Clear Sky Science · sv
En ny superpixel‑baserad Vision Transformer för att förbättra tolkningsbarheten vid glaukomscreening
Varför ögonundersökningar och smarta maskiner spelar roll
Glaukom är en tyst ögonsjukdom som kan stjäla synen innan människor märker några symtom. Läkare kan upptäcka tidiga varningstecken i färgfotografier av ögats bakre del, men att noggrant granska varje bild är tidskrävande och kräver expertis. Artificiell intelligens (AI) kan hjälpa, men många kraftfulla system beter sig som ”svarta lådor” och ger liten insikt i hur de når ett beslut. Den här studien introducerar en ny AI‑metod som syftar till att behålla hög noggrannhet samtidigt som dess resonemang blir lättare för ögonspecialister att se och lita på.
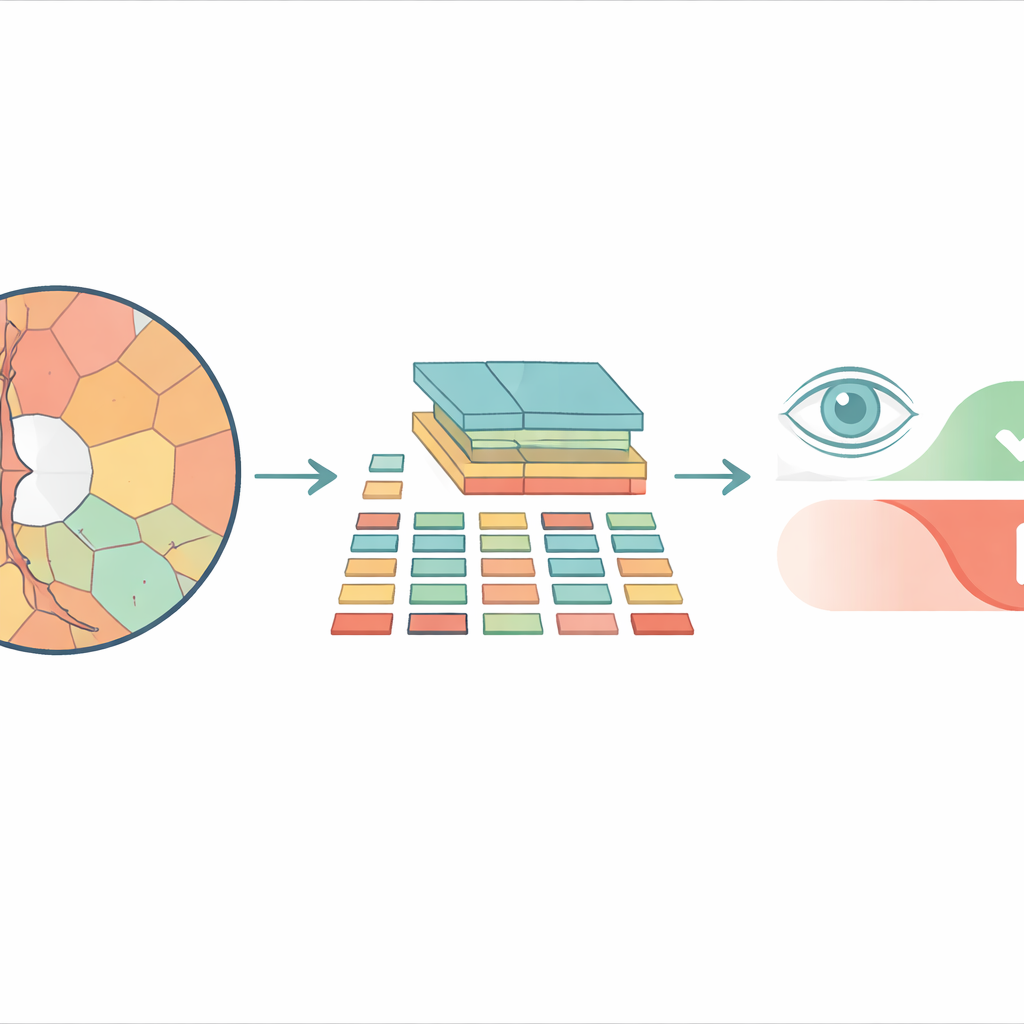
Från kvadratiska brickor till mer naturliga regioner
De flesta moderna bildanalysystem baserade på vision transformers delar en bild i ett schackmönster av identiska kvadratiska celler innan de bearbetas. Det fungerar kanske bra för vardagsfotografier, men bortser från hur verkliga strukturer i ögat är formade. Den optiska disken och den inre fördjupningen som kallas kopp har kurviga, oregelbundna konturer, och att tvinga dem in i stela fyrkanter blandar ihop viktiga och oviktiga detaljer. Forskarna använder istället ”superpixlar” — grupper av närliggande pixlar som delar liknande färg eller textur — för att dela upp retinalbilden i stycken som följer faktiska anatomiska gränser. Dessa superpixlar blir sedan grundläggande enheter, eller ”tokens”, som transformern analyserar.
Ett nytt sätt att mata bilder till transformern
Den föreslagna modellen, kallad Superpixel‑based Vision Transformer (SpxViT), behåller den interna mekaniken i en standard vision transformer nästan oförändrad och fokuserar på att omforma fronten. Innan bilden når transformern delar en befintlig algoritm (SLIC) upp den i 196 superpixlar, ungefär i nivå med antalet rutor som används i en vanlig baslinjemodell kallad ViT‑B/16. Varje oregelbundna region omvandlas till en numerisk beskrivning med fast längd så att den kan hanteras precis som en vanlig ruta. Två varianter testas: en som använder en konstant inställning för att gynna mer naturliga former (SpxViT_fix) och en annan som anpassar denna inställning för varje bild för att alltid producera exakt 196 regioner (SpxViT_var). Bortsett från detta tokeniseringssteg är transformerlagren och träningsproceduren desamma som i den klassiska modellen, vilket möjliggör en rättvis jämförelse.
Testning på verkliga ögonbilder
Teamet utvärderade sin metod på 739 retinalfotografier från en offentlig databas och en sjukhussamling, där varje bild var märkt av glaukomexperter. Specialister spårade också konturerna för optiska disken och koppen, vilket skapade detaljerade kartor över de mest kliniskt viktiga strukturerna. Flera transformer‑baserade system tränades från början och jämfördes: den standardiserade ViT‑B/16 med kvadratiska rutor, en annan superpixel‑baserad design från tidigare arbete, och de två SpxViT‑varianterna. Prestanda mättes med vanliga diagnostiska mått som balanserar hur väl en modell upptäcker sjuka ögon och korrekt avfärdar friska. Den klassiska ViT‑B/16 uppnådde bäst total noggrannhet, men SpxViT_var kom mycket nära och låg mindre än en procentenhet efter.
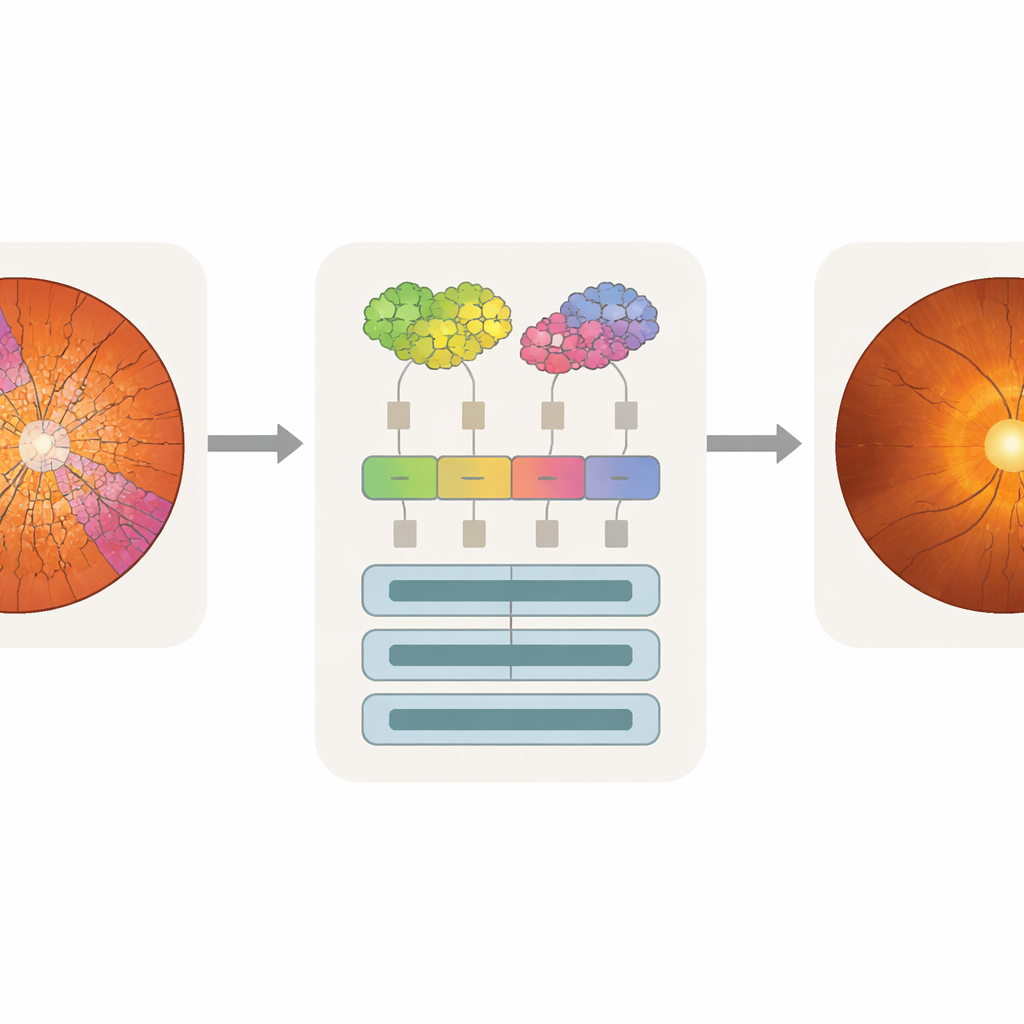
Få maskinens uppmärksamhet att matcha läkarens blick
Endast noggrannhet räcker inte för klinisk användning; läkare behöver också veta vilka delar av en bild som påverkade en modells beslut. Forskarna använde en analysteknik kallad attention rollout, som spårar hur mycket varje token bidrar till slutlig prediktion och omvandlar detta till en värmekarta över originalbilden. Eftersom SpxViT‑tokens följer diskens och koppens konturer, ligger dess uppmärksamhetskartor naturligt i linje med dessa regioner och undviker det blockiga rutmönster som ses i standardtransformers. Genom att lägga värmekartorna över experternas segmenteringar kunde teamet beräkna hur mycket uppmärksamhet som landade på koppen, disken eller bakgrunden. Superpixelmodellerna, särskilt SpxViT_var, koncentrerade större delen av sin uppmärksamhet på disken och koppen samtidigt som de i stor utsträckning ignorerade resten av retinan. En glaukomspecialist betygsatte också exempelbilder visuellt och fann att de från SpxViT_fix var lättast att tolka, med tydlig markering av de strukturer som används i verklig diagnostik.
Väga förtroende mot prestanda i AI för ögonvård
Studien visar att omformningen av hur bilder bryts ner i delar kan göra AI‑system för glaukomscreening mer transparenta utan att allvarligt offra noggrannheten. Medan den klassiska transformern slår den nya metoden i rena siffror, producerar SpxViT förklaringar som bättre matchar kliniskt resonemang genom att fokusera på optiska disken och koppen istället för spridda eller rutformade mönster. För vardagligt bruk kan denna avvägning vara värd det: en modell som läkare förstår och kan granska är mer sannolikt att bli accepterad och säkert integrerad i screeningprogram. Författarna menar att liknande superpixel‑baserade konstruktioner kan hjälpa till att föra tolkningsbar AI till andra medicinska bilduppgifter där det är lika viktigt att veta var modellen tittar som om den har rätt.
Citering: Hernández, J., Alayón, S., Sigut, J.F. et al. A novel superpixel based Vision Transformer for improving interpretability in glaucoma screening. Sci Rep 16, 10879 (2026). https://doi.org/10.1038/s41598-026-39730-x
Nyckelord: glaukomscreening, retinal avbildning, vision transformers, förklarbar AI, superpixlar