Clear Sky Science · fr
SLAM dynamique dense conscient de l'échelle pour caméras monoculaires, stéréo et RGB-D
Cartes numériques plus intelligentes pour des mondes en mouvement et en transformation
Les robots, drones et casques de réalité augmentée ont tous besoin d’une compréhension détaillée de leur environnement pour se déplacer de façon sûre et fluide. Pourtant, la plupart des systèmes de cartographie échouent lorsque des personnes passent, des voitures circulent ou des meubles sont déplacés. Cet article présente SDMFusion, une nouvelle approche de cartographie capable de construire, en temps réel, des cartes 3D riches et précises même lorsque le monde autour de la caméra est plein de mouvements, et qui fonctionne avec plusieurs types de caméras courants.
Pourquoi les systèmes de vision traditionnels montrent leurs limites
Beaucoup de robots s’appuient sur le SLAM visuel, une technique qui permet à une caméra de déterminer sa position tout en construisant simultanément une carte. Les systèmes classiques supposent que le monde est majoritairement immobile et produisent souvent des cartes clairsemées composées de quelques points suivis. Ils peinent aussi avec une caméra unique, car celle-ci ne peut pas déterminer l’échelle réelle de la scène : un petit jouet proche de l’objectif ressemble à un grand objet éloigné. Les personnes et objets en mouvement perturbent ces méthodes, entraînant une dérive de la trajectoire estimée de la caméra et rendant la carte peu fiable. Ces faiblesses limitent l’usage de caméras bon marché dans des maisons, rues et lieux de travail réels.
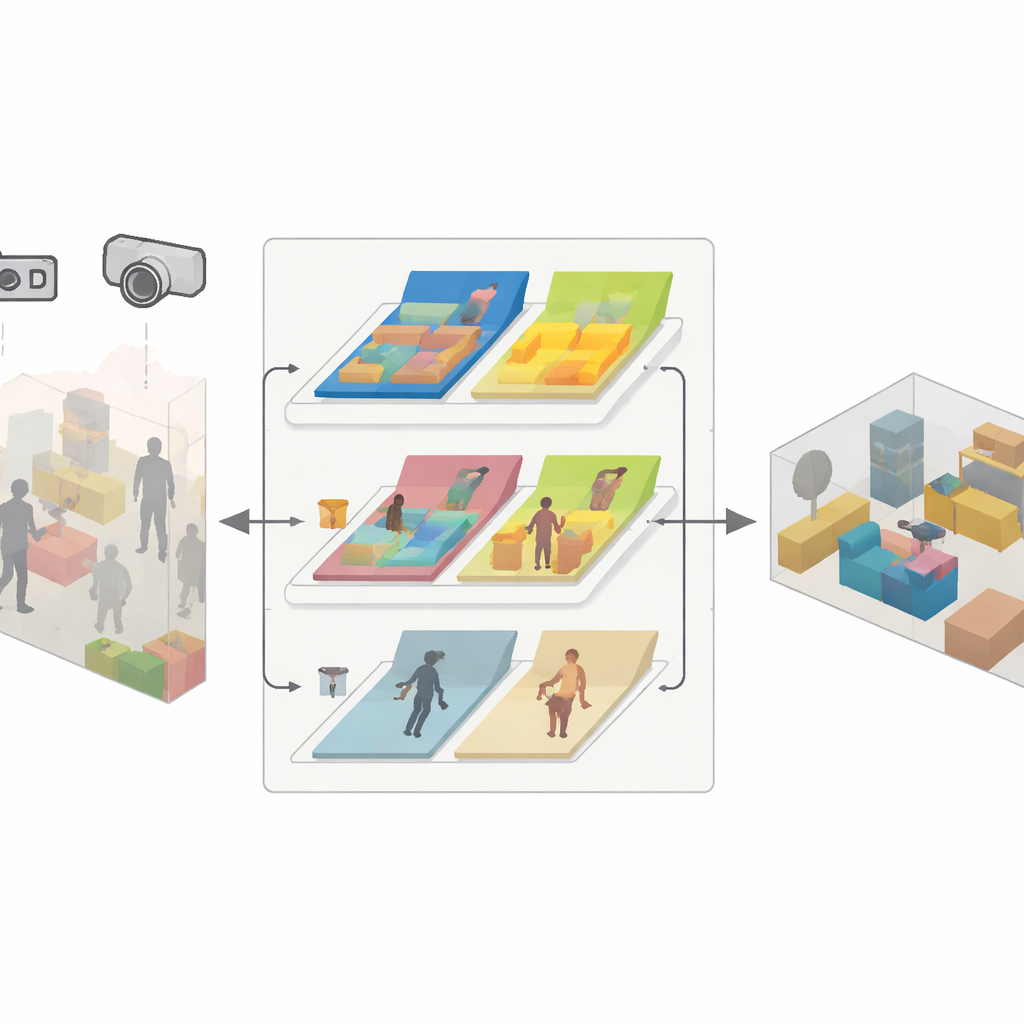
Un moteur en trois volets pour une cartographie fiable
SDMFusion repose sur le populaire ORB-SLAM3 mais ajoute trois modules étroitement liés pour surmonter ces obstacles. D’abord, un module échelle–profondeur alimente chaque image dans un puissant réseau de neurones appelé DepthAnythingV2, qui estime la distance pour chaque pixel. Pour une caméra monoculaire, cette prédiction fournit l’échelle réelle manquante ; pour les caméras stéréo et RGB-D, elle sert à lisser et combler les lacunes des lectures de profondeur brutes. Ensuite, un module de caractéristiques dynamiques détecte les objets susceptibles de bouger, en s’appuyant sur un réseau de segmentation rapide inspiré des dernières familles YOLO. Il regroupe des éléments comme les personnes, les voitures et même des objets potentiellement déplaçables tels que les chaises, puis vérifie, caractéristique par caractéristique, s’ils bougent réellement entre les images en utilisant des tests de cohérence géométrique. Seules les caractéristiques appartenant réellement aux parties en mouvement sont écartées, tandis que les éléments stables sont conservés pour soutenir un suivi précis. Enfin, un module de reconstruction anti-dynamique utilise les profondeurs affinées, les poses de caméra fiables et les masques de pixels statiques pour fusionner uniquement les parties immobiles dans une carte 3D dense.
Performances de la méthode en pratique
Les auteurs ont soumis SDMFusion à des tests approfondis sur trois jeux de données publics bien connus et sur des scènes qu’ils ont enregistrées eux-mêmes avec un petit drone. Les jeux de données choisis couvrent la conduite en extérieur, des pièces intérieures encombrées et des situations très dynamiques avec des personnes marchant, s’asseyant ou soulevant des cartons, capturées par des caméras monoculaires, stéréo et RGB-D. Ils ont comparé SDMFusion à plusieurs systèmes avancés, dont ORB-SLAM3, DS-SLAM, DynaSLAM et RDS-SLAM, en utilisant des mesures standard de la proximité entre la trajectoire estimée de la caméra et la vérité terrain. Sur la plupart des séquences, SDMFusion a obtenu des erreurs plus faibles et des taux de réussite plus élevés, en particulier pour les scènes dynamiques les plus difficiles et pour les configurations monoculaires où l’estimation de l’échelle est la plus délicate. Visuellement, ses cartes denses sont plus complètes et exempts des « fantômes » et formes floues qui apparaissent lorsque des personnes en mouvement sont fusionnées à tort dans l’environnement statique.

Forces, limites et pistes futures
Les résultats montrent que la combinaison d’une forte prédiction de profondeur, d’un traitement attentif des objets dynamiques et d’une reconstruction sélective produit des cartes à la fois détaillées et fiables. SDMFusion fonctionne en temps réel sur une carte graphique de bureau puissante, et bien que plus lent sur du matériel embarqué, les auteurs démontrent d’importants gains de vitesse en optimisant le réseau de profondeur avec TensorRT. Ils évaluent aussi l’importance de chaque module par des études d’ablation, confirmant que la récupération de l’échelle, la segmentation et les vérifications de mouvement contribuent toutes de manière sensible à la précision et à la robustesse. Néanmoins, le système peut échouer lorsque presque toute la vue est occupée par un seul objet en mouvement, laissant trop peu de régions clairement statiques sur lesquelles s’appuyer, et les performances monoculaires restent en retrait par rapport au stéréo et au RGB-D dans des scènes très complexes.
Ce que cela signifie pour les robots du quotidien
Pour un observateur non spécialiste, la conclusion principale est que SDMFusion rapproche la cartographie par caméra du comportement attendu pour les robots et appareils de réalité augmentée dans le monde réel : il construit des modèles 3D denses et mis à l’échelle, ignore les personnes et autres objets mobiles lorsque c’est approprié, et suit sa propre position avec une grande fiabilité. Bien qu’il reste des améliorations à apporter pour les petits appareils et dans des scènes extrêmement bondées, ce travail montre une voie claire vers des machines abordables capables de naviguer dans des maisons, bureaux et rues animés en n’utilisant que des caméras légères.
Citation: Cen, N., Xu, Y., Wong, TW. et al. Scale aware dense dynamic SLAM for monocular, stereo and RGBD cameras. Sci Rep 16, 10285 (2026). https://doi.org/10.1038/s41598-026-41208-9
Mots-clés: SLAM visuel, cartographie 3D, navigation robotique, environnements dynamiques, estimation de profondeur