Clear Sky Science · ar
SLAM ديناميكي كثيف مدرك للمقياس للكاميرات أحادية العدسة، والاستيريو، وRGB-D
خرائط رقمية أذكى لعوالم متحركة ومتغيرة
تحتاج الروبوتات والطائرات المسيّرة ونظارات الواقع المعزّز إلى فهم تفصيلي لمحيطها كي تتحرك بأمان وسلاسة. ومع ذلك، تتعثر معظم أنظمة الخرائط عندما يمر الناس أو تمر السيارات أو يتم تحريك الأثاث. تقدم هذه الورقة SDMFusion، نهجًا جديدًا للخرائط قادرًا على بناء خرائط ثلاثية الأبعاد غنية ودقيقة في الوقت الحقيقي، حتى عندما يكون العالم حول الكاميرا مليئًا بالحركة، ويعمل مع عدة أنواع شائعة من الكاميرات.
لماذا تفشل أنظمة الرؤية التقليدية
تعتمد العديد من الروبوتات على SLAM البصري، وهي تقنية تسمح للكamera بتحديد موضعها أثناء بناء الخريطة في الوقت ذاته. تفترض الأنظمة الكلاسيكية أن العالم ثابت إلى حد كبير وتنتج غالبًا خرائط متفرقة مكوّنة من نقاط متتبعة قليلة. كما تواجه صعوبات عند استخدام كاميرا واحدة، لأنها لا تستطيع معرفة الحجم الحقيقي للمشهد: لعبة صغيرة قريبة من العدسة تبدو كجسم كبير بعيد. تحير الحركة مثل الأشخاص والأشياء المتحركة هذه الطرق، مما يسبب انجراف تقديرات مسار الكاميرا ويجعل الخريطة غير موثوقة. تقيد هذه الضعف استخدام الكاميرات منخفضة التكلفة في المنازل والشوارع ومواقع العمل الحقيقية.
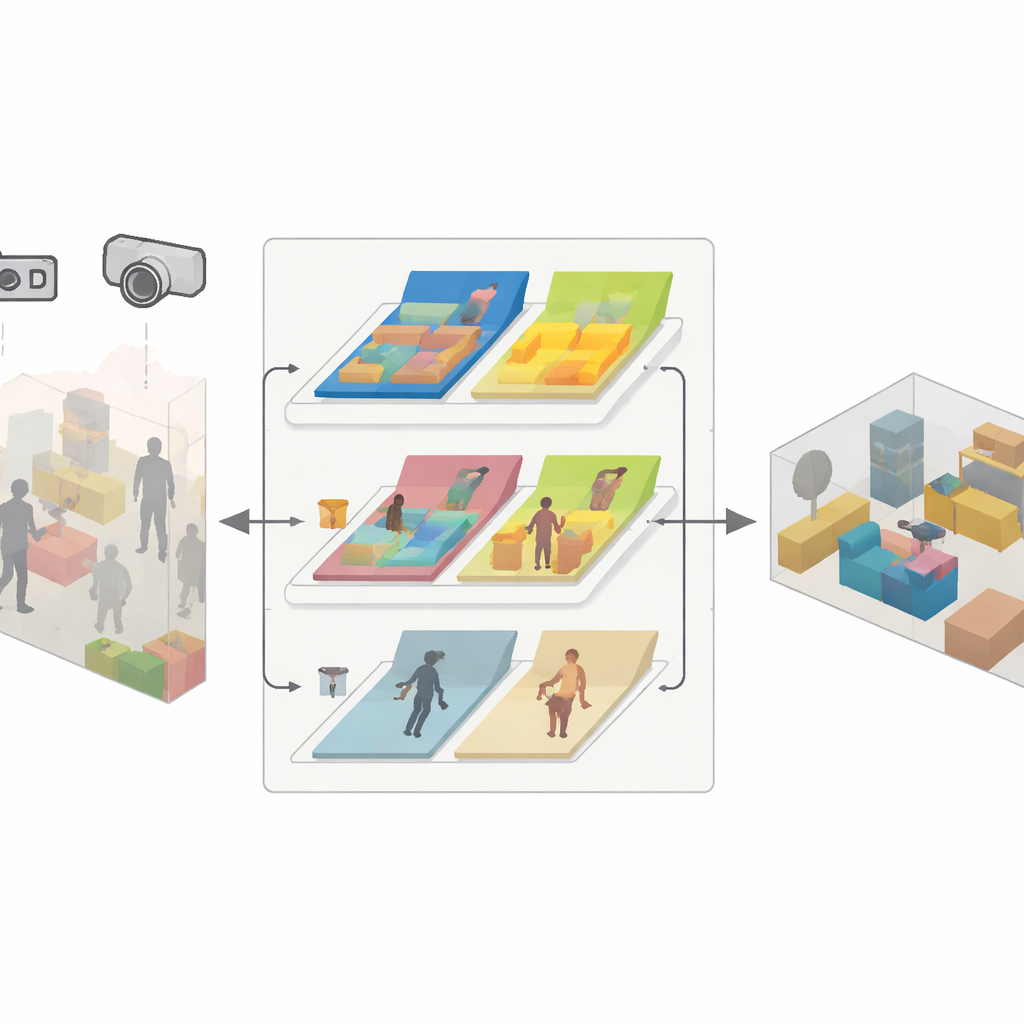
محرك من ثلاثة أجزاء لخرائط موثوقة
يبنى SDMFusion فوق النظام الشهير ORB-SLAM3 لكنه يضيف ثلاثة مكونات مترابطة لتجاوز هذه العقبات. أولًا، وحدة المقياس–العمق تُدخِل كل صورة إلى شبكة عصبية قوية تُدعى DepthAnythingV2، والتي تتنبأ بمسافة كل بكسل. بالنسبة للكاميرا الأحادية، تمنح هذه التوقعات المقياس الحقيقي المفقود؛ أما بالنسبة لكاميرات الاستيريو وRGB-D، فتستخدم لتنعيم وملء الفجوات في قراءات العمق الخام. ثانيًا، وحدة الميزات الديناميكية تبحث عن الأشياء التي قد تتحرك باستخدام شبكة تجزئة سريعة مستوحاة من أحدث عائلة YOLO. تجمع هذه الوحدة أشياء مثل الأشخاص، والسيارات، وحتى الأجسام التي قد تُنقل مثل الكراسي، ثم تتحقق، ميزة بميزة، مما إذا كانت تتحرك فعليًا بين الإطارات باستخدام اختبارات التوافق الهندسي. تُستبعد فقط الميزات التي تنتمي فعلًا إلى أجزاء متحركة، بينما تُحتفظ بالميزات الثابتة لدعم التتبع الدقيق. ثالثًا، تأخذ وحدة إعادة الإعمار المقاومة للحركة الأعماق المصقولة، ووضعيات الكاميرا الموثوقة، وأقنعة البكسلات الثابتة لدمج الأجزاء غير المتحركة فقط في خريطة ثلاثية الأبعاد كثيفة.
كيف يعمل الأسلوب عمليًا
اختبر المؤلفون SDMFusion بشكل واسع على ثلاث مجموعات بيانات عامة معروفة وعلى مشاهد سجّلوها بأنفسهم بطائرة صغيرة. تغطي مجموعات البيانات المختارة القيادة في الخارج، وغرفًا داخلية مزدحمة، وحالات ديناميكية عالية يتجول فيها أشخاص أو يجلسون أو يرفعون صناديق، تم التقاطها بكاميرات أحادية واستيريو وRGB-D. قارنوا SDMFusion بعدة أنظمة متقدمة، بما في ذلك ORB-SLAM3 وDS-SLAM وDynaSLAM وRDS-SLAM، باستخدام مقاييس معيارية لمدى تطابق مسار الكاميرا المُقدّر مع الحقيقة القياسية. في معظم التسلسلات، حقق SDMFusion أخطاء أقل ومعدلات نجاح أعلى، لا سيما في أصعب المشاهد الديناميكية ولإعدادات الكاميرا الأحادية حيث يكون تقدير المقياس أكثر تحديًا. بصريًا، خرائطه الكثيفة أكثر اكتمالًا وخالية من "الأشباح" والأشكال الملطخة التي تظهر عندما تُدمج الأشخاص المتحركة عن طريق الخطأ في البيئة الثابتة.

نقاط القوة والقيود والاتجاهات المستقبلية
تُظهر النتائج أن الجمع بين توقع عمق قوي، ومعالجة متأنية للأجسام الديناميكية، وإعادة إعمار انتقائية يؤدي إلى خرائط مفصّلة وموثوقة. يعمل SDMFusion في الوقت الحقيقي على بطاقة رسومات مكتبية قوية، ومع أنه أبطأ على الأجهزة المدمجة، يوضح المؤلفون زيادات كبيرة في السرعة عبر تحسين شبكة العمق باستخدام TensorRT. كما يفحصون أهمية كل وحدة من خلال دراسات إغفال (ablation)، مؤكدين أن استعادة المقياس والتجزئة وفحوص الحركة تساهم كلها بشكل ملحوظ في الدقة والصلابة. ومع ذلك، قد يفشل النظام عندما يغطي جسم متحرك واحد تقريبًا كامل المجال المرئي، مما يترك مناطق ثابتة واضحة قليلة جدًا للارتكاز عليها، ولا تزال أداءات الكاميرا الأحادية متأخرة عن الاستيريو وRGB-D في المشاهد المعقدة جدًا.
ماذا يعني هذا للروبوتات اليومية
للمشاهد العادي، الخلاصة أن SDMFusion يقرب خرائط الكاميرا من السلوك الذي نرغب أن تتبناه الروبوتات وأجهزة الواقع المعزّز في العالم الحقيقي: يبني نماذج ثلاثية الأبعاد كثيفة ومقاسة، يتجاهل الأشخاص والمتحركين عندما يكون ذلك مناسبًا، ويتتبع موقعه بدقة عالية. ومع وجود مجال لتحسين الأداء على الأجهزة الصغيرة وفي المشاهد المزدحمة للغاية، تُظهر هذه الدراسة مسارًا واضحًا نحو آلات ميسورة التكلفة يمكنها التنقّل في المنازل والمكاتب والشوارع المزدحمة باستخدام كاميرات خفيفة الوزن فقط.
الاستشهاد: Cen, N., Xu, Y., Wong, TW. et al. Scale aware dense dynamic SLAM for monocular, stereo and RGBD cameras. Sci Rep 16, 10285 (2026). https://doi.org/10.1038/s41598-026-41208-9
الكلمات المفتاحية: SLAM بصري, رسم خرائط ثلاثي الأبعاد, ملاحة روبوتية, بيئات ديناميكية, تقدير العمق