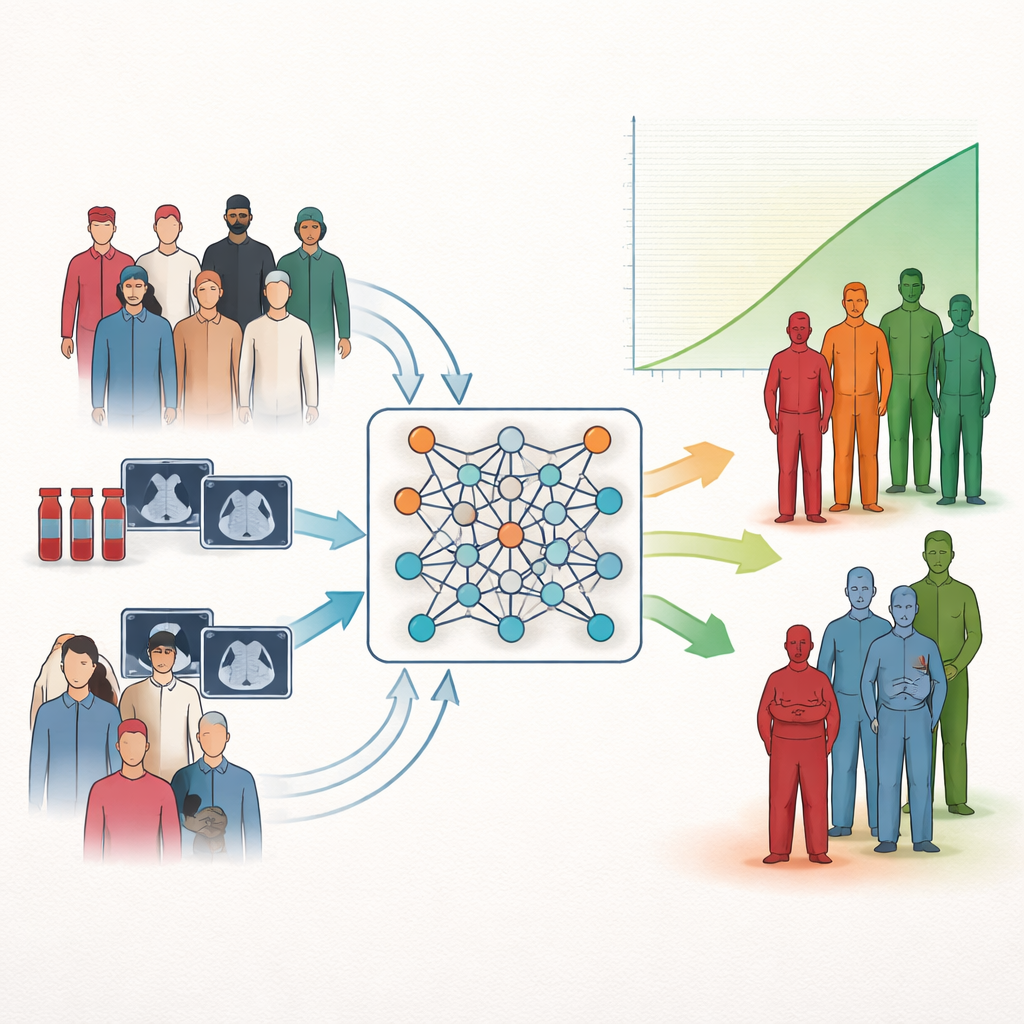
Une nouvelle façon de regrouper les patients selon l’issue
Les chercheurs s’intéressent à une tâche courante en médecine : la stratification du risque, c’est-à-dire trier les patients en groupes au pronostic meilleur ou pire. Les outils statistiques traditionnels peuvent estimer comment des mesures individuelles se rapportent à la survie, mais ils n’offrent souvent pas de correspondance simple avec des catégories de risque basses, moyennes ou élevées que les cliniciens peuvent utiliser au chevet. Nombre de systèmes d’intelligence artificielle modernes apportent de la puissance mais peinent encore à produire des regroupements nets et faciles à interpréter. Les auteurs comblent cette lacune en apprenant directement aux réseaux neuronaux à former des clusters de patients qui diffèrent autant que possible en termes de survie, plutôt que de se contenter de prédire le temps de survie ou de grouper les patients par similarité superficielle.
Laisser les données de survie guider l’apprentissage
Au cœur de la méthode se trouve une réécriture d’un statistic classique en survie, connu sous le nom de test du logrank, en un objectif lissé qu’un réseau neuronal peut optimiser. Plutôt que d’affecter chaque patient de façon binaire à un groupe pendant l’entraînement, le modèle traite l’appartenance aux groupes comme des probabilités et les ajuste pour accentuer les différences de survie entre les clusters. Un terme d’équilibrage évite la solution triviale où presque tous les patients se retrouvent dans la même catégorie. Comme cette recette d’entraînement agit uniquement comme une fonction de perte, elle peut être intégrée à de nombreux types de réseaux neuronaux et à différents types de données d’entrée sans modifier leur architecture interne.
Ce que la méthode a appris à partir des analyses sanguines
Pour démontrer une valeur clinique, l’équipe a d’abord appliqué son approche à près d’un millier de personnes atteintes de myélome multiple, un cancer du sang, en n’utilisant que dix analyses sanguines standard prélevées autour du diagnostic. Leur réseau a automatiquement formé trois groupes de risque dont les courbes de survie étaient clairement séparées. Le groupe le plus défavorisé avait une survie médiane d’environ quatre ans, tandis qu’environ soixante-dix pour cent du meilleur groupe étaient encore en vie neuf ans plus tard. Lorsque les auteurs ont utilisé des outils d’explicabilité pour identifier quelles valeurs de laboratoire avaient poussé ces regroupements, des marqueurs bien connus de la charge tumorale et de la souffrance rénale, tels que la bêta-2-microglobuline et la créatinine, ont orienté les patients vers un risque plus élevé, alors que des niveaux plus sains d’albumine et d’hémoglobine les ont attirés vers un risque plus faible. Les mêmes schémas se sont retrouvés dans un jeu de données d’un essai clinique indépendant, suggérant que les groupements découverts sont robustes.
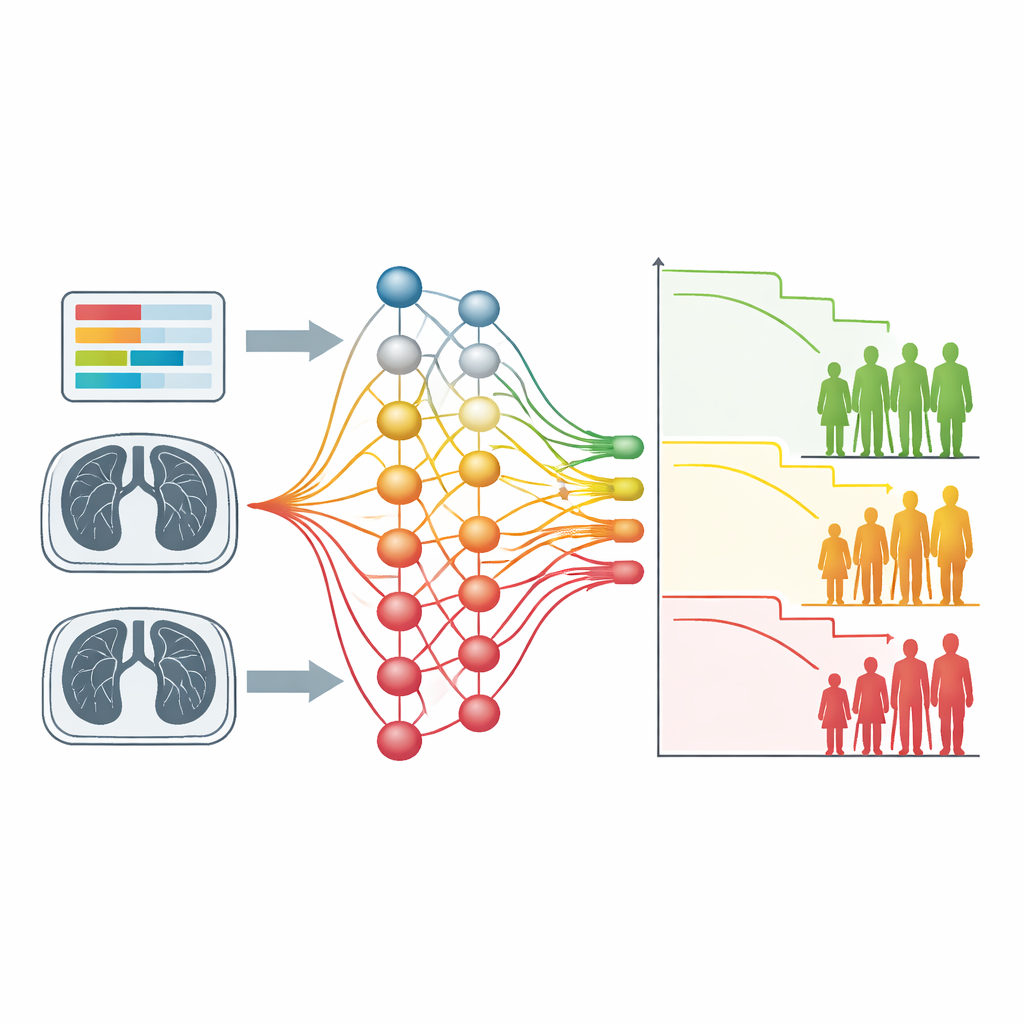
Ce que la méthode a trouvé dans les scanners pulmonaires
Le second cas d’essai a utilisé des scanners thoraciques de centaines de personnes atteintes d’un cancer bronchique non à petites cellules. Ici, l’entrée était uniquement l’imagerie, sans contours de tumeur dessinés à la main ni caractéristiques précalculées. Un réseau de neurones convolutionnel entraîné avec la nouvelle fonction de perte a séparé les patients en deux groupes ayant des temps de survie clairement différents, de façon comparable à des approches radiomiques plus laborieuses. Des cartes d’explication visuelle ont révélé que le modèle avait appris à se concentrer sur les régions pulmonaires contenant des tumeurs et leurs extensions infiltrantes et ramifiées, ainsi que sur des structures voisines comme les vaisseaux cardiaques. Chez les patients à haut risque, ces structures contribuaient fortement aux décisions du modèle, rappelant la connaissance clinique selon laquelle la croissance infiltrante et les maladies cardiaques sont liées à de moins bons résultats.
Comment cela pourrait influencer les soins du cancer à l’avenir
Dans l’ensemble, l’étude montre que le clustering guidé par la survie peut redécouvrir des facteurs de risque connus à la fois à partir d’analyses sanguines simples et d’images complexes, et ce, sans étiquetage manuel ni règles artisanales. Parce que la même recette d’entraînement fonctionne pour divers cancers et types de données, elle offre un point de départ flexible pour explorer de nouveaux motifs pronostiques, y compris dans des domaines comme les profils d’activité génique ou les données de traitement variant dans le temps. Pour les patients, la promesse à long terme est celle de catégories de risque plus claires issues directement de leurs propres données et aidant les cliniciens à adapter l’intensité et le type de thérapie au niveau de risque, tandis que les chercheurs disposent d’un outil pour repérer de nouveaux signaux associés aux issues.
Citation: Ferle, M., Ader, J., Wiemers, T. et al. Unsupervised risk factor identification across cancer types and data modalities via explainable artificial intelligence. npj Digit. Med. 9, 363 (2026). https://doi.org/10.1038/s41746-026-02663-w
Mots-clés: stratification du risque en oncologie, analyse de survie, IA en imagerie médicale, myélome multiple, cancer du poumon