Clear Sky Science · ru
Учёт масштаба в плотном динамическом SLAM для монокулярных, стерео- и RGB-D камер
Более умные цифровые карты для меняющегося мира
Роботам, дронам и гарнитурам дополненной реальности нужна точная модель окружения, чтобы передвигаться безопасно и плавно. Однако большинство систем картирования спотыкаются, когда мимо проходят люди, проезжают автомобили или переставляют мебель. В этой статье представлена SDMFusion — новая методика картирования, которая в реальном времени строит насыщенные и точные 3D-карты даже в сценах с интенсивным движением вокруг камеры, и при этом работает с несколькими распространёнными типами камер.
Почему традиционные системы зрения не справляются
Многие роботы полагаются на визуальный SLAM — приём, позволяющий камере одновременно определять своё положение и строить карту. Классические системы предполагают, что мир в основном неподвижен, и часто дают лишь разрежённые карты из нескольких отслеживаемых точек. Они также испытывают трудности при работе с одной камерой, поскольку не могут восстановить истинный масштаб сцены: маленькая игрушка вблизи выглядит как большой объект вдали. Движущиеся люди и предметы сбивают эти методы с толку, вызывая дрейф оценки траектории камеры и снижая надёжность карты. Эти ограничения затрудняют применение недорогих камер в реальных домах, на улицах и на рабочих местах.
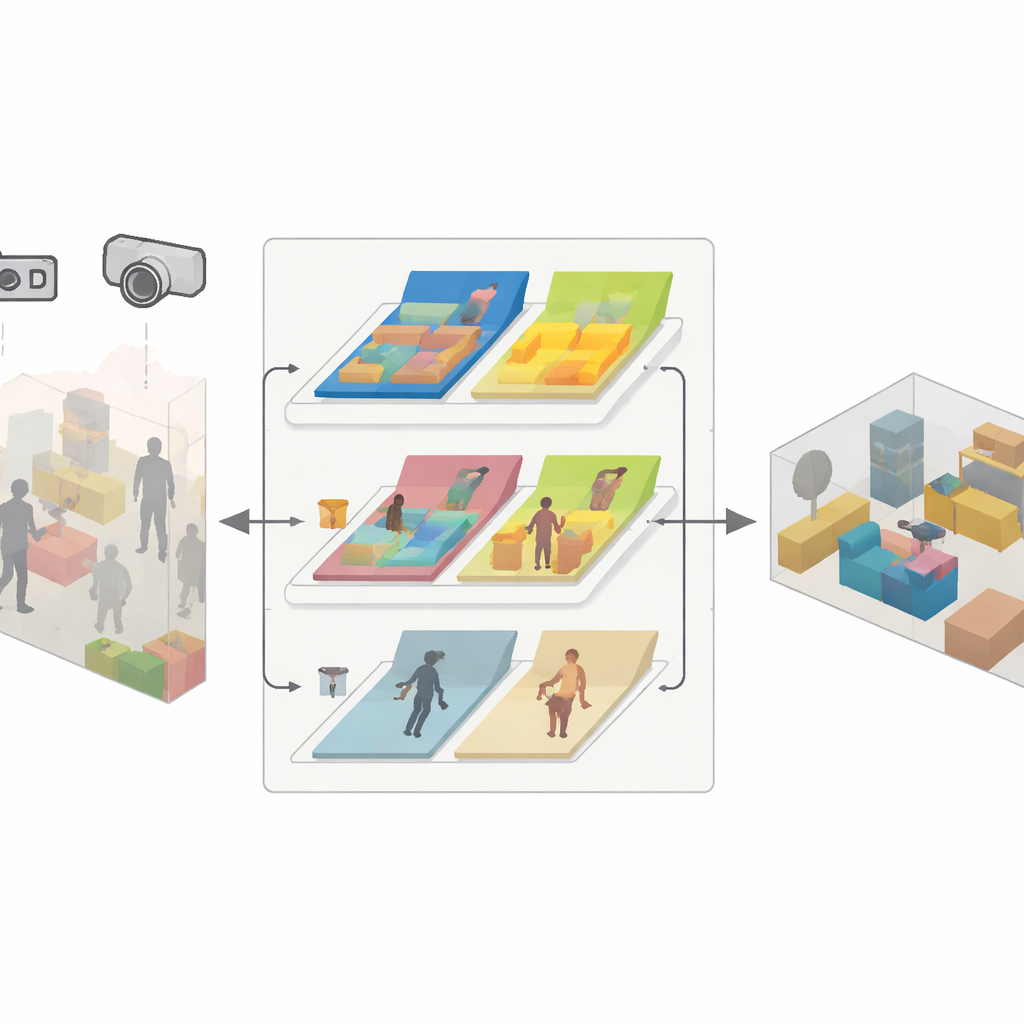
Трёхкомпонентный движок для надёжного картирования
SDMFusion создаётся на базе популярной системы ORB-SLAM3, но добавляет три тесно связанных модуля, чтобы преодолеть перечисленные трудности. Во‑первых, модуль масштаба–глубины пропускает каждое изображение через мощную нейросеть DepthAnythingV2, которая оценивает расстояние до каждого пикселя. В случае монокулярной камеры это предсказание даёт недостающий реальный масштаб; для стерео- и RGB‑D камер оно используется для сглаживания и заполнения пробелов в сырых данных глубины. Во‑вторых, модуль динамических признаков ищет объекты, которые могут двигаться, при помощи быстрого сегментационного нейронного сетевого решения, вдохновлённого последними моделями семейства YOLO. Он группирует людей, автомобили и даже потенциально подвижную мебель — например, стулья — затем по признаку проверяет, движется ли объект между кадрами с помощью геометрических тестов на согласованность. Отбрасываются только признаки, которые действительно принадлежат движущимся частям; стабильные признаки сохраняются для точного трекинга. В‑третьих, модуль анти‑динамической реконструкции использует уточнённые карты глубины, надёжные положения камеры и маски статичных пикселей, чтобы сливать в плотную 3D‑модель только неподвижные части сцены.
Как метод показывает себя на практике
Авторы подвергли SDMFusion обширным тестам на трёх известных публичных наборах данных и на сценах, записанных ими с небольшого дрона. Выбранные датасеты охватывают уличную езду, захламлённые внутренние помещения и сильно динамичные сцены с людьми, которые идут, сидят или поднимают коробки, снятые монокулярными, стерео‑ и RGB‑D камерами. Они сравнили SDMFusion с несколькими передовыми системами, включая ORB‑SLAM3, DS‑SLAM, DynaSLAM и RDS‑SLAM, используя стандартные метрики соответствия оценённой траектории камеры эталонной. В большинстве последовательностей SDMFusion показала меньшие ошибки и более высокие показатели успешности, особенно в самых сложных динамичных сценах и в случаях с одной камерой, где оценка масштаба особенно трудна. Визуально её плотные карты выглядят более полными и не содержат «призраков» и размазанных контуров, возникающих, когда движущиеся люди ошибочно сливаются со статичной средой.

Сильные стороны, ограничения и перспективы
Результаты показывают, что сочетание мощной предсказательной глубины, аккуратной обработки динамических объектов и выборочной реконструкции даёт карты, одновременно детальные и надёжные. SDMFusion работает в реальном времени на производительной десктопной видеокарте; на встроенном оборудовании он медленнее, но авторы демонстрируют значительное ускорение, оптимизируя сеть глубины с помощью TensorRT. Они также исследуют вклад каждого модуля через абляционные исследования, подтверждая, что восстановление масштаба, сегментация и проверки движения все заметно повышают точность и устойчивость. Тем не менее система может дать сбой, если почти всё поле зрения занимает один большой движущийся объект, оставляя слишком мало явно статичных областей для привязки; а в очень сложных сценах производительность монокуляра всё ещё уступает стерео и RGB‑D.
Что это значит для повседневных роботов
Для неспециалиста ключевой вывод таков: SDMFusion приближает картирование на основе камеры к тому поведению, которого мы ожидаем от роботов и AR‑устройств в реальном мире — система строит плотные масштабированные 3D‑модели, при необходимости игнорирует людей и другие движущиеся объекты и надёжно отслеживает своё положение. Хотя есть пространство для улучшений на маломощных устройствах и в исключительно людных сценах, работа показывает ясный путь к доступным машинам, способным ориентироваться в загруженных домах, офисах и на улицах, используя лишь легковесные камеры.
Цитирование: Cen, N., Xu, Y., Wong, TW. et al. Scale aware dense dynamic SLAM for monocular, stereo and RGBD cameras. Sci Rep 16, 10285 (2026). https://doi.org/10.1038/s41598-026-41208-9
Ключевые слова: визуальный SLAM, 3D картирование, навигация роботов, динамическая среда, оценка глубины