Clear Sky Science · pt
SLAM denso dinâmico com consciência de escala para câmeras monoculares, estéreo e RGB-D
Mapas digitais mais inteligentes para mundos em movimento e mudança
Robôs, drones e headsets de realidade aumentada precisam de um entendimento detalhado do ambiente para se mover com segurança e suavidade. Ainda assim, a maioria dos sistemas de mapeamento falha quando pessoas passam, carros circulam ou móveis são realocados. Este artigo apresenta o SDMFusion, uma nova abordagem de mapeamento que consegue construir mapas 3D ricos e precisos em tempo real, mesmo quando o mundo ao redor da câmera está cheio de movimento, e que funciona com vários tipos comuns de câmeras.
Por que os sistemas de visão tradicionais ficam aquém
Muitos robôs dependem de SLAM visual, uma técnica que permite à câmera determinar sua posição enquanto constrói um mapa ao mesmo tempo. Sistemas clássicos assumem que o mundo é, em sua maior parte, estático e frequentemente produzem apenas mapas esparsos feitos de alguns pontos rastreados. Eles também têm dificuldade ao usar uma câmera única, pois não conseguem inferir o tamanho real da cena: um brinquedo pequeno próximo à lente parece um objeto grande e distante. Pessoas e objetos em movimento confundem esses métodos, fazendo a trajetória estimada da câmera derivar e tornando o mapa pouco confiável. Essas limitações restringem o uso de câmeras de baixo custo em casas, ruas e locais de trabalho reais.
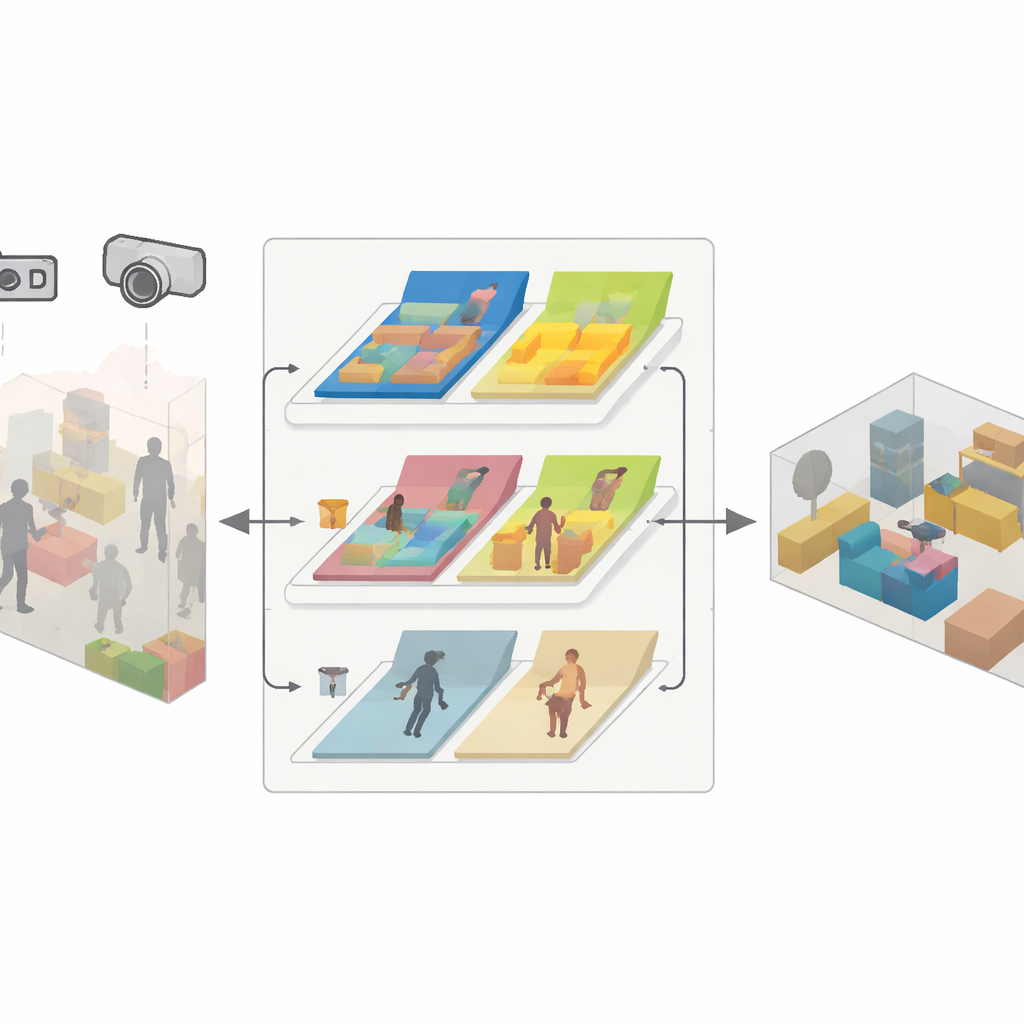
Um motor em três partes para mapeamento confiável
O SDMFusion é construído sobre o popular ORB-SLAM3, mas adiciona três módulos estreitamente integrados para superar esses obstáculos. Primeiro, um módulo escala–profundidade alimenta cada imagem em uma poderosa rede neural chamada DepthAnythingV2, que estima a distância de cada pixel. Para uma única câmera, essa previsão fornece a escala do mundo real que estava faltando; para câmeras estéreo e RGB-D, ela é usada para suavizar e preencher lacunas nas leituras de profundidade bruta. Segundo, um módulo de recursos dinâmicos busca objetos que possam se mover, usando uma rede rápida de segmentação inspirada na família mais recente do YOLO. Ele agrupa coisas como pessoas, carros e até objetos potencialmente movíveis, como cadeiras, e então verifica, característica por característica, se elas realmente se movem entre quadros usando testes de consistência geométrica. Apenas as características que pertencem a partes móveis são descartadas, enquanto as estáveis são mantidas para suportar o rastreamento preciso. Terceiro, um módulo de reconstrução anti-dinâmica usa as profundidades refinadas, poses de câmera confiáveis e máscaras de pixels estáticos para fundir apenas as partes imóveis em um mapa 3D denso.
Como o método se sai na prática
Os autores submeteram o SDMFusion a testes extensivos em três conjuntos de dados públicos bem conhecidos e em cenas gravadas por eles mesmos com um pequeno drone. Os conjuntos escolhidos cobrem direção ao ar livre, salas internas cheias de objetos e situações altamente dinâmicas com pessoas andando, sentando ou levantando caixas, capturadas por câmeras monoculares, estéreo e RGB-D. Eles compararam o SDMFusion com vários sistemas avançados, incluindo ORB-SLAM3, DS-SLAM, DynaSLAM e RDS-SLAM, usando medidas padrão de quão próxima a trajetória estimada da câmera está da verdade de solo. Em grande parte das sequências, o SDMFusion obteve erros menores e taxas de sucesso mais altas, especialmente nas cenas dinâmicas mais difíceis e em configurações com câmera única, onde a estimativa de escala é mais desafiadora. Visualmente, seus mapas densos são mais completos e livres dos "fantasmas" e formas borradas que aparecem quando pessoas em movimento são erroneamente fundidas ao ambiente estático.

Forças, limites e direções futuras
Os resultados mostram que combinar previsão de profundidade robusta, tratamento cuidadoso de objetos dinâmicos e reconstrução seletiva gera mapas detalhados e confiáveis. O SDMFusion roda em tempo real em uma placa gráfica desktop poderosa e, embora seja mais lento em hardware embarcado, os autores demonstram grandes ganhos de velocidade ao otimizar a rede de profundidade com TensorRT. Eles também avaliam a importância de cada módulo por meio de estudos de ablação, confirmando que recuperação de escala, segmentação e checagens de movimento contribuem de forma perceptível para a precisão e robustez. Ainda assim, o sistema pode falhar quando quase toda a cena é ocupada por um único objeto em movimento, deixando poucas regiões claramente estáticas para se ancorar, e o desempenho monocular continua atrás do estéreo e do RGB-D em cenas muito complexas.
O que isso significa para robôs do dia a dia
Para um observador leigo, a principal conclusão é que o SDMFusion aproxima o mapeamento por câmera do comportamento desejado para robôs e dispositivos de AR no mundo real: ele constrói modelos 3D densos e com escala, ignora pessoas e outros móveis quando apropriado e mantém o rastreamento da própria posição com alta confiabilidade. Embora haja espaço para melhorias em dispositivos pequenos e em cenas extremamente lotadas, este trabalho mostra um caminho claro rumo a máquinas acessíveis que podem navegar por casas, escritórios e ruas movimentadas usando apenas câmeras leves.
Citação: Cen, N., Xu, Y., Wong, TW. et al. Scale aware dense dynamic SLAM for monocular, stereo and RGBD cameras. Sci Rep 16, 10285 (2026). https://doi.org/10.1038/s41598-026-41208-9
Palavras-chave: SLAM visual, mapeamento 3D, navegação robótica, ambientes dinâmicos, estimativa de profundidade