Clear Sky Science · it
SLAM dinamico denso consapevole della scala per camere monoculari, stereo e RGBD
Mappe digitali più intelligenti per mondi in movimento e in cambiamento
Robot, droni e visori per realtà aumentata necessitano tutti di una comprensione dettagliata dell’ambiente per muoversi in modo sicuro e fluido. Tuttavia la maggior parte dei sistemi di mappatura vacilla quando passano persone, sfrecciano auto o vengono spostati mobili. Questo articolo presenta SDMFusion, un nuovo approccio di mappatura che può costruire mappe 3D ricche e accurate in tempo reale, anche quando il mondo intorno alla camera è pieno di movimento, e funziona con diversi tipi comuni di sensori.
Perché i sistemi di visione tradizionali non bastano
Molti robot si basano sul visual SLAM, una tecnica che consente a una camera di stimare la propria posizione mentre costruisce una mappa contemporaneamente. I sistemi classici assumono che il mondo sia per lo più statico e spesso producono mappe sparse composte da pochi punti tracciati. Faticano anche quando si usa una sola camera, perché non riescono a determinare la scala reale della scena: un piccolo giocattolo vicino all’obiettivo può sembrare un grande oggetto distante. Persone e oggetti in movimento confondono questi metodi, causando deriva nella traiettoria stimata della camera e rendendo la mappa inaffidabile. Queste debolezze limitano l’uso di camere a basso costo nelle case, nelle strade e nei luoghi di lavoro reali.
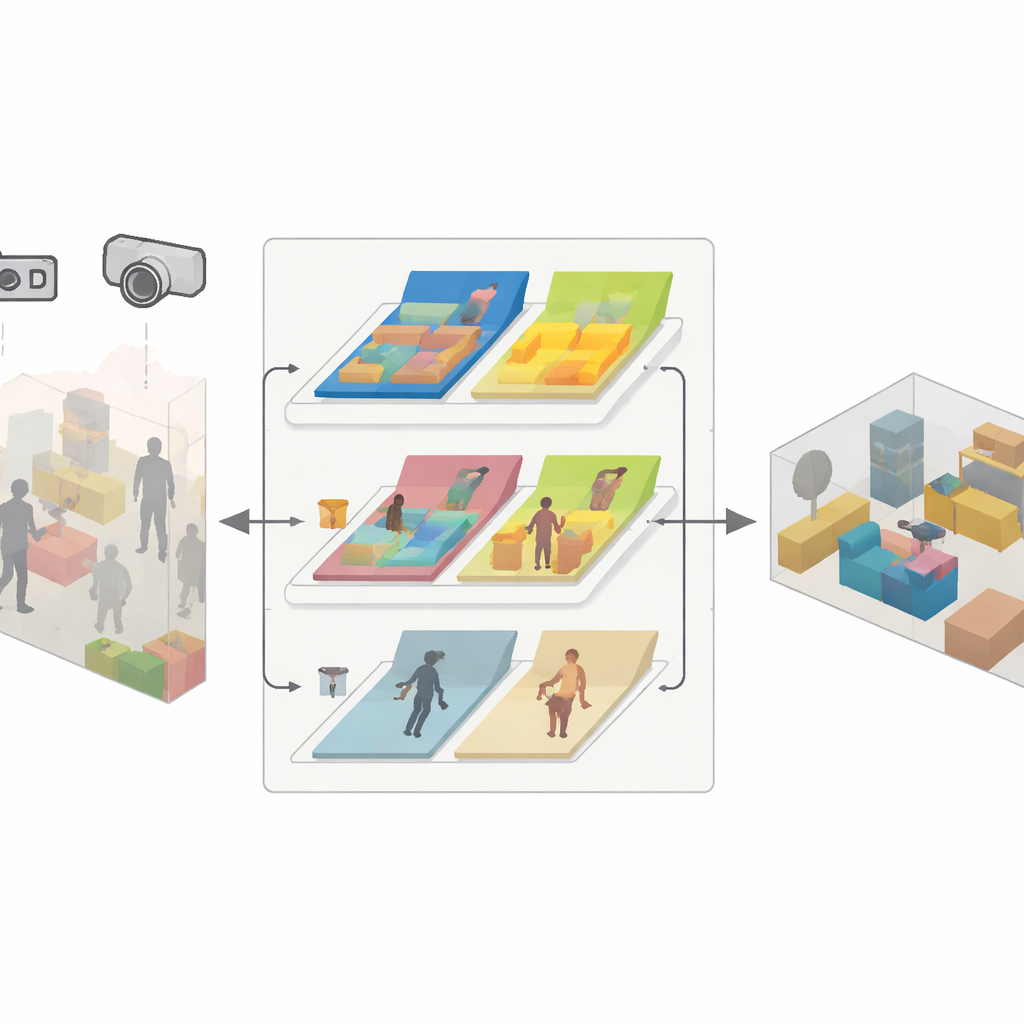
Un motore in tre parti per una mappatura affidabile
SDMFusion è costruito sopra il popolare sistema ORB-SLAM3 ma aggiunge tre moduli strettamente collegati per superare questi ostacoli. Primo, un modulo scala–profondità passa ogni immagine a una rete neurale potente chiamata DepthAnythingV2, che stima la distanza per ogni pixel. Per una camera singola questa predizione fornisce la scala reale mancante; per sistemi stereo e RGB-D, viene usata per lisciare e riempire i vuoti nelle loro letture di profondità grezze. Secondo, un modulo di feature dinamiche individua oggetti che potrebbero muoversi, utilizzando una rete di segmentazione veloce ispirata alle ultime famiglie YOLO. Raggruppa elementi come persone, automobili e anche oggetti potenzialmente spostabili come sedie, quindi controlla, feature dopo feature, se si muovono effettivamente tra i fotogrammi mediante test di consistenza geometrica. Vengono scartate solo le feature che appartengono realmente a parti in movimento, mentre quelle stabili vengono mantenute per supportare il tracciamento preciso. Terzo, un modulo di ricostruzione anti-dinamica prende le profondità affinate, le pose di camera affidabili e le maschere dei pixel statici per fondere soltanto le parti immobili in una mappa 3D densa.
Come si comporta il metodo nella pratica
Gli autori hanno sottoposto SDMFusion a test estensivi su tre dataset pubblici noti e su scene registrate da loro con un piccolo drone. I dataset scelti coprono guida esterna, stanze interne ingombre e situazioni altamente dinamiche con persone che camminano, si siedono o sollevano scatole, catturate da camere monoculari, stereo e RGB-D. Hanno confrontato SDMFusion con diversi sistemi avanzati, tra cui ORB-SLAM3, DS-SLAM, DynaSLAM e RDS-SLAM, usando misure standard di quanto la traiettoria stimata della camera corrisponda al ground truth. Nella maggior parte delle sequenze SDMFusion ha ottenuto errori inferiori e tassi di successo più alti, soprattutto nelle scene dinamiche più difficili e nei set-up con una sola camera, dove la stima della scala è più impegnativa. Visivamente, le sue mappe dense sono più complete e prive dei “fantasmi” e delle forme sfocate che compaiono quando persone in movimento vengono erroneamente fuse nell’ambiente statico.

Pregi, limiti e direzioni future
I risultati mostrano che combinare una forte predizione di profondità, un trattamento accurato degli oggetti dinamici e una ricostruzione selettiva produce mappe dettagliate e attendibili. SDMFusion funziona in tempo reale su una potente GPU da desktop e, sebbene sia più lento su hardware embedded, gli autori dimostrano grandi guadagni di velocità ottimizzando la rete di profondità con TensorRT. Indagano inoltre l’importanza di ciascun modulo tramite studi di ablazione, confermando che recupero della scala, segmentazione e controlli di movimento contribuiscono in modo apprezzabile alla precisione e alla robustezza. Rimane però il rischio di fallimento quando quasi tutta la vista è occupata da un singolo oggetto in movimento, lasciando troppo poche regioni chiaramente statiche a cui aggrapparsi, e le prestazioni monoculari sono ancora inferiori rispetto a stereo e RGB-D in scene molto complesse.
Cosa significa per i robot di tutti i giorni
Per un osservatore non esperto, il messaggio chiave è che SDMFusion avvicina la mappatura basata su camera al comportamento desiderabile di robot e dispositivi AR nel mondo reale: costruisce modelli 3D densi e scalati, ignora persone e altri elementi in movimento quando appropriato e mantiene un preciso tracciamento della propria posizione. Pur lasciando margine di miglioramento sui dispositivi piccoli e in scene estremamente affollate, questo lavoro indica una strada concreta verso macchine accessibili che possono navigare in case, uffici e strade affollate usando soltanto camere leggere.
Citazione: Cen, N., Xu, Y., Wong, TW. et al. Scale aware dense dynamic SLAM for monocular, stereo and RGBD cameras. Sci Rep 16, 10285 (2026). https://doi.org/10.1038/s41598-026-41208-9
Parole chiave: visual SLAM, mappatura 3D, navigazione robotica, ambienti dinamici, stima della profondità