Clear Sky Science · en
Scale aware dense dynamic SLAM for monocular, stereo and RGBD cameras
Smarter digital maps for moving, changing worlds
Robots, drones, and augmented reality headsets all need a detailed understanding of their surroundings to move safely and smoothly. Yet most mapping systems stumble when people walk by, cars drive past, or furniture is moved. This paper introduces SDMFusion, a new mapping approach that can build rich, accurate 3D maps in real time, even when the world around the camera is full of motion, and it works with several common kinds of cameras.
Why traditional vision systems fall short
Many robots rely on visual SLAM, a technique that lets a camera figure out where it is while building a map at the same time. Classic systems assume that the world is mostly still and often produce only sparse maps made of a few tracked points. They also struggle when using a single camera, because they cannot tell how large the scene really is: a small toy close to the lens looks like a big object far away. Moving people and objects confuse these methods, causing the estimated path of the camera to drift and the map to become unreliable. These weaknesses limit the use of low-cost cameras in real homes, streets, and workplaces.
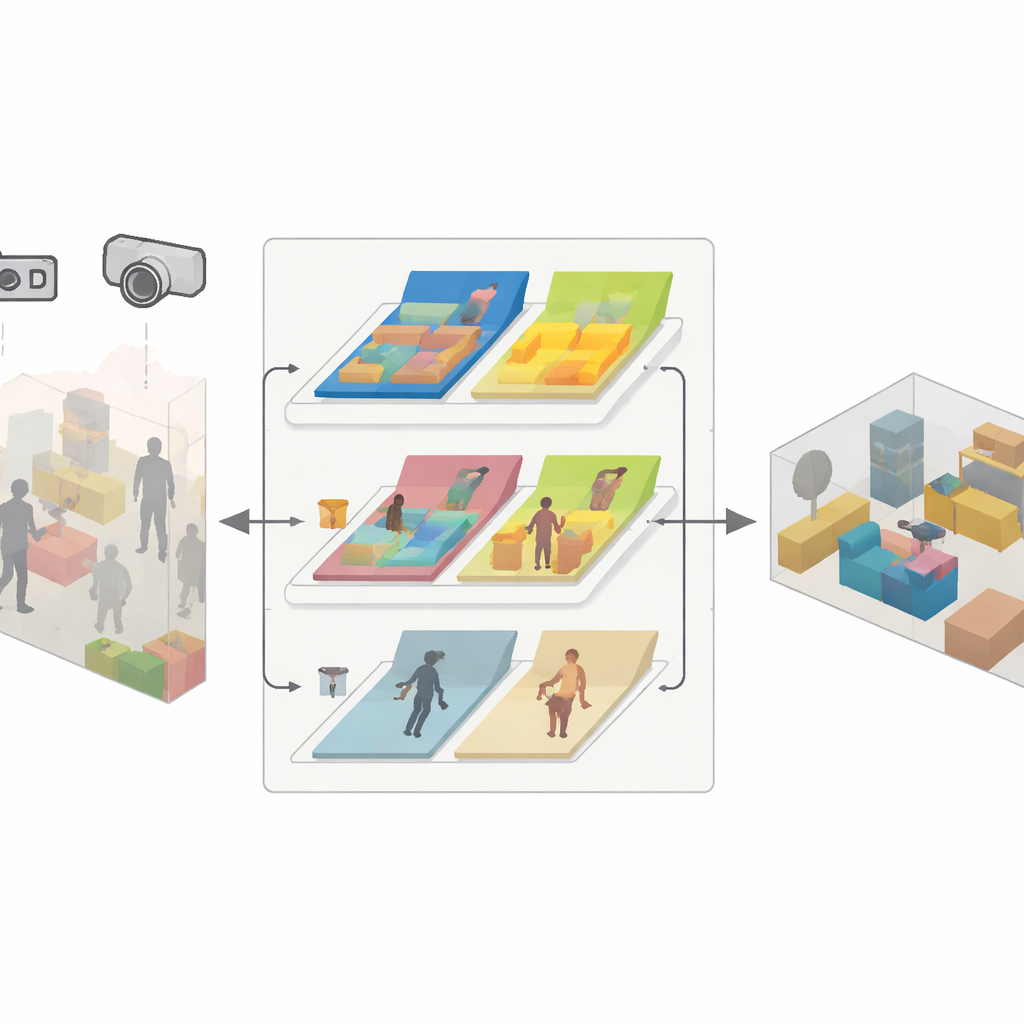
A three-part engine for reliable mapping
SDMFusion is built on top of the popular ORB-SLAM3 system but adds three tightly linked modules to overcome these hurdles. First, a scale–depth module feeds each image into a powerful neural network called DepthAnythingV2, which guesses the distance to every pixel. For a single camera, this prediction gives the missing real-world scale; for stereo and RGB-D cameras, it is used to smooth and fill gaps in their raw depth readings. Second, a dynamic–feature module looks for objects that might move, using a fast segmentation network inspired by the latest YOLO family. It groups things like people, cars, and even potentially movable objects such as chairs, then checks, feature by feature, whether they actually move between frames using geometric consistency tests. Only features that truly belong to moving parts are discarded, while stable ones are kept to support precise tracking. Third, an anti-dynamic reconstruction module takes the refined depths, reliable camera poses, and masks of static pixels to fuse only the unmoving parts into a dense 3D map.
How the method performs in practice
The authors put SDMFusion through extensive tests on three well-known public datasets and on scenes they recorded themselves with a small drone. The chosen datasets cover outdoor driving, cluttered indoor rooms, and highly dynamic situations with people walking, sitting, or lifting boxes, captured by monocular, stereo, and RGB-D cameras. They compared SDMFusion with several advanced systems, including ORB-SLAM3, DS-SLAM, DynaSLAM, and RDS-SLAM, using standard measures of how closely the estimated camera path matches ground truth. Across most sequences, SDMFusion achieved lower errors and higher success rates, especially for the hardest dynamic scenes and for single-camera setups where scale estimation is most challenging. Visually, its dense maps are more complete and free of the “ghosts” and smeared shapes that appear when moving people are mistakenly fused into the static environment.

Strengths, limits, and future directions
The results show that combining strong depth prediction, careful treatment of dynamic objects, and selective reconstruction yields maps that are both detailed and trustworthy. SDMFusion runs in real time on a powerful desktop graphics card, and while slower on embedded hardware, the authors demonstrate large speed gains by optimizing the depth network with TensorRT. They also probe the importance of each module through ablation studies, confirming that scale recovery, segmentation, and motion checks all contribute noticeably to accuracy and robustness. Still, the system can fail when almost the entire view is taken up by a single moving object, leaving too few clearly static regions to latch onto, and monocular performance still trails that of stereo and RGB-D in very complex scenes.
What this means for everyday robots
To a lay observer, the key takeaway is that SDMFusion brings camera-based mapping closer to how we would like robots and AR devices to behave in the real world: it builds dense, scaled 3D models, ignores people and other movers when appropriate, and keeps track of its own position with high reliability. While there is room for improvement on small devices and in extremely crowded scenes, this work shows a clear path toward affordable machines that can navigate busy homes, offices, and streets using only lightweight cameras.
Citation: Cen, N., Xu, Y., Wong, TW. et al. Scale aware dense dynamic SLAM for monocular, stereo and RGBD cameras. Sci Rep 16, 10285 (2026). https://doi.org/10.1038/s41598-026-41208-9
Keywords: visual SLAM, 3D mapping, robot navigation, dynamic environments, depth estimation