Clear Sky Science · nl
Ongecontroleerde identificatie van risicofactoren over kankertypen en datamodaliteiten via uitlegbare kunstmatige intelligentie
Waarom het vinden van verborgen risicopatronen belangrijk is
Oncologen weten dat mensen met dezelfde diagnose zeer verschillende vooruitzichten kunnen hebben. Sommigen reageren goed op behandeling en leven vele jaren, terwijl anderen dat niet doen, zelfs als hun ziekte op papier vergelijkbaar lijkt. Dit artikel presenteert een nieuwe manier om computers routinematige medische gegevens en scans te laten doorzoeken om verborgen groepen patiënten te ontdekken die vergelijkbare overlevingskansen delen. Door dit om te zetten in duidelijke risicogroepen, wil het werk meer op maat gemaakte behandelkeuzes ondersteunen zonder dat er complexe extra tests nodig zijn.
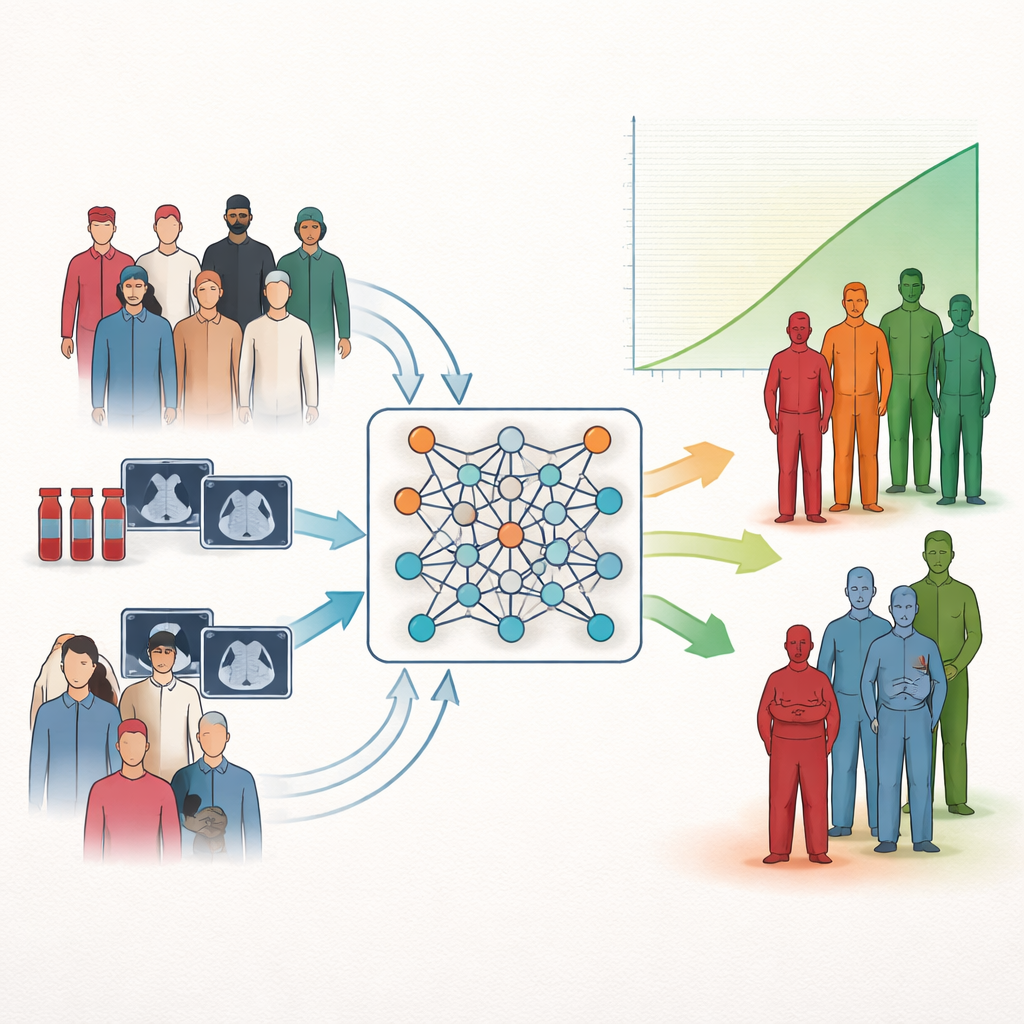
Een nieuwe manier om patiënten naar uitkomst te groeperen
De onderzoekers richten zich op een veelvoorkomende taak in de geneeskunde: risicostratificatie, oftewel het sorteren van patiënten in groepen met een betere of slechtere prognose. Traditionele statistische instrumenten kunnen inschatten hoe individuele metingen samenhangen met overleving, maar ze leiden niet altijd tot eenvoudige laag-, middelhoog- of hoogrisicocategorieën die clinici aan het bed kunnen gebruiken. Veel moderne systemen voor kunstmatige intelligentie voegen kracht toe, maar worstelen nog steeds om heldere, gemakkelijk te interpreteren groepen te leveren. De auteurs vullen deze leemte door neurale netwerken rechtstreeks te leren patiëntclusters te vormen die zoveel mogelijk van elkaar verschillen in overleving, in plaats van alleen te proberen overlevingstijd te voorspellen of patiënten te clusteren op basis van oppervlakkige gelijkenis.
Survivalgegevens het leerproces laten sturen
In de kern van de methode zit een herwerking van een klassieke survivalstatistiek, bekend als de logrank-test, naar een vloeiend doelfunctie die een neuraal netwerk kan optimaliseren. In plaats van elke patiënt tijdens training stellig in één groep te plaatsen, behandelt het model groepslidmaatschap als waarschijnlijkheden en past die aan om de overlevingsverschillen tussen clusters te verscherpen. Een balancerende term voorkomt de triviale oplossing waarbij bijna alle patiënten in dezelfde categorie terechtkomen. Omdat dit trainingsrecept slechts als verliesfunctie werkt, kan het in veel soorten neurale netwerken en veel soorten invoergegevens worden geïntegreerd zonder hun interne ontwerp te veranderen.
Wat de methode leerde uit bloedtesten
Om klinische waarde aan te tonen, paste het team hun benadering eerst toe op bijna duizend mensen met multipel myeloom, een bloedkanker, gebruikmakend van slechts tien standaardbloedmetingen rond het moment van diagnose. Hun netwerk vormde automatisch drie risicogroepen waarvan de survivalcurves duidelijk van elkaar verschilden. De slechtste groep had een mediaanoverleving van ongeveer vier jaar, terwijl ruwweg zeventig procent van de beste groep negen jaar later nog leefde. Toen de auteurs uitlegbaarheidstools toepasten om te zien welke labwaarden deze groeperingen dreven, duwden bekende markers van ziektebelasting en nierstress, zoals bèta-2-microglobuline en creatinine, patiënten richting hoger risico, terwijl gezondere niveaus van albumine en hemoglobine hen naar lager risico trokken. Dezelfde patronen deden zich voor in een onafhankelijke dataset van een klinische studie, wat suggereert dat de gevonden groeperingen robuust zijn.
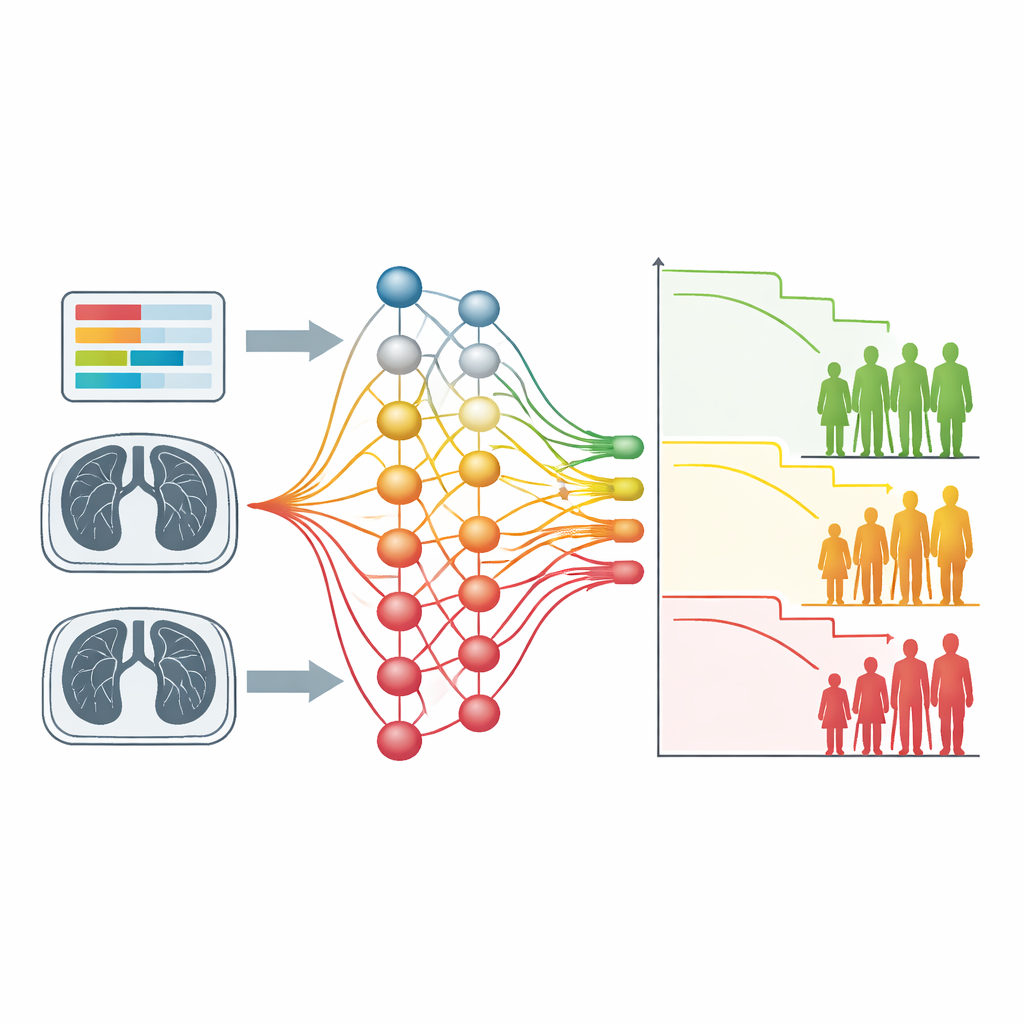
Wat de methode vond in longscans
De tweede testcase gebruikte borstkas-CT-scans van honderden mensen met niet-kleincellige longkanker. Hier was de invoer uitsluitend beeldvorming, zonder handgetekende tumorcontouren of vooraf berekende kenmerken. Een convolutioneel neuraal netwerk dat met de nieuwe verliesfunctie werd getraind splitste patiënten in twee groepen met duidelijk verschillende overlevingstijden, vergelijkbaar met meer arbeidsintensieve radiomics-benaderingen. Visuele verklaringskaarten toonden dat het model had geleerd zich te concentreren op longregio’s met tumoren en hun vertakkende, infiltreerende uitlopers, evenals nabijgelegen structuren zoals hartvaten. Bij hoogrisicopatiënten droegen deze structuren vaak sterk bij aan de beslissingen van het model, wat echoot met klinische kennis dat infiltratief groei en hartziekte samenhangen met slechtere uitkomsten.
Hoe dit de toekomstige kankerzorg zou kunnen vormen
Al met al laat de studie zien dat survival-gestuurde clustering bekende risicofactoren kan herontdekken uit zowel eenvoudige bloedtesten als complexe scans, en dat dit kan gebeuren zonder handmatige labeling of handgemaakte regels. Omdat hetzelfde trainingsrecept werkt over kankersoorten en datatypes heen, biedt het een flexibel startpunt om nieuwe prognostische patronen te verkennen, ook in gebieden zoals genexpressieprofielen of tijdsvariërende behandelgegevens. Voor patiënten is de langetermijnbelofte duidelijkere risicocategorieën die rechtstreeks uit hun eigen gegevens voortkomen en clinici helpen de intensiteit en aard van therapie af te stemmen op het risiconiveau, terwijl onderzoekers een hulpmiddel krijgen om nieuwe signalen die met uitkomst samenhangen op te sporen.
Bronvermelding: Ferle, M., Ader, J., Wiemers, T. et al. Unsupervised risk factor identification across cancer types and data modalities via explainable artificial intelligence. npj Digit. Med. 9, 363 (2026). https://doi.org/10.1038/s41746-026-02663-w
Trefwoorden: risicostratificatie bij kanker, survivalanalyse, AI voor medische beeldvorming, multipel myeloom, longkanker