Clear Sky Science · ru
Неразмеченное выявление факторов риска между типами рака и модальностями данных с помощью объяснимого искусственного интеллекта
Почему важно находить скрытые паттерны риска
Онкологи хорошо знают: пациенты с одинаковым диагнозом могут иметь совсем разные перспективы. Кому‑то лечение помогает и они живут много лет, другим — нет, хотя по документам болезнь выглядит похоже. В статье представлен новый способ дать компьютерам возможность просеивать рутинные медицинские данные и снимки, чтобы обнаруживать скрытые группы пациентов с похожими шансами на выживание. Переводя это в понятные категории риска, подход призван помогать более персонализированным решениям по лечению без необходимости в сложных дополнительных тестах.
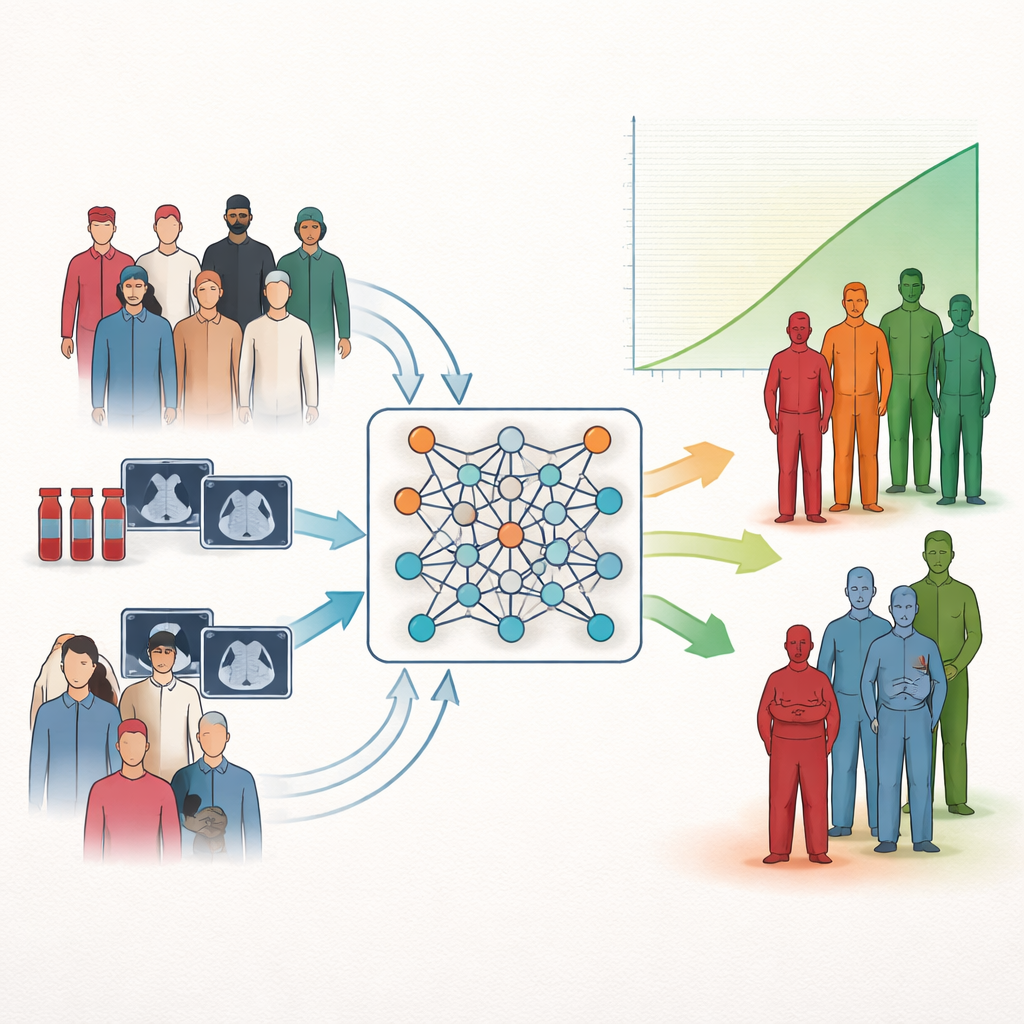
Новый способ группировать пациентов по исходу
Авторы сосредоточены на распространённой задаче в медицине: стратификации риска — распределении пациентов на группы с более благоприятным или более неблагоприятным прогнозом. Традиционные статистические методы могут оценивать, как отдельные измерения связаны с выживаемостью, но они часто не сводятся к простым категориям низкого, среднего или высокого риска, которые клиницисты могли бы использовать у постели больного. Многие современные системы ИИ добавляют мощность, но всё ещё затрудняют получение чётких, легко интерпретируемых группировок. Авторы устраняют этот разрыв, напрямую обучая нейросети формировать кластеры пациентов, максимально различающиеся по выживаемости, вместо того чтобы просто предсказывать время выживания или кластеризовать по поверхностному сходству.
Обучение под контролем данных о выживаемости
В основе метода — переработка классического статистического теста выживаемости, известного как лог‑ранк, в дифференцируемую функцию цели, которую можно оптимизировать в нейросети. Вместо того чтобы жёстко закреплять пациента за одной группой во время обучения, модель рассматривает принадлежность к группе как вероятности и изменяет их, чтобы усилить различия в выживаемости между кластерами. Балансировочный член предотвращает тривиальное решение, при котором почти все пациенты попадают в одну категорию. Поскольку этот учебный рецепт выступает только как функция потерь, его можно встроить в разные архитектуры нейросетей и для разных типов входных данных без изменения их внутреннего устройства.
Чему метод научился по анализу крови
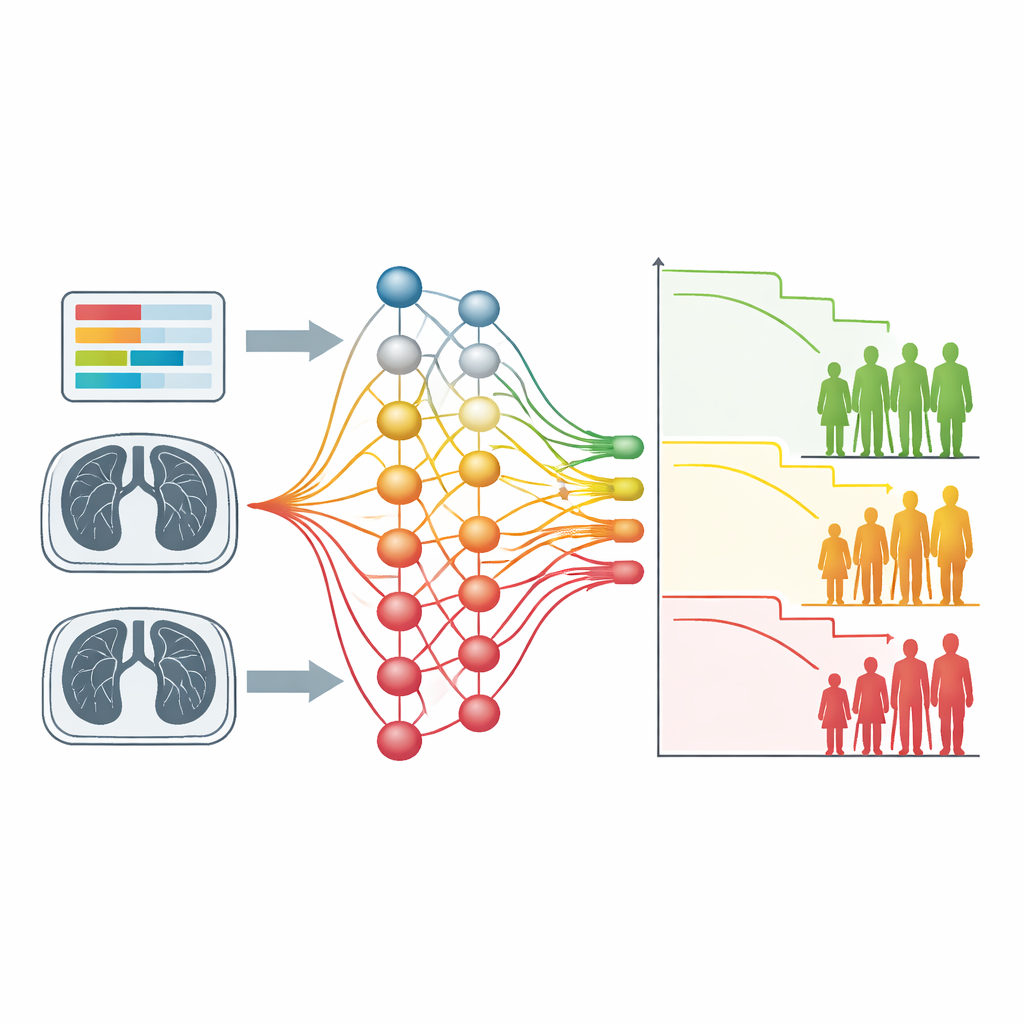
Чтобы продемонстрировать клиническую ценность, команда сначала применила подход к почти тысяче пациентов с множественной миеломой, используя только десять стандартных показателей крови, взятых около момента постановки диагноза. Сеть автоматически выделила три группы риска с чётко разнесёнными кривыми выживаемости. Худшая группа имела медиану выживания около четырёх лет, тогда как примерно семьдесят процентов лучшей группы были живы и через девять лет. При помощи инструментов объяснимости авторы выяснили, какие лабораторные показатели определяли эти группировки: хорошо известные маркеры бремени болезни и нагрузки на почки, такие как бета‑2‑микроглобулин и креатинин, тянули пациентов в сторону более высокого риска, тогда как нормальные уровни альбумина и гемоглобина смещали их в сторону низкого риска. Те же закономерности подтвердились в независимом наборе данных клинического исследования, что говорит о надёжности обнаруженных группировок.
Что метод нашёл на КТ‑снимках лёгких
Второй тестовый случай использовал грудные КТ‑снимки сотен пациентов с немелкоклеточным раком лёгкого. Здесь на входе были только изображения, без вручную обведённых опухолей или предварительно вычисленных признаков. Сверточная нейросеть, обученная с новой функцией потерь, разделила пациентов на две группы с заметно разными временами выживания, сопоставимые с более трудоёмкими радиомическими подходами. Карты визуальных объяснений показали, что модель научилась фокусироваться на областях лёгких, содержащих опухоли и их ветвящиеся, инфильтрирующие расширения, а также на соседних структурах, таких как сосуды сердца. У пациентов высокого риска эти структуры вносили сильный вклад в решения модели, что перекликается с клиническим знанием о связи инфильтративного роста и сердечной патологии с худшими исходами.
Как это может повлиять на будущее онкопомощи
В целом исследование демонстрирует, что кластеризация, ориентированная на выживаемость, может автоматически восстанавливать известные факторы риска как из простых анализов крови, так и из сложных снимков, и делать это без ручной разметки или заранее заданных правил. Поскольку тот же учебный рецепт работает для разных типов рака и данных, он предлагает гибкую отправную точку для поиска новых прогностических паттернов, в том числе в областях, таких как профили активности генов или данные о переменном во времени лечении. Для пациентов отдалённая перспектива — более ясные категории риска, выведенные непосредственно из их собственных данных, которые помогут клиницистам подобрать интенсивность и тип терапии в соответствии с уровнем риска, а для исследователей — инструмент для обнаружения новых сигналов, связанных с исходом.
Цитирование: Ferle, M., Ader, J., Wiemers, T. et al. Unsupervised risk factor identification across cancer types and data modalities via explainable artificial intelligence. npj Digit. Med. 9, 363 (2026). https://doi.org/10.1038/s41746-026-02663-w
Ключевые слова: стратификация риска при раке, анализ выживаемости, ИИ для медицинской визуализации, множественная миелома, рак лёгкого