Clear Sky Science · ru
Новый суперпиксельный Vision Transformer для повышения интерпретируемости при скрининге глаукомы
Почему снимки глаз и «умные» машины важны
Глаукома — это «тихое» заболевание глаза, которое может лишить зрения ещё до появления заметных симптомов. Врачи способны обнаружить ранние признаки по цветным фотографиям задней части глаза, но тщательный разбор каждого изображения занимает много времени и требует опыта. Искусственный интеллект (ИИ) может помочь, однако многие мощные системы ведут себя как «чёрные ящики», давая мало понимания того, как они приходят к выводу. В этом исследовании предложен новый подход, который стремится сохранить высокую точность и одновременно сделать рассуждения модели более понятными и доверительными для офтальмологов.
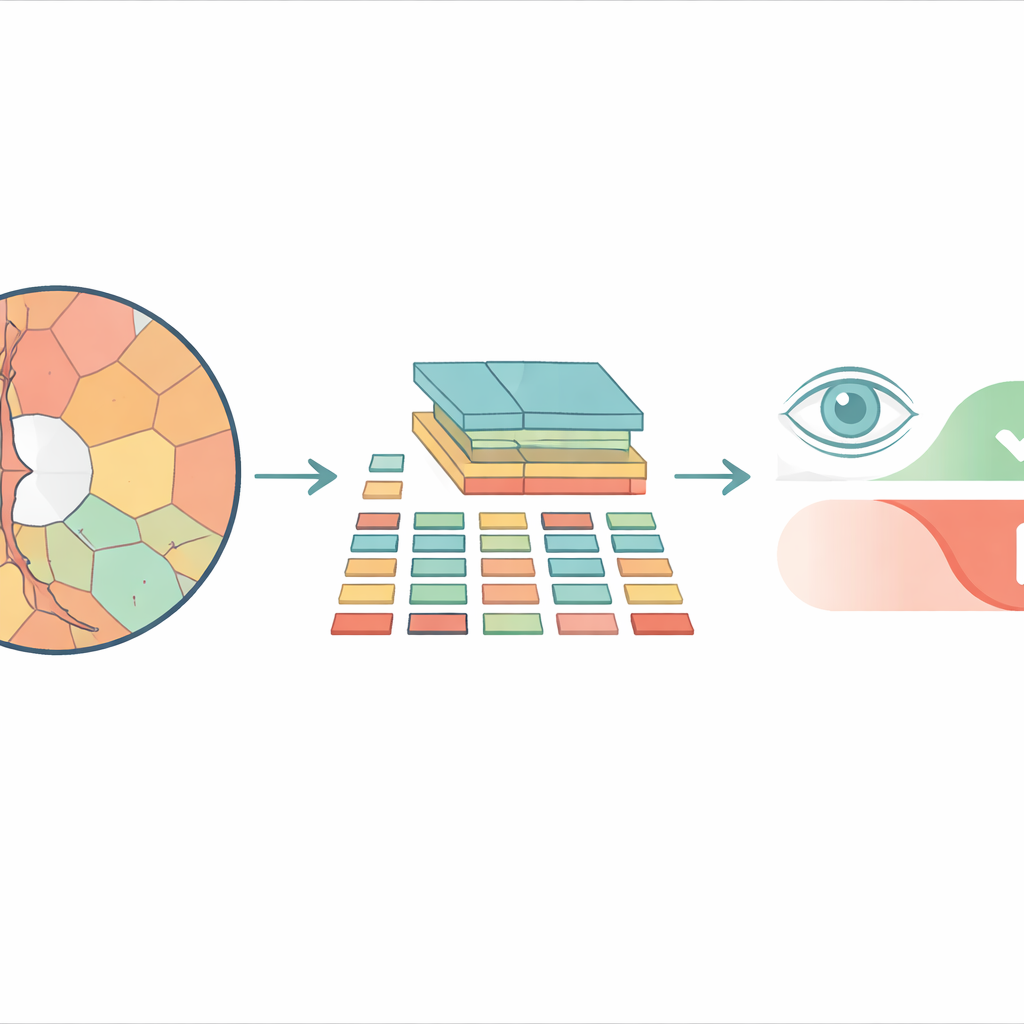
От квадратных плиток к более естественным областям
Большинство современных систем анализа изображений на основе vision transformers разбивают картинку на шахматку одинаковых квадратных плиток перед обработкой. Для обычных фото это может сработать, но такой подход игнорирует фактическую форму структур в глазу. Диск зрительного нерва и внутренняя воронка — «чашка» — имеют изогнутые, неправильные контуры, и принудительная разбивка на жесткие квадраты смешивает важные и неважные детали. Исследователи вместо этого используют «суперпиксели» — группы соседних пикселов с похожим цветом или текстурой — которые делят изображение сетчатки на фрагменты, соответствующие реальным анатомическим границам. Эти суперпиксели затем становятся базовыми единицами, или «токенами», которые анализирует трансформер.
Новый способ подачи изображений в трансформеры
Предложенная модель, названная Superpixel‑based Vision Transformer (SpxViT), сохраняет внутреннюю архитектуру стандартного vision transformer почти без изменений и сосредоточена на переработке фронт‑энда. До попадания в трансформер существующий алгоритм (SLIC) делит изображение на 196 суперпикселей, что примерно соответствует числу плиток в распространённой базовой модели ViT‑B/16. Каждая неправильной формы область преобразуется в числовое описание фиксированной длины, чтобы с ней можно было обращаться как с обычной плиткой. Протестированы два варианта: один использует постоянные настройки для получения более естественных форм (SpxViT_fix), другой подстраивает настройки для каждого изображения, чтобы всегда получать ровно 196 областей (SpxViT_var). За исключением шага токенизации, слои трансформера и процедура обучения совпадают с классической моделью, что обеспечивает корректное сравнение.
Тестирование на реальных изображениях глаз
Команда оценила метод на 739 снимках сетчатки из публичной базы данных и коллекции больницы; каждое изображение было помечено экспертами по глаукоме. Специалисты также обвели границы диска и чашки, создав детализированные карты самых клинически значимых структур. Было обучено и сравнилось несколько систем на основе трансформеров: стандартный ViT‑B/16 с квадратными плитками, другая суперпиксельная конструкция из предыдущих работ и два варианта SpxViT. Производительность измеряли с помощью общепринятых диагностических метрик, учитывающих способность модели обнаруживать больные глаза и правильно отвергать здоровые. Классический ViT‑B/16 показал наилучшую общую точность, но SpxViT_var оказался совсем рядом, уступая менее чем на один процентный пункт.
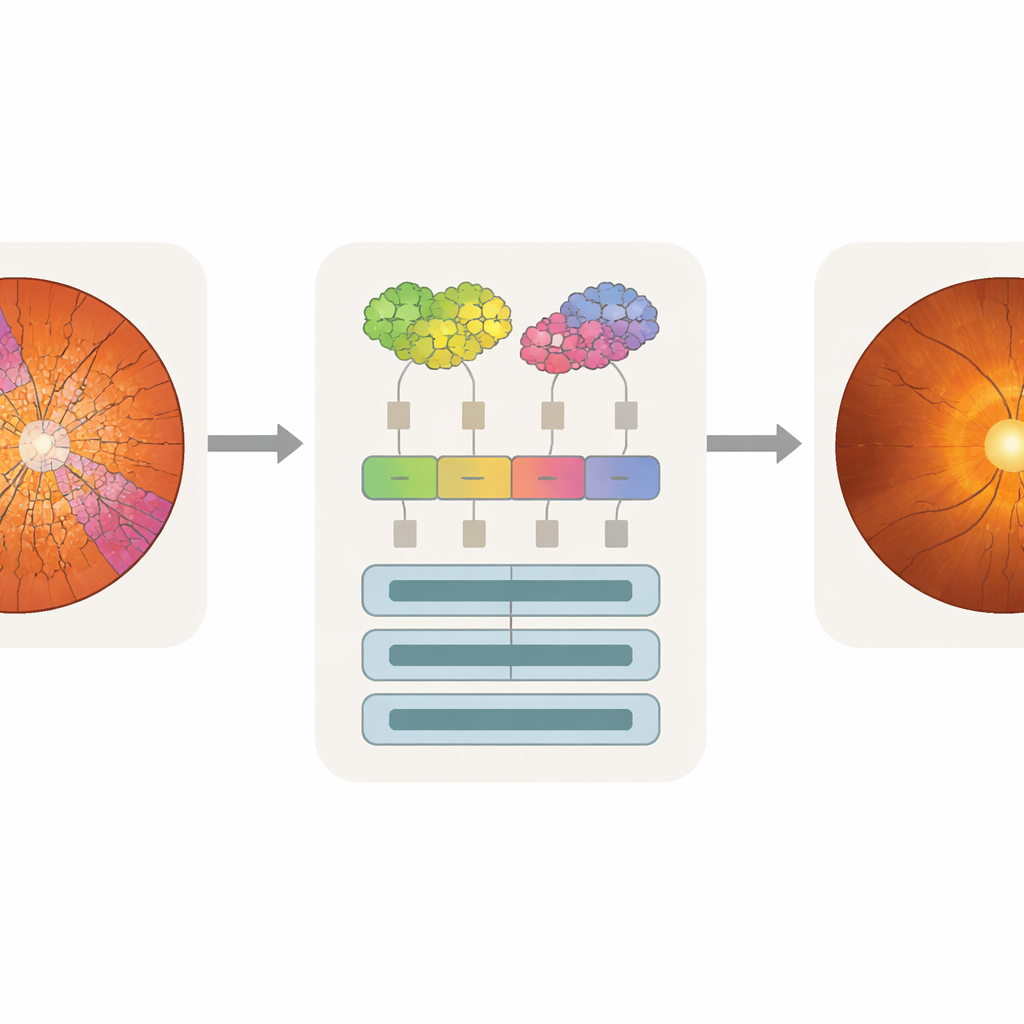
Сделать внимание машины похожим на взгляд врача
Одна только точность недостаточна для клинического применения; врачам также важно знать, какие части изображения повлияли на решение модели. Исследователи использовали метод анализа attention rollout, который отслеживает вклад каждого токена в финальный прогноз и преобразует это в тепловую карту поверх исходного изображения. Поскольку токены SpxViT следуют контурам диска и чашки, их карты внимания естественно выравниваются по этим регионам и избегают «блоковой» сетки, характерной для стандартных трансформеров. Накладывая тепловые карты на экспертные сегментации, команда подсчитывала, какая доля внимания попадала на чашку, на диск или на фон. Модели на основе суперпикселей, особенно SpxViT_var, сосредотачивали большую часть внимания на диске и чашке, в то время как большую часть сетчатки игнорировали. Специалист по глаукоме также визуально оценил примерные карты и признал карты SpxViT_fix самыми удобными для интерпретации, с чётким выделением структур, используемых в реальной диагностике.
Баланс доверия и эффективности в ИИ для офтальмологии
Исследование показывает, что изменение способа разбиения изображения на фрагменты может сделать ИИ‑системы для скрининга глаукомы более прозрачными без серьёзной потери точности. Хотя классический трансформер обходит новую методику по чистым числам, SpxViT генерирует объяснения, лучше согласующиеся с клинической логикой, фокусируясь на диске и чашке вместо разбросанных или сеткообразных паттернов. В повседневной практике такой компромисс может оказаться оправданным: модель, которую врачи понимают и могут подвергнуть критике, с большей вероятностью будет принята и безопасно интегрирована в программы скрининга. Авторы утверждают, что подобные суперпиксельные конструкции могли бы помочь внедрить интерпретируемый ИИ и в другие задачи медицинской визуализации, где важно не только то, прав ли модель, но и куда она смотрит.
Цитирование: Hernández, J., Alayón, S., Sigut, J.F. et al. A novel superpixel based Vision Transformer for improving interpretability in glaucoma screening. Sci Rep 16, 10879 (2026). https://doi.org/10.1038/s41598-026-39730-x
Ключевые слова: скрининг глаукомы, изображения сетчатки, vision transformers, объяснимая ИИ, суперпиксели