Clear Sky Science · de
Skalaware dichte dynamische SLAM für Monokular-, Stereo- und RGBD-Kameras
Intelligentere digitale Karten für bewegte, veränderliche Welten
Roboter, Drohnen und Augmented-Reality-Headsets benötigen ein detailliertes Verständnis ihrer Umgebung, um sich sicher und geschmeidig zu bewegen. Die meisten Kartierungssysteme geraten jedoch ins Straucheln, wenn Menschen vorbeigehen, Autos durchfahren oder Möbel verrückt werden. Dieses Papier stellt SDMFusion vor — einen neuen Kartierungsansatz, der in Echtzeit reichhaltige, genaue 3D-Karten erstellen kann, selbst wenn die Welt vor der Kamera voller Bewegung ist, und der mit mehreren gängigen Kameratypen funktioniert.
Warum traditionelle Bildverarbeitungssysteme nicht ausreichen
Viele Roboter verlassen sich auf visuellen SLAM, eine Technik, mit der eine Kamera gleichzeitig ihre eigene Position bestimmt und eine Karte aufbaut. Klassische Systeme setzen voraus, dass die Welt überwiegend statisch ist, und liefern oft nur spärliche Karten aus wenigen verfolgten Punkten. Sie haben außerdem Schwierigkeiten mit einer einzelnen Kamera, weil diese die tatsächliche Größe der Szene nicht erkennen kann: Ein kleines Spielzeug nahe der Linse erscheint wie ein großes Objekt weit entfernt. Bewegte Personen und Objekte verwirren diese Methoden, führen zu Drift in der geschätzten Kameraposition und machen die Karte unzuverlässig. Diese Schwächen beschränken den Einsatz kostengünstiger Kameras in echten Wohnungen, auf Straßen und an Arbeitsplätzen.
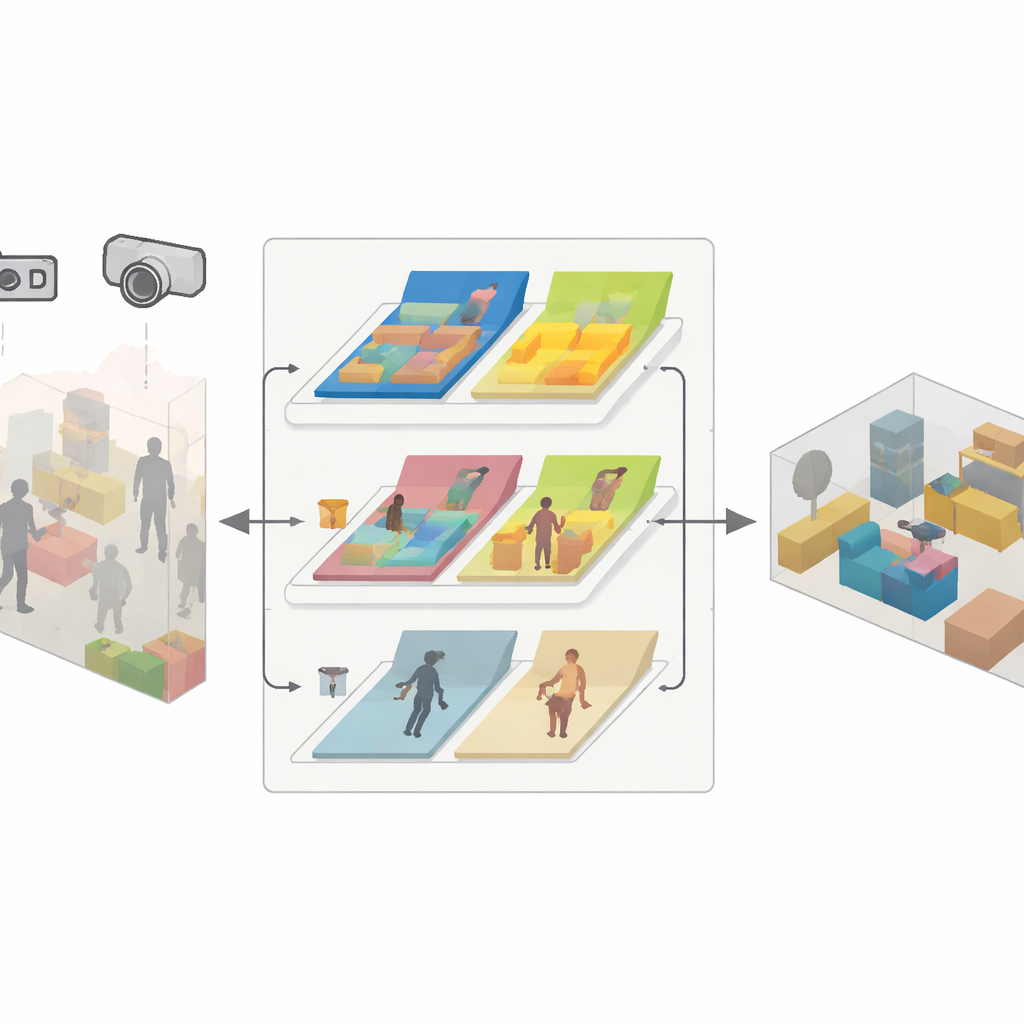
Ein dreiteiliger Motor für zuverlässige Kartierung
SDMFusion baut auf dem populären ORB-SLAM3-System auf und ergänzt es um drei eng verknüpfte Module, um diese Hürden zu überwinden. Erstens liefert ein Skalen–Tiefen-Modul jedes Bild an ein leistungsfähiges neuronales Netzwerk namens DepthAnythingV2, das die Entfernung zu jedem Pixel schätzt. Bei einer Einzelkamera liefert diese Vorhersage die fehlende reale Skala; bei Stereo- und RGB‑D-Kameras dient sie dazu, rohe Tiefendaten zu glätten und Lücken zu füllen. Zweitens identifiziert ein dynamisches Feature-Modul Objekte, die sich bewegen könnten, mithilfe eines schnellen Segmentierungsnetzwerks, das von der aktuellen YOLO-Familie inspiriert ist. Es gruppiert Personen, Autos und potenziell bewegliche Gegenstände wie Stühle und prüft dann Merkmal für Merkmal, ob sie sich zwischen den Frames tatsächlich bewegen, mithilfe geometrischer Konsistenztests. Nur Merkmale, die wirklich zu bewegten Teilen gehören, werden verworfen; stabile Merkmale bleiben erhalten, um präzises Tracking zu unterstützen. Drittens nimmt ein Anti-Dynamik-Rekonstruktionsmodul die verfeinerten Tiefen, verlässliche Kameraposen und Masken statischer Pixel und fusioniert nur die unbeweglichen Teile zu einer dichten 3D-Karte.
Wie die Methode in der Praxis abschneidet
Die Autoren haben SDMFusion ausführlich auf drei bekannten öffentlichen Datensätzen und auf Szenen getestet, die sie selbst mit einer kleinen Drohne aufgenommen haben. Die gewählten Datensätze decken Außenszenen beim Fahren, überladene Innenräume und stark dynamische Situationen mit Personen, die laufen, sitzen oder Kisten heben, ab — aufgenommen mit Monokular-, Stereo- und RGB‑D-Kameras. Sie verglichen SDMFusion mit mehreren fortgeschrittenen Systemen, darunter ORB-SLAM3, DS-SLAM, DynaSLAM und RDS-SLAM, und nutzten standardisierte Maße dafür, wie genau die geschätzte Kameraposition der Referenz entspricht. In den meisten Sequenzen erreichte SDMFusion geringere Fehler und höhere Erfolgsraten, besonders bei den anspruchsvollsten dynamischen Szenen und bei Einzelkameras, bei denen die Schätzbarkeit der Skala am schwierigsten ist. Optisch sind die dichten Karten vollständiger und frei von den „Geistern“ und verschwommenen Formen, die entstehen, wenn sich bewegende Personen fälschlich in die statische Umgebung fusioniert werden.

Stärken, Grenzen und zukünftige Richtungen
Die Ergebnisse zeigen, dass die Kombination aus starker Tiefenvorhersage, sorgfältiger Behandlung dynamischer Objekte und selektiver Rekonstruktion Karten liefert, die sowohl detailliert als auch vertrauenswürdig sind. SDMFusion läuft in Echtzeit auf einer leistungsfähigen Desktop-Grafikkarte und ist auf Embedded-Hardware zwar langsamer, doch die Autoren demonstrieren erhebliche Geschwindigkeitsgewinne durch die Optimierung des Tiefennetzwerks mit TensorRT. Sie untersuchen auch die Bedeutung der einzelnen Module durch Ablationsstudien und bestätigen, dass Skalenwiederherstellung, Segmentierung und Motion-Checks messbar zur Genauigkeit und Robustheit beitragen. Dennoch kann das System versagen, wenn nahezu das gesamte Sichtfeld von einem einzigen bewegten Objekt eingenommen wird und zu wenige klar statische Regionen übrig bleiben, an denen es sich festhalten kann; die Leistung bei Monokular-Setups bleibt in sehr komplexen Szenen hinter Stereo und RGB‑D zurück.
Was das für Alltagstaugliche Roboter bedeutet
Für den Laien ist die Kernaussage, dass SDMFusion die kamerabasierte Kartierung näher an das heranbringt, wie wir uns wünschen, dass Roboter und AR-Geräte in der realen Welt arbeiten: Es erstellt dichte, skalierte 3D-Modelle, ignoriert bei Bedarf Personen und andere Bewegungsquellen und verfolgt seine eigene Position mit hoher Zuverlässigkeit. Obwohl es Verbesserungsbedarf bei kleinen Geräten und in extrem überfüllten Szenen gibt, zeigt diese Arbeit einen klaren Weg zu erschwinglichen Maschinen, die sich in belebten Wohnungen, Büros und auf Straßen allein mit leichten Kameras orientieren können.
Zitation: Cen, N., Xu, Y., Wong, TW. et al. Scale aware dense dynamic SLAM for monocular, stereo and RGBD cameras. Sci Rep 16, 10285 (2026). https://doi.org/10.1038/s41598-026-41208-9
Schlüsselwörter: visueller SLAM, 3D-Kartierung, Roboter-Navigation, dynamische Umgebungen, Tiefenschätzung