Clear Sky Science · de
Unüberwachte Identifikation von Risikofaktoren über Krebsarten und Datenmodalitäten hinweg durch erklärbare künstliche Intelligenz
Warum das Finden versteckter Risikomuster wichtig ist
Krebsärzte wissen, dass Menschen mit derselben Diagnose sehr unterschiedliche Verläufe haben können. Manche sprechen gut auf Therapien an und leben viele Jahre, während andere dies nicht tun, selbst wenn ihre Erkrankung auf dem Papier ähnlich aussieht. Dieser Artikel stellt einen neuen Ansatz vor, mit dem Computer routinemäßige medizinische Daten und Scans durchsuchen können, um verborgene Patientengruppen mit ähnlichen Überlebenschancen aufzudecken. Indem dies in klare Risikogruppen übersetzt wird, soll die Arbeit gezieltere Therapieentscheidungen unterstützen, ohne komplexe Zusatztests zu erfordern.
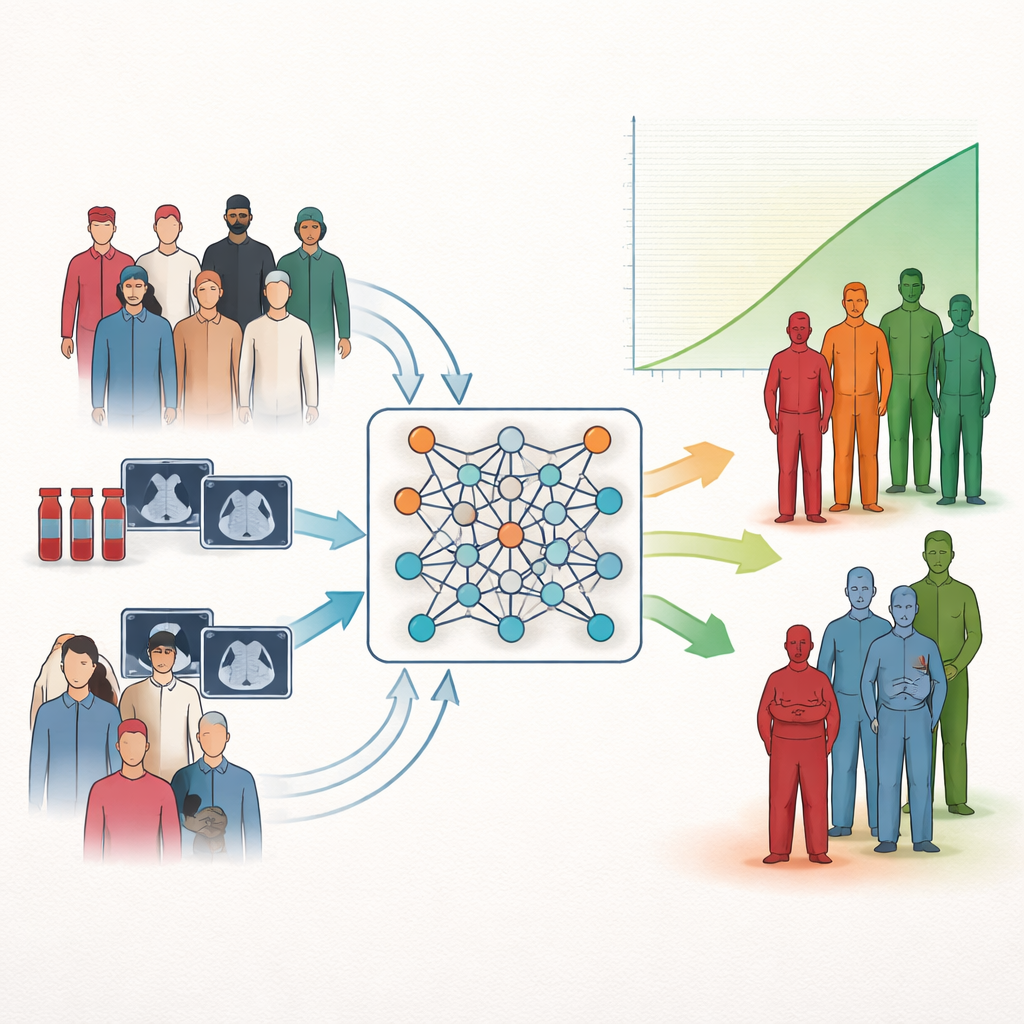
Ein neuer Weg, Patienten nach Outcome zu gruppieren
Die Forschenden konzentrieren sich auf eine häufige Aufgabe in der Medizin: die Risikostratifizierung, also das Einordnen von Patienten in Gruppen mit besserer oder schlechterer Prognose. Traditionelle statistische Werkzeuge können abschätzen, wie einzelne Messwerte mit dem Überleben zusammenhängen, aber sie lassen sich oft nicht sauber in einfache Niedrig-, Mittel- oder Hochrisiko-Kategorien übersetzen, die Kliniker am Bett nutzen können. Viele moderne KI-Systeme erhöhen die Leistung, tun sich aber weiterhin schwer, klare, leicht interpretierbare Gruppierungen zu liefern. Die Autorinnen und Autoren schließen diese Lücke, indem sie neuronalen Netzen beibringen, Patientengruppen zu bilden, die sich im Überleben möglichst stark unterscheiden, anstatt nur die Überlebenszeit vorherzusagen oder Patienten nach oberflächlicher Ähnlichkeit zu clustern.
Das Lernen durch Überlebensdaten steuern lassen
Kern der Methode ist die Umgestaltung einer klassischen Überlebensstatistik, bekannt als Logrank-Test, zu einer glatten Zielfunktion, die ein neuronales Netz optimieren kann. Anstatt jedem Patienten während des Trainings strikt eine Gruppe zuzuweisen, behandelt das Modell die Gruppenzugehörigkeit als Wahrscheinlichkeiten und passt diese so an, dass die Überlebensunterschiede zwischen den Clustern schärfer werden. Ein Ausgleichsterm verhindert die triviale Lösung, bei der nahezu alle Patienten in dieselbe Kategorie fallen. Weil dieses Trainingsrezept nur als Verlustfunktion wirkt, lässt es sich in viele Arten neuronaler Netze und in unterschiedliche Eingangsdaten einbinden, ohne deren interne Architektur zu verändern.
Was die Methode aus Bluttests lernte
Um den klinischen Nutzen zu demonstrieren, wandte das Team den Ansatz zunächst auf fast tausend Menschen mit multiplem Myelom, einer Blutkrebserkrankung, an und verwendete nur zehn standardmäßige Blutparameter, die um die Diagnose herum erhoben wurden. Das Netz bildete automatisch drei Risikogruppen, deren Überlebenskurven klar getrennt waren. Die Gruppe mit der schlechtesten Prognose hatte eine mediane Überlebenszeit von etwa vier Jahren, während rund siebzig Prozent der besten Gruppe neun Jahre später noch am Leben waren. Als die Autoren Erklärbarkeitswerkzeuge einsetzten, um zu sehen, welche Laborwerte diese Gruppierungen antrieben, zeigten bekannte Marker für Krankheitslast und Nierenbelastung, wie Beta-2-Mikroglobulin und Kreatinin, eine Verschiebung hin zu höherem Risiko, während gesündere Albumin- und Hämoglobinwerte in Richtung niedrigeres Risiko zogen. Dieselben Muster zeigten sich in einem unabhängigen klinischen Studiendatensatz, was darauf hindeutet, dass die entdeckten Gruppierungen robust sind.
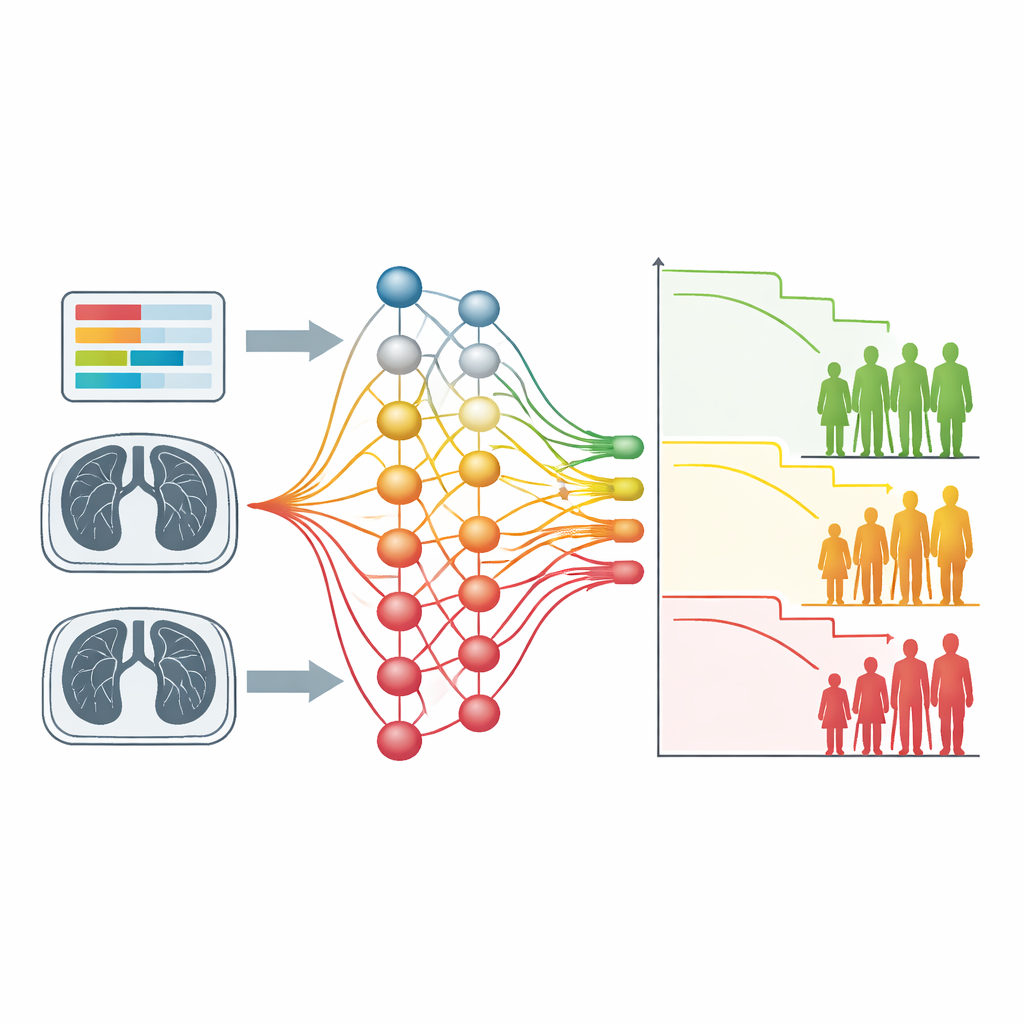
Was die Methode in Lungenaufnahmen fand
Der zweite Anwendungsfall nutzte Thorax-CTs von Hunderten von Personen mit nicht-kleinzelligem Lungenkrebs. Hier bestand der Input ausschließlich aus Bildern, ohne handgezeichnete Tumorumrisse oder vorab berechnete Merkmale. Ein mit der neuen Verlustfunktion trainiertes konvolutionales neuronales Netz teilte die Patienten in zwei Gruppen mit deutlich unterschiedlichen Überlebenszeiten, ähnlich wie aufwändigere Radiomics-Ansätze. Visuelle Erklärungs-Maps zeigten, dass das Modell gelernt hatte, sich auf Lungenregionen mit Tumoren und deren verzweigende, infiltrative Ausläufer sowie auf benachbarte Strukturen wie Herzgefäße zu konzentrieren. Bei Hochrisikopatienten trugen diese Strukturen stärker zu den Modellentscheidungen bei, was klinisches Wissen widerspiegelt, dass infiltratives Wachstum und Herzerkrankungen mit schlechteren Outcomes verknüpft sind.
Wie das die zukünftige Krebsversorgung prägen könnte
Insgesamt zeigt die Studie, dass überlebensgesteuertes Clustering bekannte Risikofaktoren sowohl aus einfachen Bluttests als auch aus komplexen Scans wiederentdecken kann — und zwar ohne manuelle Beschriftung oder handgefertigte Regeln. Da dasselbe Trainingsrezept über Krebsarten und Datentypen hinweg funktioniert, bietet es einen flexiblen Ausgangspunkt, um neue prognostische Muster zu erkunden, etwa in Bereichen wie Genaktivitätsprofilen oder zeitveränderlichen Behandlungsdaten. Für Patientinnen und Patienten liegt das langfristige Versprechen in klareren Risikokategorien, die direkt aus ihren eigenen Daten entstehen und Kliniker dabei unterstützen, Intensität und Art der Therapie an das Risiko anzupassen, während Forschende ein Werkzeug erhalten, um neue mit dem Outcome verknüpfte Signale aufzuspüren.
Zitation: Ferle, M., Ader, J., Wiemers, T. et al. Unsupervised risk factor identification across cancer types and data modalities via explainable artificial intelligence. npj Digit. Med. 9, 363 (2026). https://doi.org/10.1038/s41746-026-02663-w
Schlüsselwörter: Krebs-Risikostratifizierung, Überlebensanalyse, medizinische Bildgebungs-KI, Multiples Myelom, Lungenkrebs