Clear Sky Science · it
Identificazione non supervisionata dei fattori di rischio attraverso tipi di cancro e modalità di dati tramite intelligenza artificiale spiegabile
Perché è importante individuare pattern di rischio nascosti
I medici oncologi sanno che persone con la stessa diagnosi possono avere futuri molto diversi. Alcuni rispondono bene alle terapie e vivono molti anni, mentre altri no, anche quando la malattia sembra simile sulla carta. Questo articolo presenta un nuovo modo per far sì che i computer esplorino dati medici di routine e scansioni per scoprire gruppi nascosti di pazienti che condividono probabilità di sopravvivenza simili. Trasformando queste scoperte in categorie di rischio chiare, il lavoro punta a supportare decisioni terapeutiche più mirate senza richiedere esami aggiuntivi complessi.
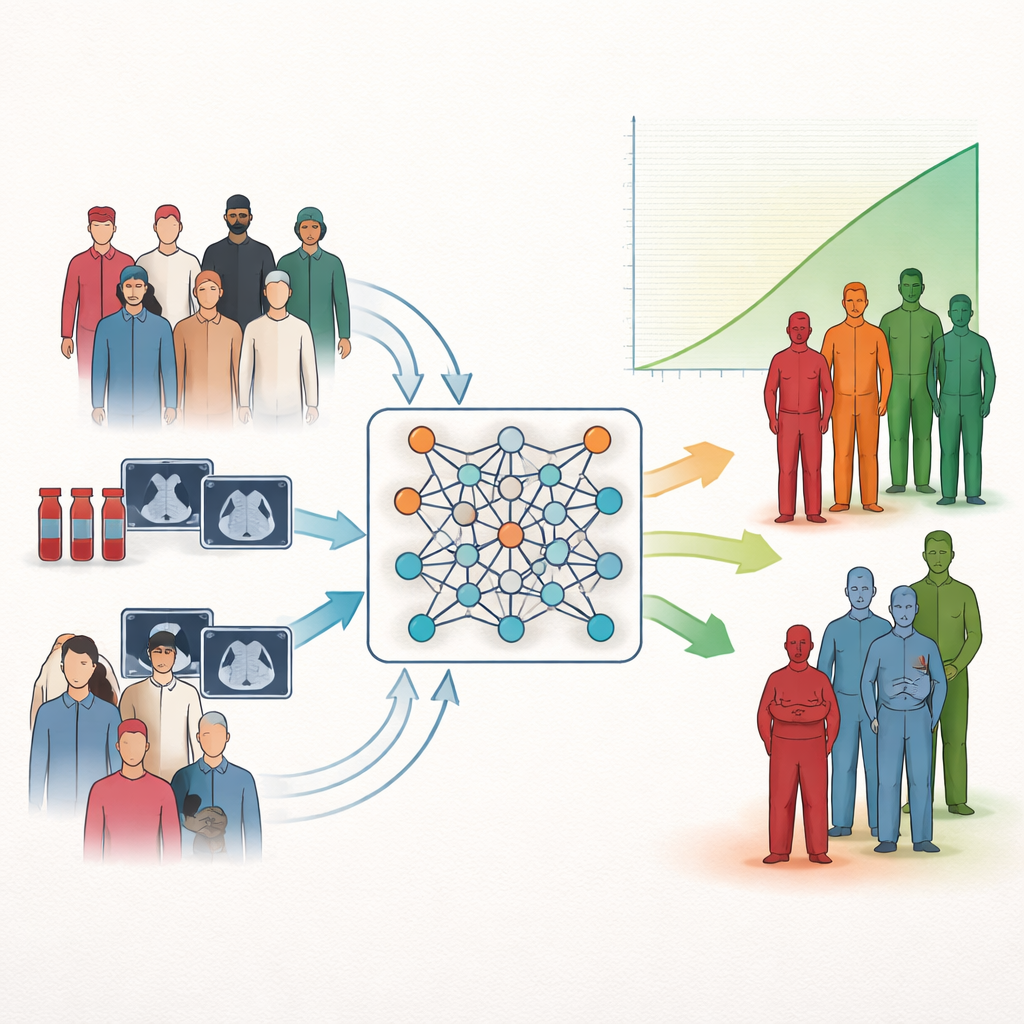
Un nuovo modo di raggruppare i pazienti per esito
I ricercatori si concentrano su un compito comune in medicina: la stratificazione del rischio, cioè l’ordinamento dei pazienti in gruppi con prognosi migliore o peggiore. Gli strumenti statistici tradizionali possono stimare come singole misure siano correlate alla sopravvivenza, ma spesso non si traducono facilmente in categorie semplici — basso, medio o alto rischio — utilizzabili a letto del paziente. Molti sistemi di intelligenza artificiale moderni aggiungono potenza ma faticano ancora a fornire raggruppamenti chiari e facilmente interpretabili. Gli autori colmano questa lacuna insegnando direttamente alle reti neurali a formare cluster di pazienti che differiscono il più possibile in termini di sopravvivenza, invece di limitarsi a prevedere il tempo di sopravvivenza o a raggruppare i pazienti per somiglianza superficiale.
Lasciare che i dati di sopravvivenza guidino l’apprendimento
Al centro del metodo c’è una rielaborazione di una statistica classica di sopravvivenza, nota come test log-rank, in un obiettivo continuo che una rete neurale può ottimizzare. Anziché assegnare ogni paziente in modo rigido a un gruppo durante l’addestramento, il modello tratta l’appartenenza ai gruppi come probabilità e le aggiusta per accentuare le differenze di sopravvivenza tra i cluster. Un termine di bilanciamento evita la soluzione banale in cui quasi tutti i pazienti finiscono nella stessa categoria. Poiché questa ricetta di addestramento agisce solo come funzione di perdita, può essere integrata in molti tipi di reti neurali e con molte tipologie di dati in ingresso senza cambiare la loro struttura interna.
Cosa ha imparato il metodo dagli esami del sangue
Per dimostrare il valore clinico, il team ha prima applicato l’approccio a quasi mille persone con mieloma multiplo, un tumore del sangue, usando solo dieci misure ematiche standard prelevate attorno alla diagnosi. La rete ha formato automaticamente tre gruppi di rischio con curve di sopravvivenza chiaramente separate. Il gruppo peggiore aveva una sopravvivenza mediana di circa quattro anni, mentre circa il settanta percento del gruppo migliore era ancora vivo nove anni dopo. Quando gli autori hanno impiegato strumenti di spiegabilità per capire quali valori di laboratorio guidavano questi raggruppamenti, marcatori noti di carico di malattia e compromissione renale, come la beta-2-microglobulina e la creatinina, spingevano i pazienti verso un rischio più alto, mentre livelli più sani di albumina ed emoglobina li avvicinavano al rischio più basso. Gli stessi schemi si sono osservati in un dataset di uno studio clinico indipendente, suggerendo che i raggruppamenti scoperti sono robusti.
Cosa ha trovato il metodo nelle TAC del torace
Il secondo caso di test ha usato TAC toraciche di centinaia di persone con carcinoma polmonare non a piccole cellule. Qui l’input era solo l’imaging, senza contorni del tumore tracciati a mano né caratteristiche precalcolate. Una rete neurale convoluzionale addestrata con la nuova funzione di perdita ha diviso i pazienti in due gruppi con tempi di sopravvivenza chiaramente diversi, in modo simile ad approcci radiomici più laboriosi. Mappe di spiegazione visuali hanno rivelato che il modello aveva imparato a concentrarsi su regioni polmonari contenenti tumori e sulle loro estensioni ramificate e infiltrative, oltre a strutture vicine come i vasi cardiaci. Nei pazienti ad alto rischio queste strutture tendevano a contribuire in modo marcato alle decisioni del modello, richiamando la conoscenza clinica che la crescita infiltrativa e le malattie cardiache sono legate a esiti peggiori.
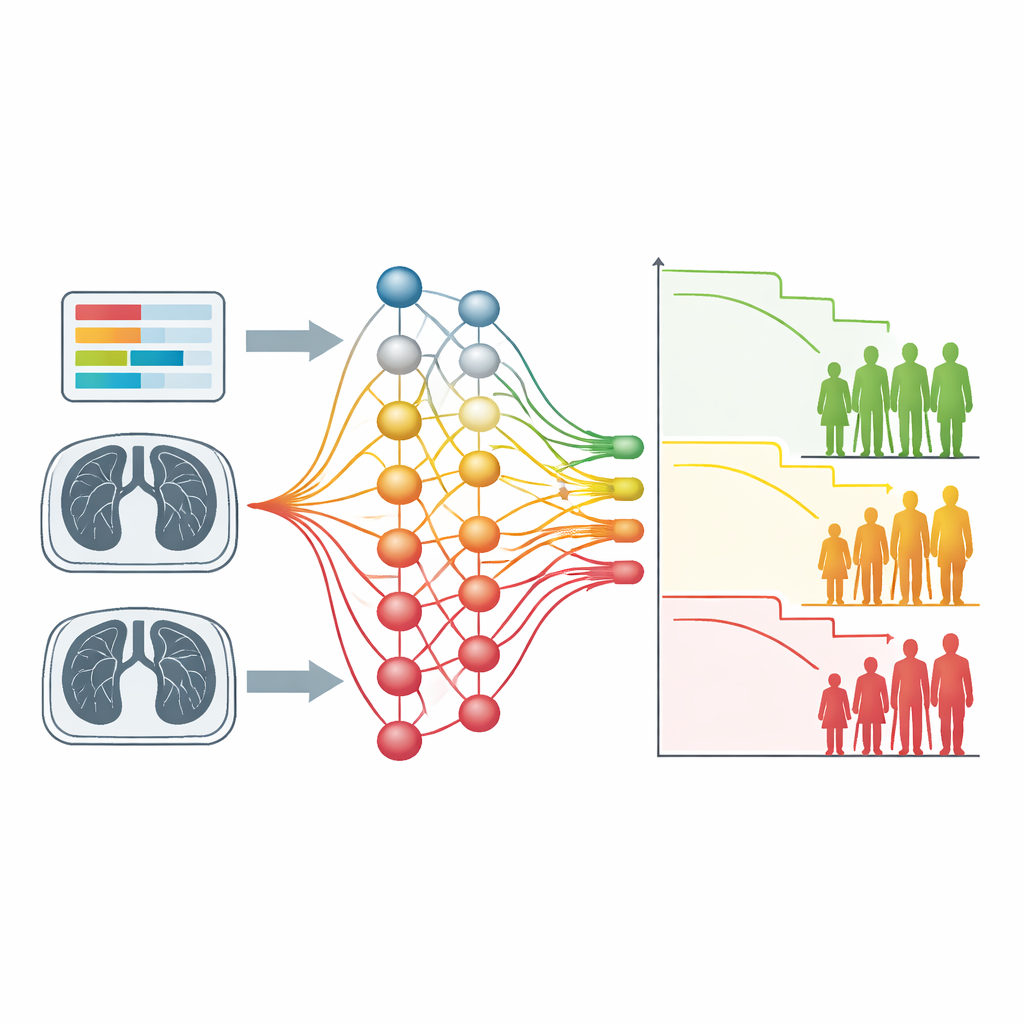
Come questo potrebbe modellare la cura del cancro in futuro
Nel complesso, lo studio dimostra che il clustering guidato dalla sopravvivenza può riscoprire fattori di rischio noti sia da semplici esami del sangue sia da scansioni complesse, e può farlo senza etichettatura manuale o regole costruite a mano. Poiché la stessa ricetta di addestramento funziona attraverso tipi diversi di cancro e di dati, offre un punto di partenza flessibile per esplorare nuovi pattern prognostici, inclusi ambiti come i profili di attività genica o i dati di trattamento che variano nel tempo. Per i pazienti, la promessa a lungo termine è di categorie di rischio più chiare che emergono direttamente dai propri dati e che aiutano i clinici ad adeguare intensità e stile della terapia al livello di rischio, mentre i ricercatori ottengono uno strumento per individuare nuovi segnali collegati all’esito.
Citazione: Ferle, M., Ader, J., Wiemers, T. et al. Unsupervised risk factor identification across cancer types and data modalities via explainable artificial intelligence. npj Digit. Med. 9, 363 (2026). https://doi.org/10.1038/s41746-026-02663-w
Parole chiave: stratificazione del rischio nel cancro, analisi di sopravvivenza, IA per immagini mediche, mieloma multiplo, cancro al polmone