Clear Sky Science · pl
Skalowalny, świadomy gęstości dynamiczny SLAM dla kamer monokularnych, stereo i RGBD
Inteligentniejsze mapy cyfrowe dla poruszających się, zmieniających się światów
Roboty, drony i zestawy do rzeczywistości rozszerzonej potrzebują szczegółowej znajomości otoczenia, by poruszać się bezpiecznie i płynnie. Tymczasem większość systemów mapowania zawodzi, gdy ludzie przechodzą obok, samochody przejeżdżają lub przesuwane jest umeblowanie. Niniejszy artykuł przedstawia SDMFusion — nowe podejście do mapowania, które na żywo tworzy bogate, dokładne mapy 3D nawet gdy otoczenie kamery pełne jest ruchu, i działa z kilkoma powszechnymi typami kamer.
Dlaczego tradycyjne systemy wizyjne zawodzą
Wiele robotów polega na wizualnym SLAMie, technice pozwalającej kamerze ustalić swoją pozycję przy jednoczesnym budowaniu mapy. Klasyczne systemy zakładają, że świat jest w większości statyczny i często generują jedynie rzadkie mapy złożone z kilku śledzonych punktów. Mają też trudności przy użyciu pojedynczej kamery, ponieważ nie rozróżniają rzeczywistej skali sceny: mała zabawka blisko obiektywu wygląda jak duży obiekt daleko. Poruszający się ludzie i przedmioty wprowadzają te metody w błąd, powodując dryf estymowanej ścieżki kamery i nierzetelność mapy. Te słabości ograniczają użyteczność tanich kamer w prawdziwych domach, na ulicach i w miejscach pracy.
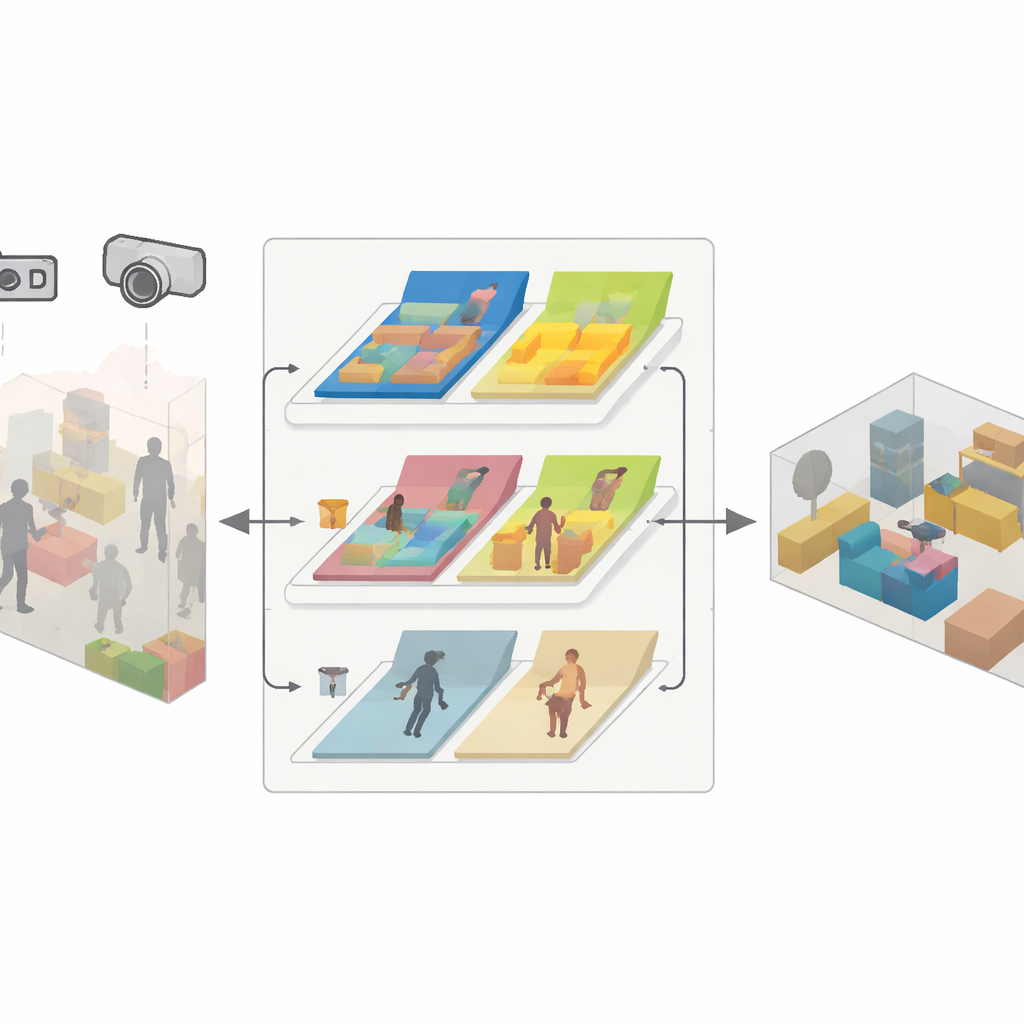
Silnik w trzech częściach dla niezawodnego mapowania
SDMFusion bazuje na popularnym systemie ORB-SLAM3, ale dodaje trzy ściśle powiązane moduły, by pokonać te przeszkody. Po pierwsze, moduł skali–głębi przepuszcza każde zdjęcie przez potężną sieć neuronową nazwaną DepthAnythingV2, która przewiduje odległość dla każdego piksela. Dla kamery monokularnej to przewidywanie dostarcza brakującej skali realnego świata; dla kamer stereo i RGB‑D służy do wygładzania i uzupełniania surowych pomiarów głębi. Po drugie, moduł cech dynamicznych wykrywa obiekty mogące się poruszać, używając szybkiej sieci segmentacyjnej inspirowanej najnowszą rodziną YOLO. Grupuje elementy takie jak ludzie, samochody, a nawet potencjalnie przestawialne obiekty typu krzesła, a następnie sprawdza, cecha po cesze, czy rzeczywiście poruszają się między klatkami, stosując testy spójności geometrycznej. Tylko cechy należące naprawdę do ruchomych części są odrzucane; stabilne cechy pozostają, by wspierać precyzyjne śledzenie. Po trzecie, moduł rekonstrukcji przeciw-dynamicznej wykorzystuje poprawione estymacje głębi, wiarygodne pozycje kamery i maski pikseli statycznych, by fuzjonować jedynie nieruchome części w gęstą mapę 3D.
Jak metoda sprawdza się w praktyce
Autorzy przetestowali SDMFusion na trzech dobrze znanych publicznych zbiorach danych oraz na scenach nagranych samodzielnie małym dronem. Wybrane zbiory obejmują jazdę na zewnątrz, zatłoczone wnętrza oraz wysoce dynamiczne sytuacje z ludźmi chodzącymi, siedzącymi lub podnoszącymi pudełka, zarejestrowane kamerami monokularnymi, stereo i RGB‑D. Porównali SDMFusion z kilkoma zaawansowanymi systemami, w tym ORB-SLAM3, DS-SLAM, DynaSLAM i RDS-SLAM, używając standardowych miar dopasowania estymowanej ścieżki kamery do danych referencyjnych. W większości sekwencji SDMFusion osiągnął niższe błędy i wyższe wskaźniki sukcesu, zwłaszcza w najbardziej wymagających dynamicznych scenach oraz w konfiguracjach z pojedynczą kamerą, gdzie estymacja skali jest najtrudniejsza. Wizualnie jego gęste mapy są bardziej kompletne i pozbawione „duchów” oraz rozmytych kształtów, które pojawiają się, gdy poruszający się ludzie są błędnie zintegrowani jako część statycznego otoczenia.

Mocne strony, ograniczenia i kierunki rozwoju
Wyniki pokazują, że połączenie silnej predykcji głębi, starannego traktowania obiektów dynamicznych i selektywnej rekonstrukcji daje mapy zarówno szczegółowe, jak i godne zaufania. SDMFusion działa w czasie rzeczywistym na wydajnej karcie graficznej stacjonarnego komputera, a chociaż wolniej na sprzęcie wbudowanym, autorzy demonstrują duże przyspieszenia dzięki optymalizacji sieci głębi z użyciem TensorRT. Przeprowadzili też badania ablacyjne, badając znaczenie każdego modułu, potwierdzając, że odzyskiwanie skali, segmentacja i testy ruchu każdorazowo wnoszą zauważalny wkład w dokładność i odporność systemu. Niemniej system może zawieść, gdy niemal cały obraz zajmuje pojedynczy poruszający się obiekt, pozostawiając zbyt mało wyraźnie statycznych obszarów do wykorzystania, a wydajność monokularna nadal ustępuje stereo i RGB‑D w bardzo złożonych scenach.
Co to oznacza dla codziennych robotów
Dla laika kluczowy wniosek jest taki, że SDMFusion przybliża mapowanie oparte na kamerach do zachowania, jakiego oczekujemy od robotów i urządzeń AR w świecie rzeczywistym: buduje gęste, skalowane modele 3D, ignoruje ludzi i inne poruszające się obiekty tam, gdzie to właściwe, i niezawodnie śledzi własną pozycję. Choć jest miejsce na ulepszenia na małych urządzeniach i w ekstremalnie zatłoczonych scenach, praca ta wskazuje jasną ścieżkę do niedrogich maszyn, które potrafią nawigować po ruchliwych domach, biurach i ulicach, korzystając wyłącznie z lekkich kamer.
Cytowanie: Cen, N., Xu, Y., Wong, TW. et al. Scale aware dense dynamic SLAM for monocular, stereo and RGBD cameras. Sci Rep 16, 10285 (2026). https://doi.org/10.1038/s41598-026-41208-9
Słowa kluczowe: wizualny SLAM, mapowanie 3D, nawigacja robotów, dynamiczne środowiska, estymacja głębi