Clear Sky Science · es
SLAM dinámico denso consciente de la escala para cámaras monoculares, estéreo y RGBD
Mapas digitales más inteligentes para mundos en movimiento y cambio
Robots, drones y visores de realidad aumentada necesitan una comprensión detallada de su entorno para moverse con seguridad y fluidez. Sin embargo, la mayoría de los sistemas de mapeo fallan cuando pasan personas, circulan coches o se mueve el mobiliario. Este artículo presenta SDMFusion, un nuevo enfoque de mapeo capaz de construir mapas 3D ricos y precisos en tiempo real, incluso cuando el entorno alrededor de la cámara está lleno de movimiento, y que funciona con varios tipos comunes de cámaras.
Por qué los sistemas de visión tradicionales se quedan cortos
Muchos robots dependen del SLAM visual, una técnica que permite a una cámara determinar su posición mientras construye un mapa simultáneamente. Los sistemas clásicos asumen que el mundo está mayormente en reposo y con frecuencia producen mapas dispersos compuestos por unos pocos puntos rastreados. También tienen dificultades cuando usan una cámara única, porque no pueden determinar el tamaño real de la escena: un juguete pequeño cerca del objetivo puede parecer un objeto grande y lejano. Las personas y objetos en movimiento confunden estos métodos, provocando que la trayectoria estimada de la cámara derive y que el mapa se vuelva poco fiable. Estas limitaciones restringen el uso de cámaras económicas en hogares, calles y lugares de trabajo reales.
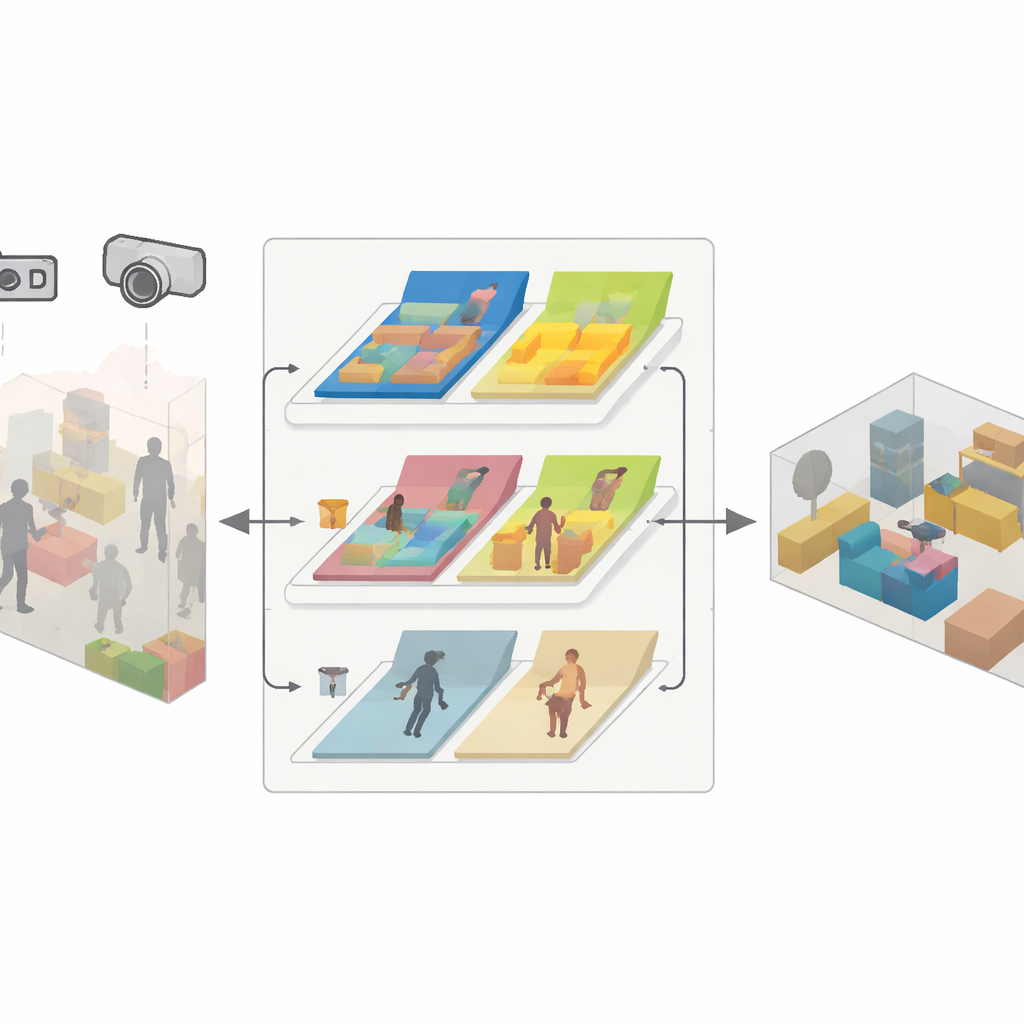
Un motor en tres partes para un mapeo fiable
SDMFusion se basa en el popular sistema ORB-SLAM3 pero añade tres módulos estrechamente vinculados para superar estos obstáculos. Primero, un módulo de escala–profundidad procesa cada imagen con una potente red neuronal llamada DepthAnythingV2, que estima la distancia a cada píxel. En cámaras monoculares, esta predicción aporta la escala real que falta; en cámaras estéreo y RGB-D, se usa para suavizar y rellenar huecos en sus lecturas de profundidad cruda. Segundo, un módulo de características dinámicas detecta objetos que podrían moverse, utilizando una red de segmentación rápida inspirada en la familia YOLO más reciente. Agrupa elementos como personas, coches e incluso objetos potencialmente movibles como sillas, y luego comprueba, característica por característica, si realmente se mueven entre fotogramas mediante pruebas de consistencia geométrica. Solo se descartan las características que pertenecen verdaderamente a partes móviles, mientras que las estables se mantienen para apoyar un seguimiento preciso. Tercero, un módulo de reconstrucción anti-dinámica toma las profundidades refinadas, las poses de cámara fiables y las máscaras de píxeles estáticos para fusionar únicamente las partes inmóviles en un mapa 3D denso.
Cómo rinde el método en la práctica
Los autores sometieron a SDMFusion a pruebas extensas en tres conjuntos de datos públicos conocidos y en escenas que ellos mismos grabaron con un pequeño dron. Los conjuntos elegidos cubren conducción exterior, habitaciones interiores desordenadas y situaciones altamente dinámicas con personas caminando, sentándose o levantando cajas, captadas por cámaras monoculares, estéreo y RGB-D. Compararon SDMFusion con varios sistemas avanzados, incluidos ORB-SLAM3, DS-SLAM, DynaSLAM y RDS-SLAM, usando medidas estándar de cuánto se aproxima la trayectoria estimada de la cámara a la verdad de referencia. En la mayoría de las secuencias, SDMFusion logró errores más bajos y tasas de éxito más altas, especialmente en las escenas dinámicas más difíciles y en configuraciones monoculares donde la estimación de escala es más desafiante. Visualmente, sus mapas densos son más completos y están libres de los “fantasmas” y las formas difusas que aparecen cuando personas en movimiento se fusionan por error en el entorno estático.

Fortalezas, límites y direcciones futuras
Los resultados muestran que combinar una fuerte predicción de profundidad, un tratamiento cuidadoso de los objetos dinámicos y una reconstrucción selectiva produce mapas detallados y confiables. SDMFusion funciona en tiempo real en una tarjeta gráfica de escritorio potente y, aunque va más lento en hardware embebido, los autores demuestran grandes ganancias de velocidad al optimizar la red de profundidad con TensorRT. También analizan la importancia de cada módulo mediante estudios de ablación, confirmando que la recuperación de escala, la segmentación y las comprobaciones de movimiento contribuyen de forma notable a la precisión y la robustez. Aun así, el sistema puede fallar cuando casi toda la vista está ocupada por un único objeto en movimiento, quedando pocas regiones claramente estáticas a las que agarrarse, y el rendimiento monocular sigue quedando por detrás del estéreo y el RGB-D en escenas muy complejas.
Qué significa esto para los robots cotidianos
Para un observador no experto, la conclusión principal es que SDMFusion acerca el mapeo basado en cámara a cómo quisiéramos que se comportaran robots y dispositivos de RA en el mundo real: construye modelos 3D densos y escalados, ignora a las personas y otros elementos móviles cuando procede, y mantiene un seguimiento de su propia posición con alta fiabilidad. Si bien queda margen de mejora en dispositivos pequeños y en escenas extremadamente concurridas, este trabajo muestra un camino claro hacia máquinas asequibles que puedan navegar por hogares, oficinas y calles concurridas usando solo cámaras ligeras.
Cita: Cen, N., Xu, Y., Wong, TW. et al. Scale aware dense dynamic SLAM for monocular, stereo and RGBD cameras. Sci Rep 16, 10285 (2026). https://doi.org/10.1038/s41598-026-41208-9
Palabras clave: SLAM visual, mapa 3D, navegación robótica, entornos dinámicos, estimación de profundidad