Clear Sky Science · pl
Identyfikacja czynników ryzyka bez nadzoru w różnych typach nowotworów i modalnościach danych za pomocą wyjaśnialnej sztucznej inteligencji
Dlaczego znalezienie ukrytych wzorców ryzyka ma znaczenie
Lekarze onkolodzy wiedzą, że osoby z tym samym rozpoznaniem mogą mieć bardzo różne perspektywy. Niektórzy dobrze reagują na leczenie i żyją przez wiele lat, inni — mimo podobnego obrazu choroby — mają znacznie gorsze rokowania. W artykule przedstawiono nowy sposób pozwalający komputerom przeszukiwać rutynowe dane medyczne i skany, by odkryć ukryte grupy pacjentów o podobnym prawdopodobieństwie przeżycia. Przekształcając to w czytelne kategorie ryzyka, praca ma wspierać bardziej spersonalizowane decyzje terapeutyczne bez potrzeby kosztownych dodatkowych badań.
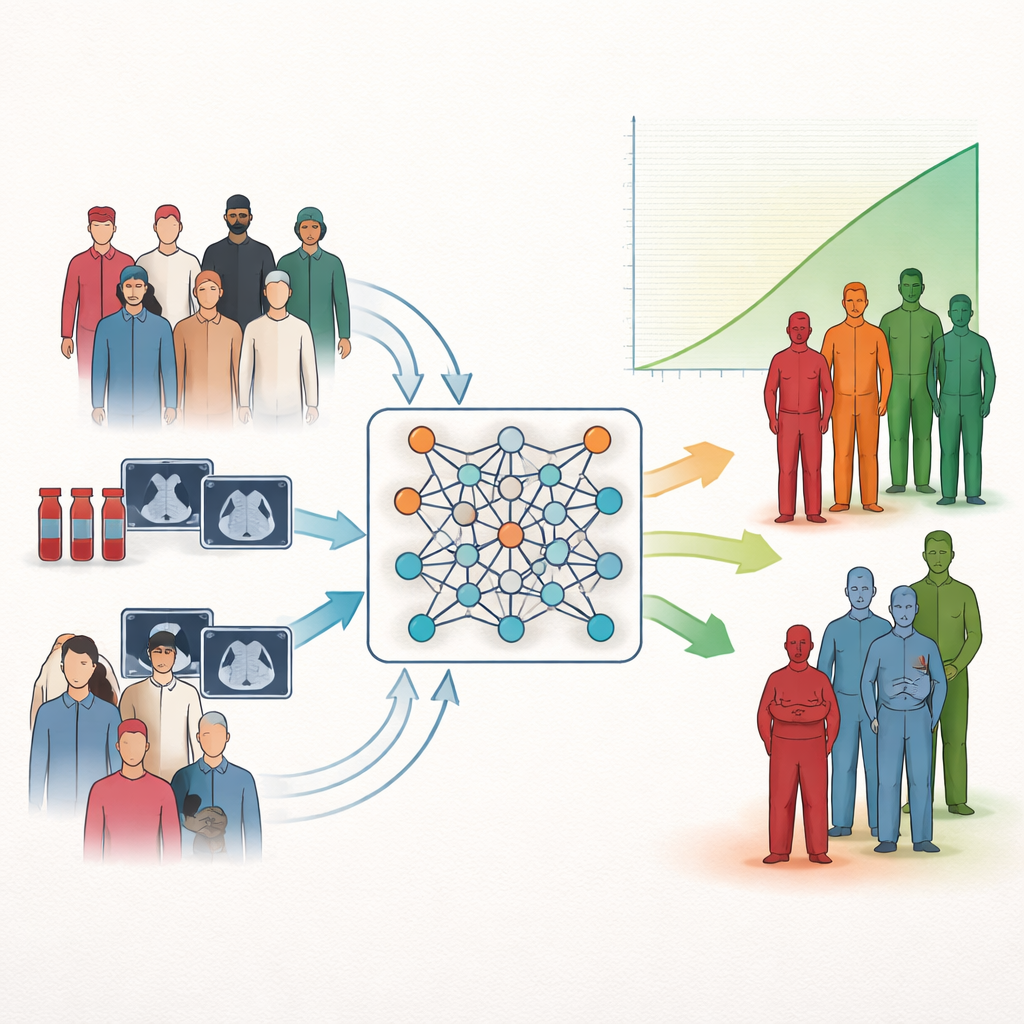
Nowy sposób grupowania pacjentów według przebiegu
Badacze koncentrują się na powszechnym zadaniu w medycynie: stratyfikacji ryzyka, czyli sortowaniu pacjentów na grupy z lepszym lub gorszym rokowaniem. Tradycyjne narzędzia statystyczne potrafią oszacować, jak poszczególne pomiary wiążą się z przeżyciem, ale często nie przekładają się one w prosty sposób na niskie, średnie lub wysokie ryzyko, z których klinicyści mogliby łatwo korzystać przy łóżku pacjenta. Wiele nowoczesnych systemów sztucznej inteligencji zwiększa możliwości, lecz nadal ma problem z dostarczaniem wyraźnych, łatwych w interpretacji grup. Autorzy wypełniają tę lukę, ucząc sieci neuronowe bezpośrednio formować klastry pacjentów, które różnią się między sobą jak najbardziej pod względem przeżycia, zamiast jedynie przewidywać czas przeżycia czy grupować pacjentów według powierzchownych podobieństw.
Pozwalanie danym o przeżyciu kierować uczeniem
Rdzeniem metody jest przekształcenie klasycznej statystyki przeżycia, znanej jako test log-rank, w gładki cel optymalizacyjny, który sieć neuronowa może maksymalizować. Zamiast przypisywać każdego pacjenta jednoznacznie do jednej grupy w trakcie treningu, model traktuje przynależność do grup jako prawdopodobieństwa i dostosowuje je, by wyostrzyć różnice przeżycia między klastrami. Dodatkowy termin równoważący zapobiega trywialnemu rozwiązaniu, w którym niemal wszyscy pacjenci trafiają do tej samej kategorii. Ponieważ ten przepis treningowy działa wyłącznie jako funkcja straty, można go włączyć do wielu rodzajów sieci neuronowych i różnych typów danych wejściowych bez zmiany ich wewnętrznej architektury.
Czego metoda nauczyła się z badań krwi
Aby pokazać wartość kliniczną, zespół najpierw zastosował swoje podejście do niemal tysiąca osób ze szpiczakiem mnogim, nowotworem krwi, używając jedynie dziesięciu standardowych pomiarów krwi wykonanych w okolicach rozpoznania. Ich sieć automatycznie utworzyła trzy grupy ryzyka, których krzywe przeżycia były wyraźnie rozdzielone. Najgorzej rokująca grupa miała medianę przeżycia około czterech lat, podczas gdy około siedemdziesiąt procent najlepszej grupy wciąż żyło po dziewięciu latach. Gdy autorzy użyli narzędzi wyjaśniających, by sprawdzić, które wartości laboratoryjne napędzały te grupowania, dobrze znane markery obciążenia chorobowego i problemów nerkowych, takie jak beta-2-mikroglobulina i kreatynina, przesuwały pacjentów w stronę wyższego ryzyka, podczas gdy zdrowsze poziomy albuminy i hemoglobiny przyciągały ich ku niższemu ryzyku. Te same wzorce utrzymywały się w niezależnym zbiorze danych z badania klinicznego, co sugeruje, że odkryte grupowania są trwałe.
Czego metoda znalazła w skanach płuc
Drugi przypadek testowy wykorzystał tomografie komputerowe klatki piersiowej setek osób z niedrobnokomórkowym rakiem płuca. Tutaj wejściem były wyłącznie obrazy, bez ręcznie rysowanych obrysów guzów czy wstępnie obliczonych cech. Splotowa sieć neuronowa trenowana z nową funkcją straty podzieliła pacjentów na dwie grupy o wyraźnie różnym czasie przeżycia, podobnie jak bardziej pracochłonne podejścia radiomiczne. Mapy wizualnych wyjaśnień ujawniły, że model nauczył się skupiać na regionach płuc zawierających guzy i ich rozgałęziające, naciekające przedłużenia, a także pobliskich strukturach, takich jak naczynia serca. U pacjentów o wysokim ryzyku te struktury miały zwykle silny wkład w decyzje modelu, co odzwierciedla kliniczną wiedzę, że wzrost naciekowy i choroby serca wiążą się z gorszymi wynikami.
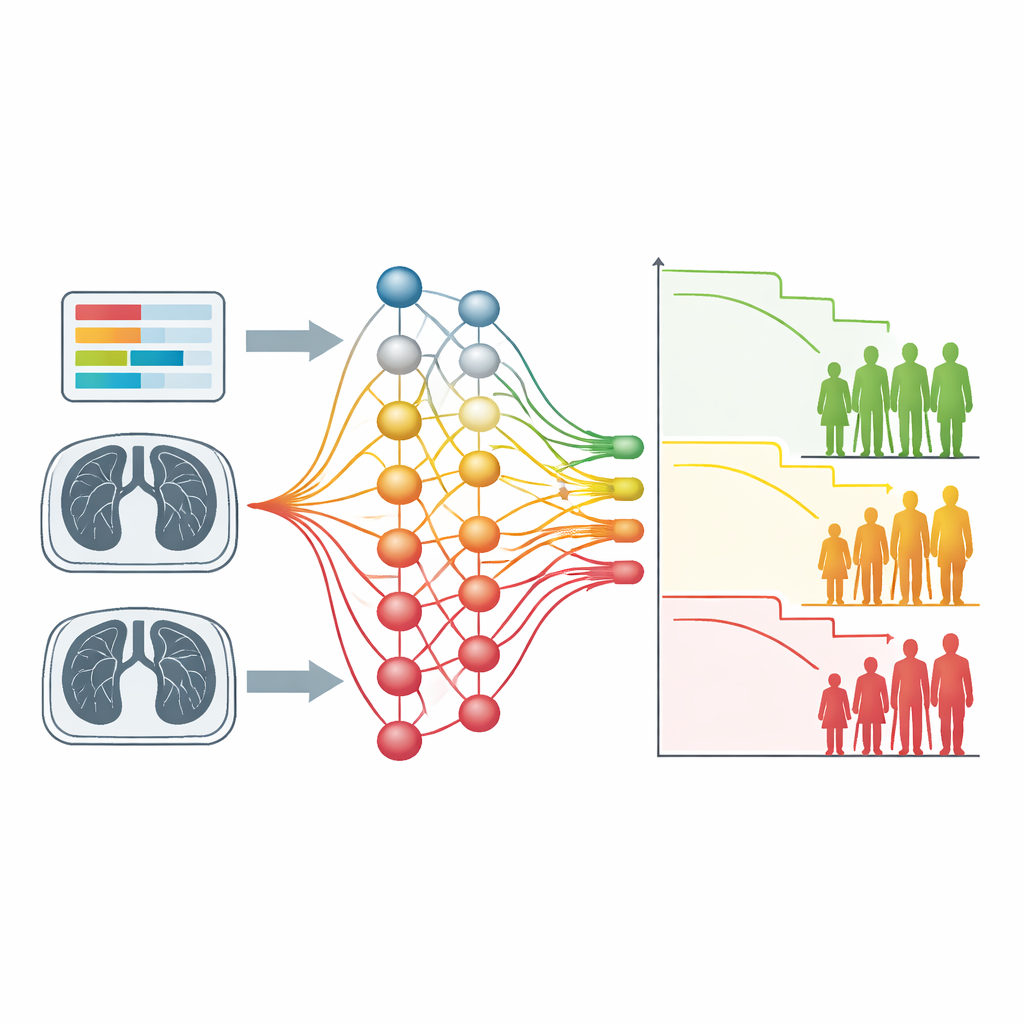
Jak to może kształtować przyszłą opiekę onkologiczną
Podsumowując, badanie pokazuje, że klasteryzacja prowadzona przeżywalnością może na nowo odkryć znane czynniki ryzyka zarówno z prostych badań krwi, jak i złożonych skanów, i może to robić bez ręcznego etykietowania czy reguł tworzonych ręcznie. Ponieważ ten sam przepis treningowy działa w różnych nowotworach i dla różnych typów danych, oferuje elastyczny punkt wyjścia do badania nowych wzorców prognostycznych, także w obszarach takich jak profile aktywności genów czy dane o zmieniającym się w czasie leczeniu. Dla pacjentów długoterminowa obietnica to wyraźniejsze kategorie ryzyka wynikające bezpośrednio z ich własnych danych, które pomagają klinicystom dopasować intensywność i rodzaj terapii do poziomu ryzyka, a dla badaczy — narzędzie do wychwytywania nowych sygnałów powiązanych z wynikami.
Cytowanie: Ferle, M., Ader, J., Wiemers, T. et al. Unsupervised risk factor identification across cancer types and data modalities via explainable artificial intelligence. npj Digit. Med. 9, 363 (2026). https://doi.org/10.1038/s41746-026-02663-w
Słowa kluczowe: stratyfikacja ryzyka nowotworowego, analiza przeżycia, AI w obrazowaniu medycznym, szpiczak mnogi, rak płuca