Clear Sky Science · nl
Een nieuwe superpixel-gebaseerde Vision Transformer om de interpretatie bij glaucoomscreening te verbeteren
Waarom oogscans en slimme systemen ertoe doen
Glaucoom is een sluipende oogziekte die het gezichtsvermogen kan aantasten voordat mensen symptomen opmerken. Artsen kunnen vroege waarschuwingssignalen herkennen in kleurenfoto’s van de achterkant van het oog, maar het zorgvuldig beoordelen van elk beeld kost veel tijd en vraagt om expertise. Kunstmatige intelligentie (AI) kan helpen, maar veel krachtige systemen gedragen zich als “black boxes” en geven weinig inzicht in hoe zij tot een oordeel komen. Deze studie introduceert een nieuwe AI-aanpak die probeert hoge nauwkeurigheid te behouden terwijl de redenering voor oogspecialisten gemakkelijker zichtbaar en betrouwbaarder wordt.
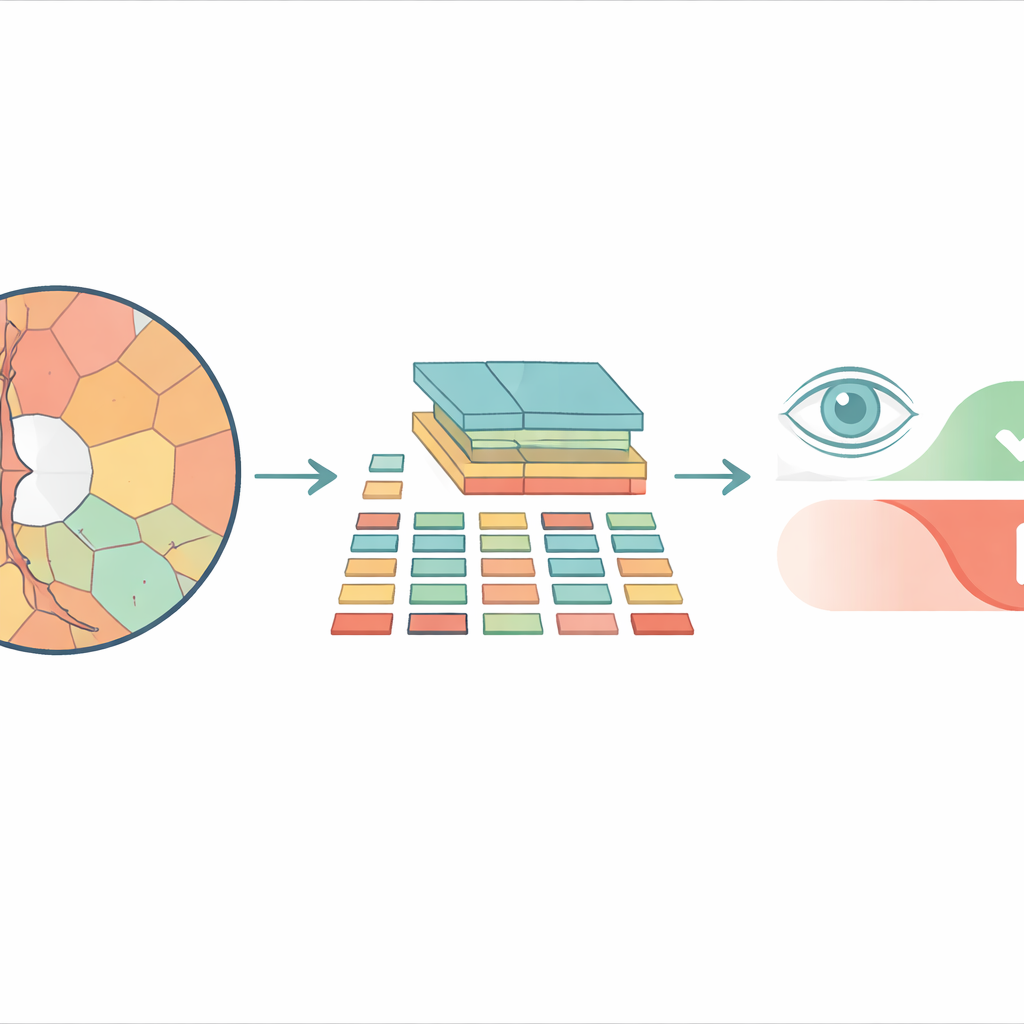
Van vierkante tegels naar natuurlijkere regio’s
De meeste moderne beeldanalyzesystemen op basis van vision transformers delen een afbeelding eerst op in een schaakbord van identieke vierkante tegels voordat ze deze verwerken. Dat werkt misschien goed voor alledaagse foto’s, maar het negeert hoe echte structuren in het oog zijn gevormd. De optische schijf en de binnenste depressie, de cup, hebben gebogen, onregelmatige omtrekken, en het forceren van die structuren in starre vierkanten mengt belangrijke en onbelangrijke details. De onderzoekers gebruiken in plaats daarvan “superpixels” — groepen aangrenzende pixels met vergelijkbare kleur of textuur — om het retinale beeld in stukken te snijden die volgen wat er anatomisch echt is. Deze superpixels worden vervolgens de basiseenheden, of “tokens”, die de transformer analyseert.
Een nieuwe manier om beelden aan transformers te voeden
Het voorgestelde model, Superpixel‑based Vision Transformer (SpxViT) genoemd, laat de interne werking van een standaard vision transformer grotendeels ongemoeid en richt zich op het herontwerpen van de voorverwerking. Voordat de afbeelding de transformer bereikt, verdeelt een bestaand algoritme (SLIC) deze in 196 superpixels, wat ongeveer overeenkomt met het aantal tegels dat wordt gebruikt in een gebruikelijk basismodel genaamd ViT‑B/16. Elke onregelmatige regio wordt omgezet in een numerieke beschrijving met vaste lengte zodat ze net als een normale tegel behandeld kan worden. Er worden twee varianten getest: één met een vaste instelling die natuurlijkere vormen bevoordeelt (SpxViT_fix) en een andere die deze instelling per afbeelding aanpast om altijd precies 196 regio’s te produceren (SpxViT_var). Afgezien van deze tokenisatie stap zijn de transformerlagen en het trainingsproces hetzelfde als in het klassieke model, wat een eerlijke vergelijking mogelijk maakt.
Getest op echte oogbeelden
Het team evalueerde hun methode op 739 retinale foto’s uit een openbare database en een ziekenhuiscollectie, waarbij elke afbeelding door glaucoomexperts was gelabeld. Specialisten tekenden ook de grenzen van de optische schijf en cup na, waarmee gedetailleerde kaarten van de klinisch belangrijkste structuren ontstonden. Meerdere transformer‑gebaseerde systemen werden vanaf nul getraind en vergeleken: de standaard ViT‑B/16 met vierkante tegels, een ander superpixel‑ontwerp uit eerder werk, en de twee SpxViT‑versies. De prestaties werden gemeten met gangbare diagnostische scores die een balans vinden tussen hoe goed een model zieke ogen detecteert en gezonde ogen correct afwijst. De klassieke ViT‑B/16 behaalde de beste totale nauwkeurigheid, maar SpxViT_var kwam er zeer dicht bij en bleef minder dan één procentpunt achter.
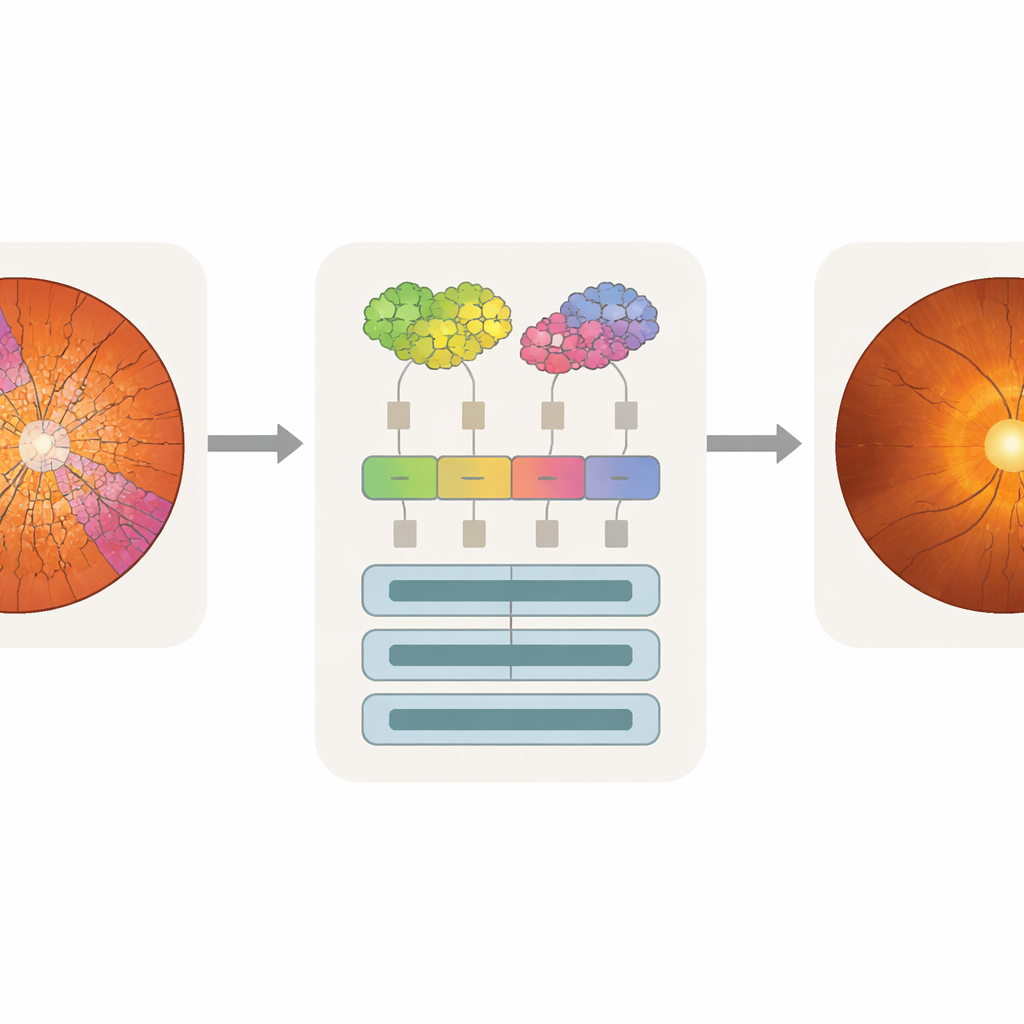
De aandacht van de machine laten overeenkomen met het oog van de arts
Nauwkeurigheid alleen is niet voldoende voor klinisch gebruik; artsen moeten ook weten welke delen van een afbeelding een modelbeslissing hebben beïnvloed. De onderzoekers gebruikten een analysetechniek genaamd attention rollout, die in kaart brengt hoeveel elk token bijdraagt aan de uiteindelijke voorspelling en dit omzet in een warmtekaart over de originele afbeelding. Omdat SpxViT‑tokens de contouren van schijf en cup volgen, sluiten de aandachtkaarten van dit model natuurlijker aan op die regio’s en vermijden ze het blokkerige rasterpatroon dat bij standaard transformers te zien is. Door de warmtekaarten over de expertssegmentaties heen te leggen, kon het team berekenen hoeveel aandacht op de cup, de schijf of de achtergrond viel. De superpixelmodellen, vooral SpxViT_var, concentreerden het grootste deel van hun aandacht op de schijf en cup, terwijl ze de rest van het netvlies grotendeels negeerden. Een glaucoomspecialist beoordeelde ook voorbeeldkaarten visueel en vond die van SpxViT_fix het gemakkelijkst te interpreteren, met duidelijke markering van de structuren die in de klinische diagnostiek gebruikt worden.
Vertrouwen en prestaties in AI voor oogzorg in balans brengen
De studie laat zien dat het hervormen van de manier waarop beelden in stukjes worden verdeeld AI‑systemen voor glaucoomscreening transparanter kan maken zonder de nauwkeurigheid ernstig te schaden. Hoewel de klassieke transformer in zuivere cijfers het nieuwe model iets voorbijstreeft, produceert SpxViT verklaringen die beter overeenkomen met klinische redenering doordat het zich richt op de optische schijf en cup in plaats van op verspreide of rasterachtige patronen. Voor dagelijks gebruik kan deze afweging de moeite waard zijn: een model dat artsen kunnen begrijpen en bevragen, wordt waarschijnlijker geadopteerd en veilig in screeningsprogramma’s geïntegreerd. De auteurs stellen dat vergelijkbare superpixel‑gebaseerde ontwerpen interpreteerbare AI kunnen bevorderen in andere medische beeldvormingstaken waarin weten waar het model kijkt net zo belangrijk is als of het gelijk heeft.
Bronvermelding: Hernández, J., Alayón, S., Sigut, J.F. et al. A novel superpixel based Vision Transformer for improving interpretability in glaucoma screening. Sci Rep 16, 10879 (2026). https://doi.org/10.1038/s41598-026-39730-x
Trefwoorden: glaucoomscreening, retinale beeldvorming, vision transformers, verklaarbare AI, superpixels