Clear Sky Science · sv
Skalmedveten tät dynamisk SLAM för monokulära, stereoskopiska och RGB-D-kameror
Smartare digitala kartor för rörliga, föränderliga världar
Robotar, drönare och augmented reality-headset behöver alla en detaljerad uppfattning om sin omgivning för att röra sig säkert och smidigt. Ändå halkar de flesta kartläggningssystem när människor går förbi, bilar kör förbi eller möbler flyttas. Denna artikel presenterar SDMFusion, en ny kartläggningsmetod som kan bygga rika, korrekta 3D-kartor i realtid, även när världen runt kameran är full av rörelse, och som fungerar med flera vanliga kamertyper.
Varför traditionella visionssystem inte räcker till
Många robotar förlitar sig på visuell SLAM, en teknik som låter en kamera avgöra var den befinner sig samtidigt som den bygger en karta. Klassiska system antar att världen till största delen är stilla och producerar ofta bara glesa kartor bestående av ett fåtal spårade punkter. De har också problem när de använder en enda kamera, eftersom de inte kan avgöra hur stor scenen faktiskt är: en liten leksak nära linsen ser ut som ett stort föremål långt bort. Rörliga människor och objekt förvirrar dessa metoder, vilket gör att den uppskattade kamerabanan glider och kartan blir opålitlig. Dessa svagheter begränsar användningen av lågkostnadskameror i verkliga hem, gator och arbetsplatser.
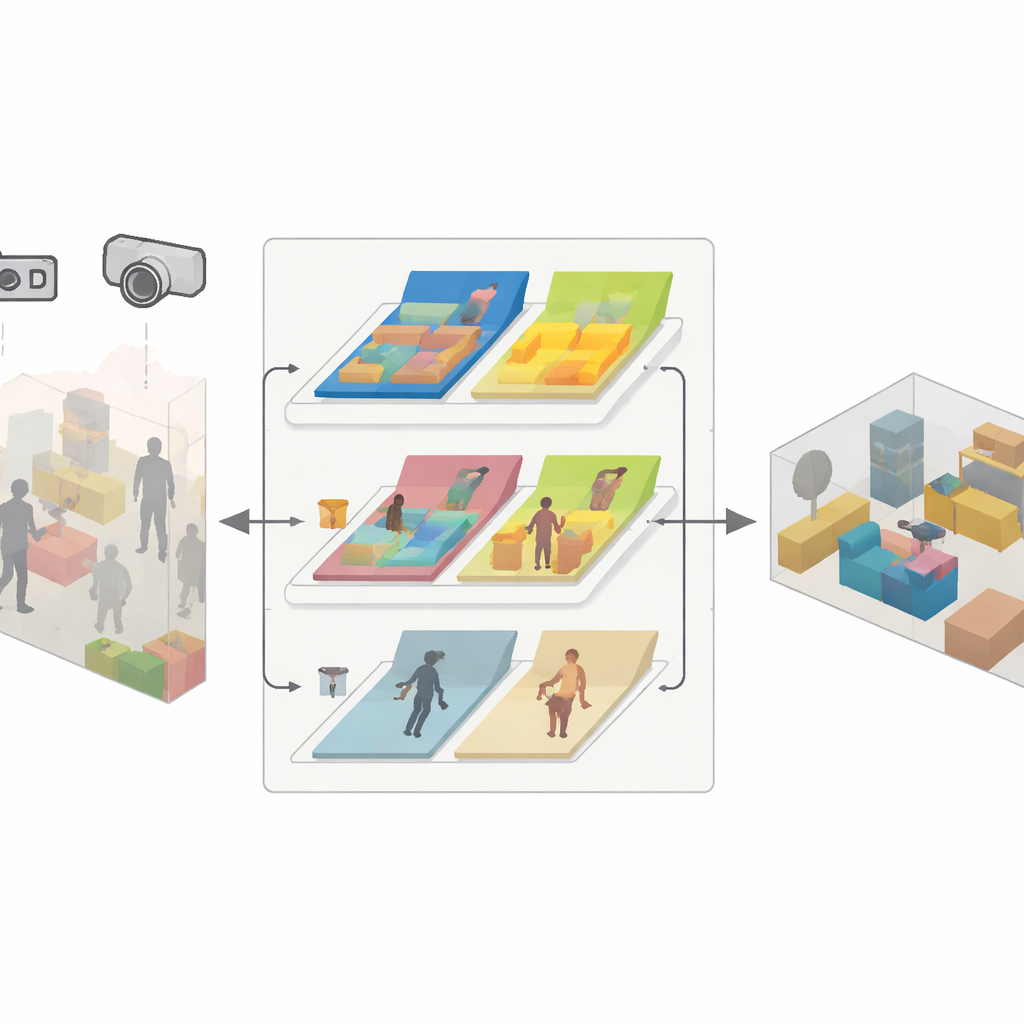
En tredelad motor för pålitlig kartläggning
SDMFusion är byggt ovanpå det populära ORB-SLAM3-systemet men lägger till tre tätt sammankopplade moduler för att övervinna dessa hinder. För det första matar en skala–djup-modul varje bild till ett kraftfullt neuralt nätverk kallat DepthAnythingV2, som uppskattar avståndet till varje pixel. För en enskild kamera ger denna prediktion den saknade verkliga skalan; för stereo- och RGB-D-kameror används den för att jämna ut och fylla luckor i deras råa djupmätningar. För det andra letar en dynamisk–funktionsmodul efter objekt som kan röra sig, med hjälp av ett snabbt segmenteringsnät inspirerat av den senaste YOLO-familjen. Den grupperar saker som människor, bilar och även potentiellt flyttbara föremål som stolar, och kontrollerar sedan, funktion för funktion, om de verkligen rör sig mellan bildrutorna med geometriska konsistenskontroller. Endast funktioner som verkligen tillhör rörliga delar kasseras, medan stabila bevaras för att stödja exakt positionering. För det tredje tar en anti-dynamisk rekonstruktionsmodul de förfinade djupen, pålitliga kamerapositionerna och maskerna för statiska pixlar för att slå samman endast de orörliga delarna till en tät 3D-karta.
Hur metoden presterar i praktiken
Författarna utsatte SDMFusion för omfattande tester på tre välkända publika dataset och på scener de själva spelade in med en liten drönare. De valda datasetten täcker utomhus körning, röriga inomhusrum och mycket dynamiska situationer med människor som går, sitter eller lyfter lådor, fångade med monokulära, stereoskopiska och RGB-D-kameror. De jämförde SDMFusion med flera avancerade system, inklusive ORB-SLAM3, DS-SLAM, DynaSLAM och RDS-SLAM, med hjälp av standardmått för hur nära den uppskattade kamerabanan ligger den faktiska banan. I de flesta sekvenser uppnådde SDMFusion lägre fel och högre framgångsfrekvenser, särskilt i de svåraste dynamiska scenerna och för enkla kamerauppsättningar där skala är svårast att uppskatta. Visuellt är dess täta kartor mer kompletta och fria från de ”spöken” och utsmetade former som uppstår när rörliga människor felaktigt smälts in i den statiska omgivningen.

Styrkor, begränsningar och framtida riktningar
Resultaten visar att kombinationen av stark djupprediktion, noggrann hantering av dynamiska objekt och selektiv rekonstruktion ger kartor som både är detaljerade och trovärdiga. SDMFusion körs i realtid på ett kraftfullt grafikkort för stationära datorer, och även om det är långsammare på inbyggd hårdvara visar författarna stora hastighetsvinster genom att optimera djupnätverket med TensorRT. De undersöker även modulernas betydelse genom ablationstudier och bekräftar att skalåterställning, segmentering och rörelsekontroller alla bidrar märkbart till noggrannhet och robusthet. Systemet kan dock fortfarande misslyckas när nästan hela bilden täcks av ett enda rörligt objekt, vilket lämnar för få klart statiska områden att binda mot, och monokulär prestanda hänger fortfarande efter stereo och RGB-D i mycket komplexa scener.
Vad detta betyder för vardagsrobotar
För en icke-expert är huvudbudskapet att SDMFusion för kamerabaserad kartläggning närmare hur vi vill att robotar och AR-enheter ska bete sig i verkliga världen: det bygger täta, skalade 3D-modeller, ignorerar människor och andra rörliga objekt när det är lämpligt, och håller reda på sin egen position med hög tillförlitlighet. Även om det finns utrymme för förbättringar på små enheter och i extremt trånga miljöer visar detta arbete en tydlig väg mot prisvärda maskiner som kan navigera i livliga hem, kontor och gator med endast lättviktiga kameror.
Citering: Cen, N., Xu, Y., Wong, TW. et al. Scale aware dense dynamic SLAM for monocular, stereo and RGBD cameras. Sci Rep 16, 10285 (2026). https://doi.org/10.1038/s41598-026-41208-9
Nyckelord: visuell SLAM, 3D-kartläggning, robotnavigation, dynamiska miljöer, djupuppskattning